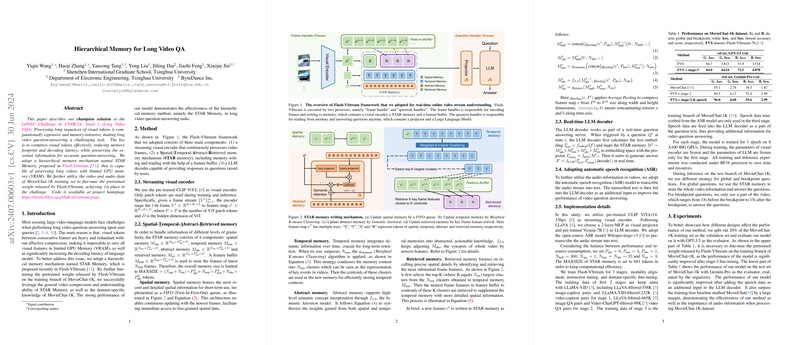
Overview of the Hierarchical Memory for Long Video QA
The paper "Hierarchical Memory for Long Video QA" addresses the complex challenge of long video question-answering (QA) by leveraging a hierarchical memory mechanism known as STAR Memory. The authors focus on overcoming the computational and memory constraints posed by long video sequences, emphasizing the need for effective compression of visual tokens to facilitate accurate QA. This paper reports success in the LOVEU Challenge at CVPR'24, Track 1, by demonstrating a robust solution for processing extended video content with limited GPU memory.
Key Methodological Contributions
At the core of this work is the STAR Memory architecture, integrated within the Flash-VStream framework, which allows for efficient handling of long video sequences. The framework comprises three main components:
- Streaming Visual Encoder: Utilizing a pre-trained CLIP ViT-L model to transform frames into feature maps, allowing continuous video processing.
- Hierarchical STAR Memory:
- Spatial Memory: Preserves detailed, recently viewed spatial information using a FIFO queue.
- Temporal Memory: Employs Weighted K-Means Clustering to maintain key dynamic elements over time.
- Abstract Memory: Uses Semantic Attention to distill high-level semantic concepts from spatial and temporal contexts.
- Retrieved Memory: Focuses on specific frame details by selecting the most representative features.
- Real-time LLM Decoder: Acts as a question-answering server interpreter, incorporating automatic transcription from audio to text using an ASR model, providing enhanced audio-visual content understanding.
Experimental Results and Implications
The experimental evaluation, conducted on the MovieChat-1K dataset, reveals significant performance improvements through the hierarchical memory structure and additional audio data. Notably, the fine-tuning of the framework on MovieChat-1K transitions into considerable increases in both accuracy and evaluation scores over baseline methods such as MovieChat, highlighting the model's proficiency in long video QA tasks.
The inclusion of speech data as a textual input leads to further advancements, demonstrating the critical role of audio information in concert with video data for comprehensive long video comprehension. This success at the LOVEU Challenge underscores the method’s efficacy in practical, memory-restricted environments where handling complete visual content is challenging.
Future Research Directions
This work opens several avenues for future inquiries in video understanding. Prospective studies could explore further optimization of hierarchical memory mechanisms to enhance the scalability of models dealing with even longer video sequences. Investigating novel ways to integrate other modalities like textual annotations or subtitles could enrich the model's contextual understanding and QA capabilities. Additionally, deploying this framework in varied real-world settings could test its adaptability and suggest refinements to suit diverse applications in multimedia data analysis.
In summary, the utilization of a hierarchical memory framework, particularly STAR Memory, presents a promising advancement for efficiently navigating the intricacies of long video question-answering, with significant implications for both theoretical development and practical deployment in the field of AI and multimedia analytics.