MotionCraft: Physics-based Zero-Shot Video Generation
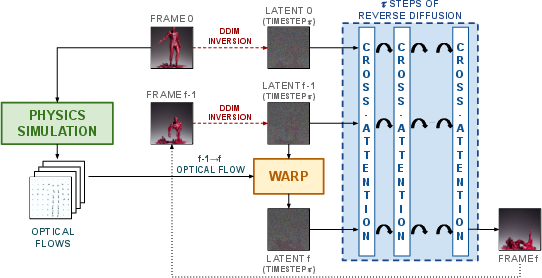
Abstract: Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision. While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space. We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics. Project page: https://mezzelfo.github.io/MotionCraft/
- Latentwarp: Consistent diffusion latents for zero-shot video-to-video translation. arXiv preprint arXiv:2311.00353, 2023.
- A review of video generation approaches. In 2020 International Conference on Power, Instrumentation, Control and Computing (PICC), pages 1–5, 2020. doi: 10.1109/PICC51425.2020.9362485.
- Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023.
- Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023.
- Video generation models as world simulators. 2024. URL https://openai.com/research/video-generation-models-as-world-simulators.
- Generative rendering: Controllable 4d-guided video generation with 2d diffusion models. arXiv preprint arXiv:2312.01409, 2023.
- Pix2video: Video editing using image diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23206–23217, 2023.
- Diffusion self-guidance for controllable image generation. Advances in Neural Information Processing Systems, 36:16222–16239, 2023.
- Joël Foramitti. Agentpy: A package for agent-based modeling in python. Journal of Open Source Software, 6(62):3065, 2021.
- Motion guidance: Diffusion-based image editing with differentiable motion estimators. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WIAO4vbnNV.
- Tokenflow: Consistent diffusion features for consistent video editing. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=lKK50q2MtV.
- Msu video frame interpolation benchmark dataset, 2022. URL https://videoprocessing.ai/benchmarks/video-frame-interpolation-dataset.html.
- Prompt-to-prompt image editing with cross-attention control. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=_CDixzkzeyb.
- Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URL https://openreview.net/forum?id=qw8AKxfYbI.
- Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022a.
- Video diffusion models. Advances in Neural Information Processing Systems, 35:8633–8646, 2022b.
- Learning to control pdes with differentiable physics. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HyeSin4FPB.
- Itseez. Open source computer vision library. https://github.com/itseez/opencv, 2015.
- Text2video-zero: Text-to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023.
- Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6038–6047, 2023.
- Conditional image-to-video generation with latent flow diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18444–18455, 2023.
- Craig W Reynolds. Flocks, herds and schools: A distributed behavioral model. In Proceedings of the 14th annual conference on Computer graphics and interactive techniques, pages 25–34, 1987.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015.
- Make-a-video: Text-to-video generation without text-video data. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=nJfylDvgzlq.
- Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- Denoising Diffusion Implicit Models. In International Conference on Learning Representations, 2020a.
- Generative modeling by estimating gradients of the data distribution. Advances in Neural Information Processing Systems, 32, 2019.
- Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2020b.
- Raft: Recurrent all-pairs field transforms for optical flow. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 402–419. Springer, 2020.
- Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7623–7633, 2023.
- Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

