- The paper introduces innovative LLM-based approaches that increase topic coherence by up to 40% compared to traditional methods.
- It compares parallel and sequential prompting, demonstrating that parallel processing more effectively merges topics in short texts.
- The study highlights trade-offs between high topic precision and lower document coverage, with marginal factual inconsistencies noted.
Comprehensive Evaluation of LLMs for Topic Modeling
Introduction
The paper "Comprehensive Evaluation of LLMs for Topic Modeling" (2406.00697) presents an innovative approach to topic modeling, a field historically challenged by the limitations of conventional models in handling short texts. This research leverages LLMs to overcome the inherent data sparsity in short text documents by using their contextual semantic understanding. Conventional topic models, such as Latent Dirichlet Allocation (LDA), rely predominantly on word co-occurrence, which is less effective with shorter texts. This study explores two methodologies—parallel prompting and sequential prompting—to integrate LLMs effectively in the field of topic modeling.
Methodology
The challenge of input length restrictions in LLMs is addressed by splitting a document set into smaller subsets. In parallel prompting, subsets are processed simultaneously with each subset's topics inferred and subsequently merged to represent the document set's topics as a whole. This method uses specific prompts for both initial topic modeling and merging identified topics from subsets.

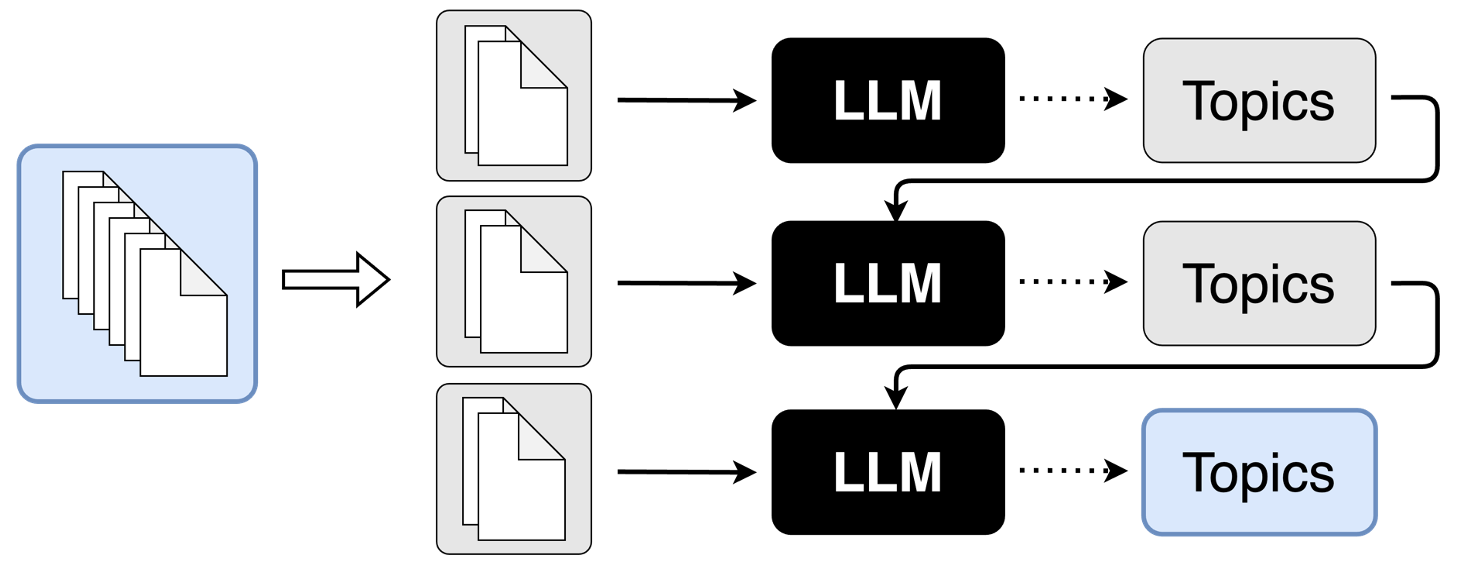
Figure 1: Illustration of topic modeling with LLMs through (a) parallel prompting and (b) sequential prompting.
In contrast, sequential prompting processes subsets iteratively, utilizing information from previously processed subsets to refine topic identification continually. This method's strength lies in its iterative refinement, theoretically allowing for evolving topic accuracy as more subset data becomes available.
Evaluation and Results
The evaluation of the proposed methodologies is conducted utilizing three datasets: GoogleNewsT, Tweet, and StackOverflow. Key metrics for assessment include topic coherence (Cv), topic diversity (TU), document coverage (DC), and factuality (Fa).
Topic Quality: The results demonstrated that the LLM-based methods, particularly those using GPT-4, significantly increased topic coherence, achieving up to a 40% improvement over existing models in certain settings. For instance, on the GoogleNewsT dataset, coherence scores improved dramatically from previous benchmarks, showcasing the efficacy of LLMs in understanding semantic contexts better than traditional models.
Document Coverage: Although the LLM approaches showed exceptional coherence, they exhibited lower document coverage compared to leading baseline models which indicates that while LLMs excel in topic precision, they may sacrifice breadth, covering fewer documents in the dataset.
Factuality: The factuality metric highlights the potential issue of "hallucinated topics" that do not directly relate to the input text. The study found that while LLMs displayed lower factuality scores, the deviation was marginal, and most hallucinated instances consisted of semantically related terms, rather than entirely irrelevant topics.
Discussion
The findings suggest that LLMs, particularly GPT-4, can redefine topic modeling for short texts by deciphering high-quality, coherent topics with a minimal instance of hallucination. Notably, the parallel prompting approach outperformed sequential prompting in terms of both coherence and document coverage, which underscores the efficacy of concurrent processing and subsequent topic integration.
Conclusion
This comprehensive study delineates the capabilities of LLMs in the domain of topic modeling for short texts, revealing significant enhancements in topic coherence and diversity. While challenges remain, particularly in ensuring comprehensive document coverage and minimizing factual inconsistencies, the advancements introduced by LLMs present promising opportunities for future research. Future directions could involve refining the balance between document coverage and coherence, as well as extending these approaches to large-scale datasets and multilingual document sets.