Reinforcing Language Agents via Policy Optimization with Action Decomposition
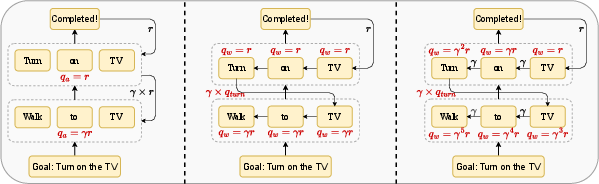
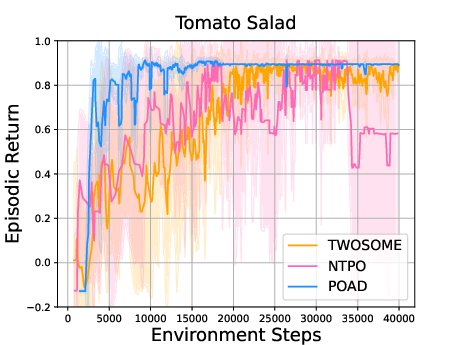
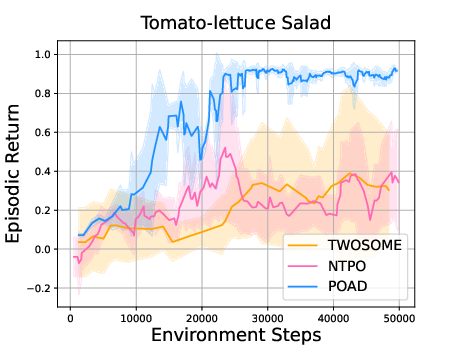
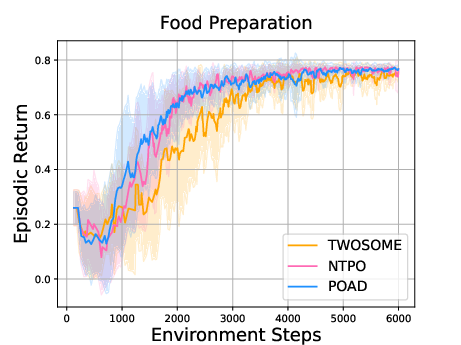
Abstract: LLMs as intelligent agents push the boundaries of sequential decision-making agents but struggle with limited knowledge of environmental dynamics and exponentially huge action space. Recent efforts like GLAM and TWOSOME manually constrain the action space to a restricted subset and employ reinforcement learning to align agents' knowledge with specific environments. However, they overlook fine-grained credit assignments for intra-action tokens, which is essential for efficient language agent optimization, and rely on human's prior knowledge to restrict action space. This paper proposes decomposing language agent optimization from the action level to the token level, offering finer supervision for each intra-action token and manageable optimization complexity in environments with unrestricted action spaces. Beginning with the simplification of flattening all actions, we theoretically explore the discrepancies between action-level optimization and this naive token-level optimization. We then derive the Bellman backup with Action Decomposition (BAD) to integrate credit assignments for both intra-action and inter-action tokens, effectively eliminating the discrepancies. Implementing BAD within the PPO algorithm, we introduce Policy Optimization with Action Decomposition (POAD). POAD benefits from a finer-grained credit assignment process and lower optimization complexity, leading to enhanced learning efficiency and generalization abilities in aligning language agents with interactive environments. We validate POAD across diverse testbeds, with results affirming the advantages of our approach and the correctness of our theoretical analysis.
- Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Chessgpt: Bridging policy learning and language modeling. Advances in Neural Information Processing Systems, 36, 2024.
- Grounding large language models in interactive environments with online reinforcement learning. In International Conference on Machine Learning, pages 3676–3713. PMLR, 2023.
- True knowledge comes from practice: Aligning large language models with embodied environments via reinforcement learning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=hILVmJ4Uvu.
- Alphazero-like tree-search can guide large language model decoding and training. arXiv preprint arXiv:2309.17179, 2023.
- Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
- Reinforcement learning: An introduction. MIT press, 2018.
- Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024a.
- From r to q* : Your language model is secretly a q-function. arXiv preprint arXiv:2404.12358, 2024b.
- Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
- Markov decision processes. Markov Decision Processes in Artificial Intelligence, pages 1–38, 2013.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017a.
- Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022.
- Inner monologue: Embodied reasoning through planning with language models. In 6th Annual Conference on Robot Learning, 2022.
- Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768, 2020.
- Agentbench: Evaluating llms as agents. In The Twelfth International Conference on Learning Representations, 2023.
- React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2022.
- Self-refine: Iterative refinement with self-feedback. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Reflexion: language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084–15097, 2021.
- Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems, 34:1273–1286, 2021.
- Multi-agent reinforcement learning is a sequence modeling problem. Advances in Neural Information Processing Systems, 35:16509–16521, 2022a.
- A generalist agent. arXiv preprint arXiv:2205.06175, 2022.
- On realization of intelligent decision-making in the real world: A foundation decision model perspective. arXiv preprint arXiv:2212.12669, 2022b.
- Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. In Conference on Robot Learning, pages 3909–3928. PMLR, 2023.
- Settling the variance of multi-agent policy gradients. Advances in Neural Information Processing Systems, 34:13458–13470, 2021a.
- Trust region policy optimisation in multi-agent reinforcement learning. In International Conference on Learning Representations, 2021b.
- Reinforcement learning and markov decision processes. In Reinforcement learning: State-of-the-art, pages 3–42. Springer, 2012.
- Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
- Pangu-agent: A fine-tunable generalist agent with structured reasoning. arXiv preprint arXiv:2312.14878, 2023.
- Improving large language models via fine-grained reinforcement learning with minimum editing constraint. arXiv preprint arXiv:2401.06081, 2024.
- The pitfalls of next-token prediction. arXiv preprint arXiv:2403.06963, 2024.
- Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- Reinforcement learning through asynchronous advantage actor-critic on a gpu. arXiv preprint arXiv:1611.06256, 2016.
- Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015.
- Actor-critic algorithms. Advances in neural information processing systems, 12, 1999.
- Equivalence between policy gradients and soft q-learning. arXiv preprint arXiv:1704.06440, 2017b.
- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018.
- High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015.
- Llama 2: Open foundation and fine-tuned chat models, 2023.
- Code llama: Open foundation models for code, 2023.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Openml: networked science in machine learning. ACM SIGKDD Explorations Newsletter, 15(2):49–60, 2014.
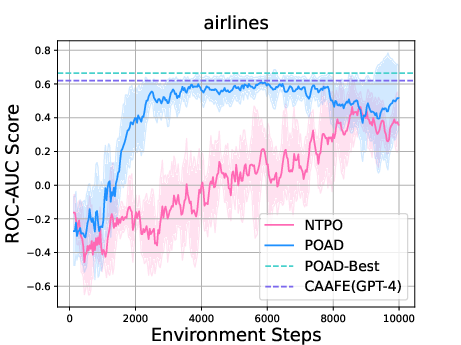
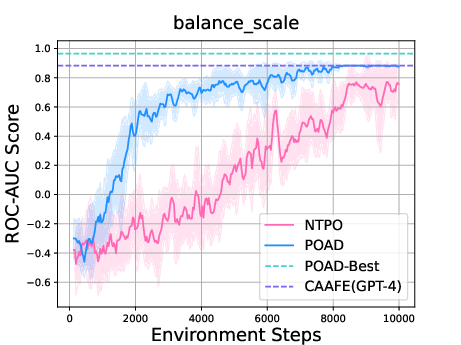
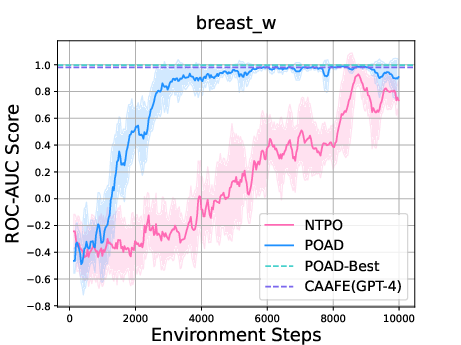
- Sarang Narkhede. Understanding auc-roc curve. Towards data science, 26(1):220–227, 2018.
- Large language models for automated data science: Introducing caafe for context-aware automated feature engineering. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Accounting for variance in machine learning benchmarks. Proceedings of Machine Learning and Systems, 3:747–769, 2021.
- A framework for few-shot language model evaluation. Version v0. 0.1. Sept, page 8, 2021.
- Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024.
- Generalized hindsight for reinforcement learning. Advances in neural information processing systems, 33:7754–7767, 2020.
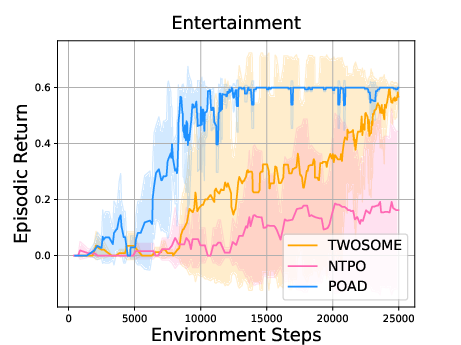
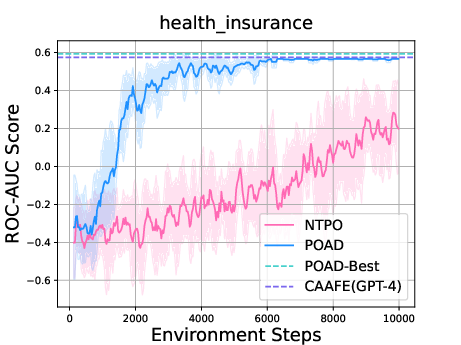
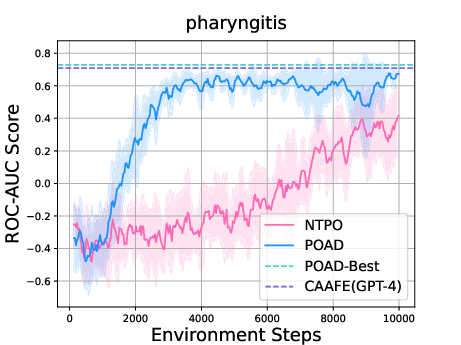
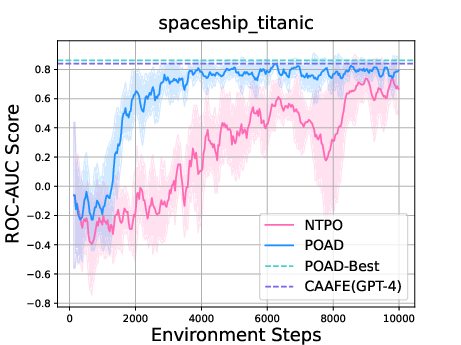
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.