- The paper shows that using TensorRT for DL model optimization on the NVIDIA Jetson Nano leads to significant inference speed-ups (up to 16.7×) in deep learning models.
- It employs a conversion pipeline from PyTorch to TensorRT and evaluates various architectures like MobileNet-V2 and ShuffleNet-V2 for enhanced edge performance.
- The study highlights that model architecture and computational metrics, such as FLOPS, impact optimization outcomes, offering insights for real-time AI on resource-constrained devices.
Benchmarking Deep Learning Models on NVIDIA Jetson Nano: An Empirical Investigation
Introduction
In recent years, the widespread adoption of deep learning (DL) models has revolutionized numerous applications, including computer vision. Despite their success, the deployment of these models on low-computational power and memory-constrained devices such as embedded systems and edge devices presents significant challenges. This paper examines DL model optimization for such devices, specifically the NVIDIA Jetson Nano. The study aims to quantify performance improvements in inference speed for image classification and video action detection through model optimization.
Methodology
The NVIDIA Jetson Nano, depicted below with its components and connectivity options, was employed to test the optimized DL models.
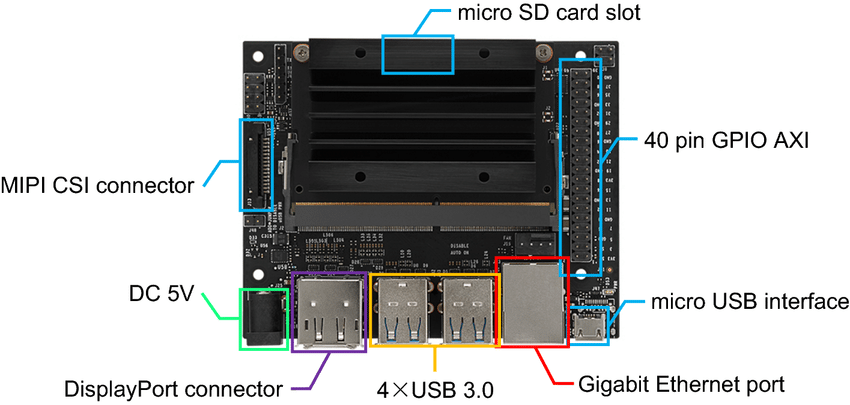
Figure 1: Layout of the NVIDIA Jetson Nano Developer Kit showcasing its key components and connectivity options.
The optimization process involves converting PyTorch models to TensorRT formats using the pipeline depicted below. This approach significantly enhances the inference speed on the Jetson Nano.
(Figure 2)
Figure 2: The PyTorch deep learning model optimization process for a NVIDIA Jetson Nano Edge Device using TensorRT.
The experimental setup features image classification models including well-known architectures such as AlexNet, VGG, ResNet, and MobileNet-V2. Additionally, custom models for human action recognition were developed and evaluated. The models underwent optimization employing TensorRT, where various techniques like layer and tensor fusion, and kernel auto-tuning were applied to achieve low latency and high throughput for inference.
(Figure 3)
Figure 3: Inference process of TensorRT engine on NVIDIA Jetson Nano.
Results and Discussion
The optimization achieved by utilizing TensorRT resulted in a substantial reduction in inference time, as documented in the paper. For instance, models such as ShuffleNet-V2 and MobileNet-V2 exhibited speed-ups of 13.6× and 16.7×, respectively, post-optimization. These results highlight the effectiveness of optimization techniques used to tailor models for specific hardware capabilities without compromising on computational performance.
(Figure 4)
Figure 4: Inference time speedup of the optimized models on NVIDIA Jetson Nano compared to their non-optimized baseline counterparts.
The observed trends indicate that models with lower FLOPS demonstrate a more pronounced enhancement in inference speed post-optimization. However, variations exist, such as with ResNet-V2, which suggests that architecture-specific optimizations impact the overall efficiency beyond simple computational metrics like FLOPS.
Conclusion
This study demonstrates that DL models optimized for edge devices, such as the NVIDIA Jetson Nano, can drastically reduce inference times by an average of 7.011× across both image classification and video action detection tasks. These optimizations are critical for enabling the deployment of advanced AI applications on resource-limited systems, addressing issues of latency and sustainability, and reducing the carbon footprint.
Future work should investigate additional optimization techniques, such as quantization-aware training and network pruning, to further enhance model efficiency. As AI continues to integrate into edge computing environments, the significance of optimizing DL models will only grow, ensuring scalable, high-performance solutions in various domains. For more detailed insights and code implementations, refer to the project's repository.