- The paper introduces a novel alignment framework that matches summary propositions with source document elements to reverse-engineer human summarization.
- It leverages both manual annotation and automated strategies, including crowdsourcing and SuperPAL, to create comprehensive MDS datasets.
- Baseline evaluations reveal improved salience and evidence detection, while challenges in proposition clustering highlight avenues for future research.
Summary-Source Alignments in Multi-Document Summarization
This essay discusses a systematic approach to multi-document summarization (MDS) through the alignment of summary-source propositions at a granular level. The paper presents methodologies for leveraging summary-source alignments to create datasets suitable for various subtasks involved in MDS, such as salience detection, proposition clustering, and evidence detection.
Introduction to Multi-Document Summarization (MDS)
MDS involves the consolidation of information across multiple documents to extract and synthesize essential points into a coherent summary. Traditional approaches often decomposed the summarization process into subtasks focusing on salience and redundancy detection followed by generation tasks. Recent advancements have motivated the extension of alignment techniques to proposition-level, which offers fine-grained insights into content relationships between source documents and summaries.

Figure 1: An example of proposition-level multi-document-based alignment. Aligned propositions are in the same color and formatting.
Fine-Grained Proposition-Level Alignments
In contrast to previous sentence-level alignments, proposition-level alignments offer precise matching between elements of summaries and their source documents. This paper introduces manual and automated strategies for generating accurate alignments, exploiting these alignments to derive multiple datasets addressing different MDS-related tasks. This novel approach allows for creating high-quality training, development, and test sets from existing datasets like Multi-News.
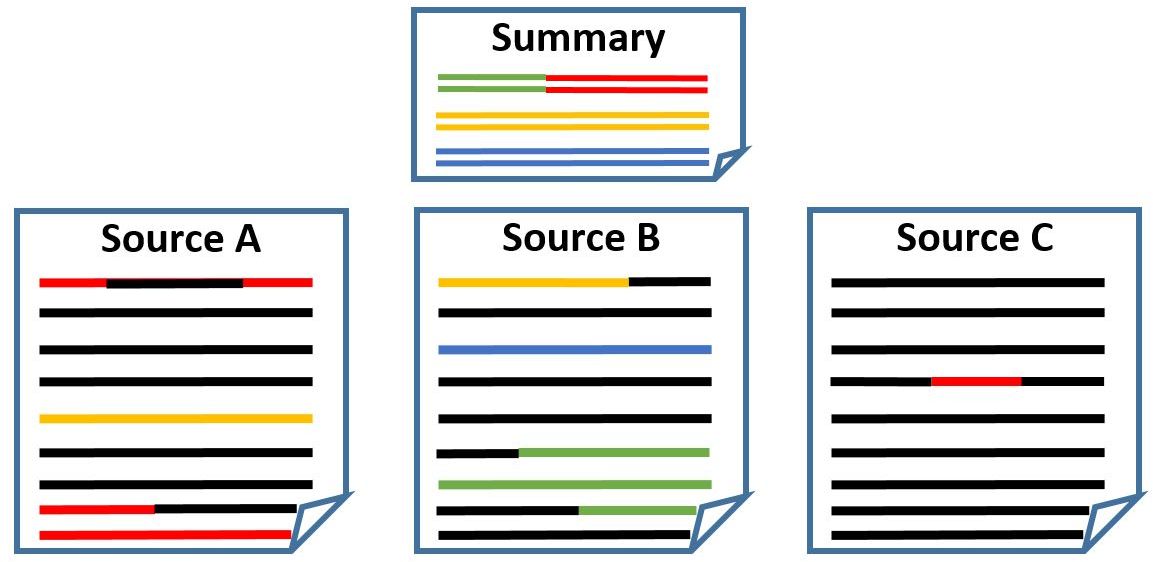


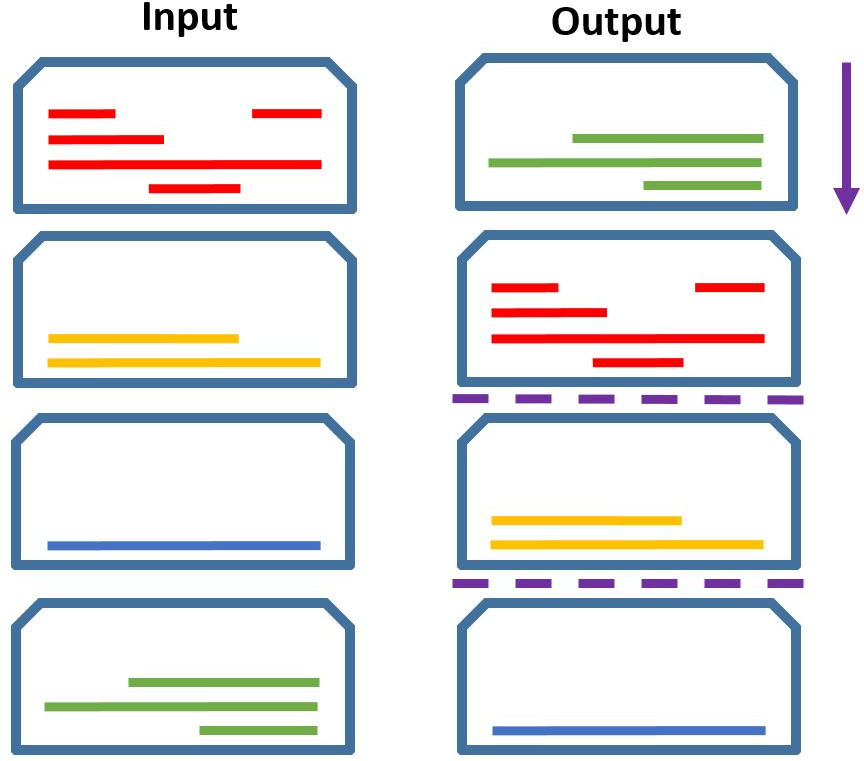
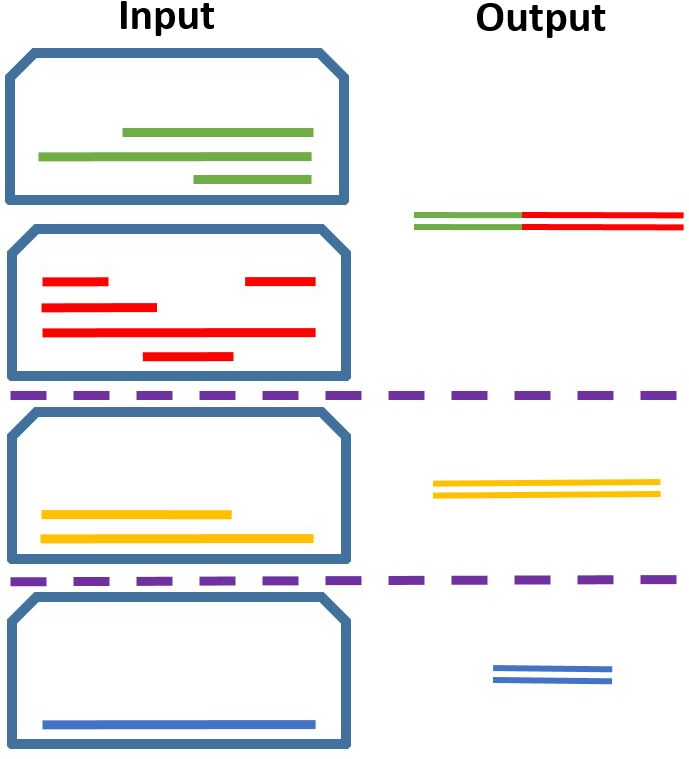
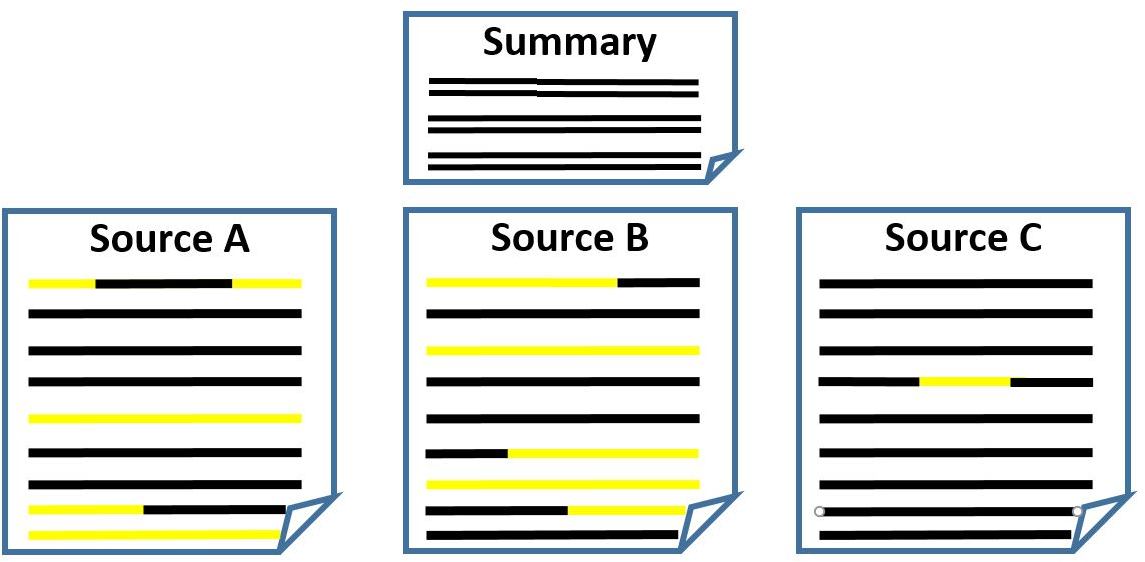
Figure 2: Deriving SPARK task datasets from our alignments, for a given document set (topic): (a) Alignments - aligned summary-source propositions are marked here by the same color; (b) Salience Detection - all aligned document propositions are to be selected; (c) Proposition Clustering - document propositions aligned with the same summary proposition are to be clustered; (d) Evidence Detection - a summary proposition is the input query, and the document propositions aligned with it are to be extracted as evidence; (e) Text Planning - document proposition clusters are to be grouped and ordered according to the summary sentence structure; (f) Sentence Fusion - document propositions aligning to the same summary sentence are to be fused to generate that sentence; (g) In-context Fusion - all document propositions, marked within the documents, are to be fused to generate the full summary.
Deriving Datasets for MDS Tasks
The alignment framework proposed in the paper supports the derivation of datasets for six distinct tasks: salience detection, proposition coreference clustering, evidence detection, text planning, sentence fusion, and in-context passage fusion. Each task is characterized by distinct goals but inherently interlinked through the proposition alignment mechanism. This approach essentially reverse-engineers the human summarization process, enriching the data suite with automatically derived large-scale datasets for training models on these tasks.
Methodology for Annotation and Dataset Collection
The paper outlines a rigorous methodology for manual and automatic annotation of alignments, leveraging crowdsourcing and advanced models to ensure high-quality alignments. Crowdsourcing processes are carefully controlled, ensuring that trained annotators produce reliable data points. The automatic extraction process employs models such as SuperPAL for large-scale dataset compilation, achieving high efficiency and accuracy.
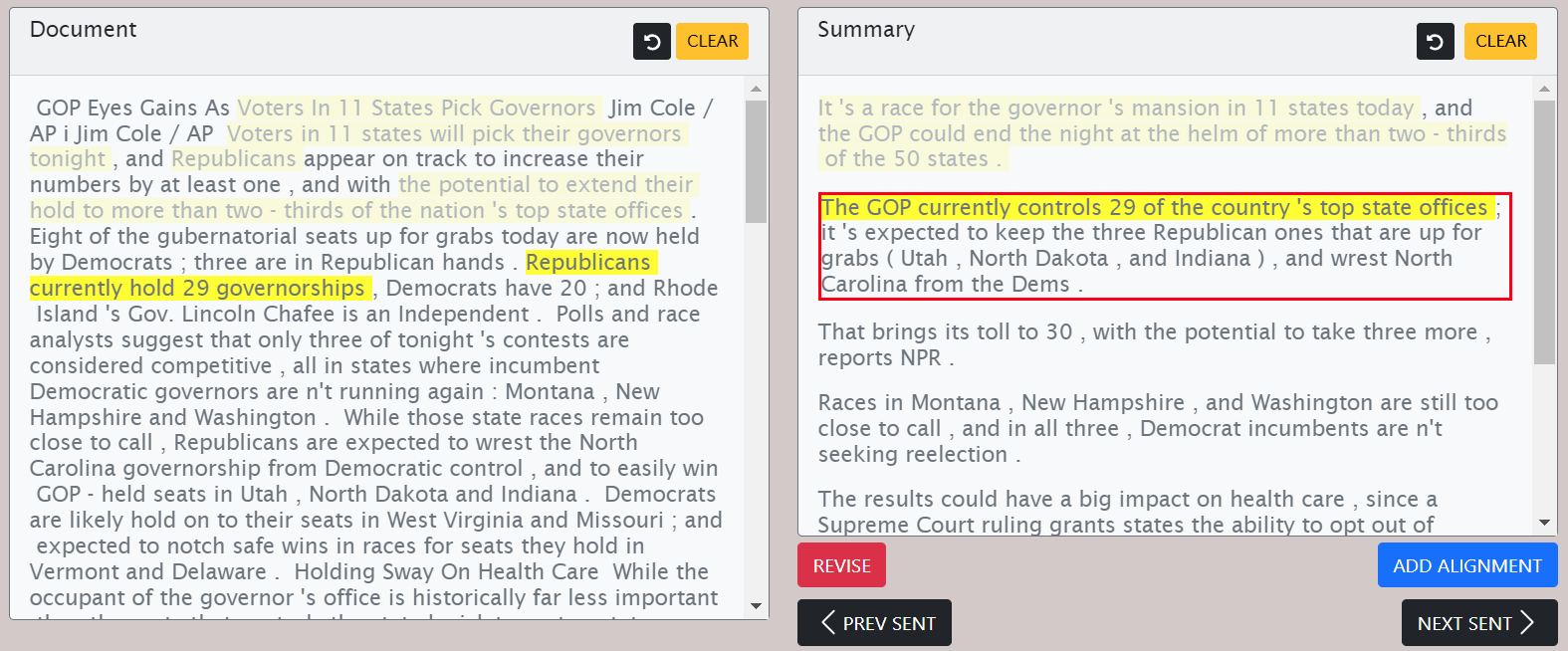
Figure 3: The alignment annotation interface. The annotator marks a span (proposition) in the summary (right) along with all matching spans in the current document (left). To minimize cognitive load, a summary is shown next to a single document at a time.
The paper evaluates several baseline models against the derived datasets, demonstrating the effectiveness of the approach. Finetuned models generally outperform GPT counterparts except in the case of proposition clustering, indicating the potential for improvements in model training and in-context learning examples. Results are benchmarked using token-level F1 scores and lexical metrics like ROUGE, showing promising directions for future research endeavors.
Discussion on Limitations and Dataset Characteristics
The paper thoroughly discusses the inherent characteristics of the Multi-News dataset—such as redundancy levels and abstractiveness—highlighting challenges like low inter-document redundancy and uneven distribution of information essential for summarization. These insights underline the importance of proposition-level alignments and their impact on quality summarization.
Conclusion
This work accentuates the significance of summary-source proposition alignments in expanding the capabilities of MDS by unveiling datasets for a plethora of subtasks essential to the summarization pipeline. The approach facilitates high-quality data collection from MDS datasets, setting foundations for future advancements in summarization research. It provides researchers with tools and datasets to explore the nuances of multi-document content synthesis.
By systematically addressing alignment strategies, the paper contributes practical applications in real-world summarization contexts, promoting enhanced performance in both stand-alone tasks and within integrated MDS systems. Readers are encouraged to explore the datasets and models provided to further the field of AI-driven document summarization.