Diffusion for World Modeling: Visual Details Matter in Atari
Abstract: World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. We further demonstrate that DIAMOND's diffusion world model can stand alone as an interactive neural game engine by training on static Counter-Strike: Global Offensive gameplay. To foster future research on diffusion for world modeling, we release our code, agents, videos and playable world models at https://diamond-wm.github.io.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to train game-playing AIs using “world models” and a kind of image generator called a diffusion model. The idea is to let the AI learn mostly by imagining the game world rather than always playing in the real game. The authors build an agent named “diamond” that learns inside a diffusion-based world model and show it can play Atari games very well, especially when small visual details matter.
What questions does the paper ask?
- Can we make world models that keep important visual details (like tiny objects or exact scores) so the AI makes better decisions?
- Are diffusion models, which are great at generating realistic images, a good fit for building reliable game worlds to train agents?
- Will better visuals inside the imagined world lead to better game performance in a short amount of real playtime?
How did the researchers approach it?
Key ideas explained simply
- A world model is like an AI’s “dream machine.” It learns how the game world works and then lets the agent practice inside this imagined world instead of always in the real game.
- Reinforcement learning (RL) means the agent learns by trying actions and getting rewards (points), gradually figuring out what works best.
- A diffusion model is an image generator. Imagine taking a clear picture and adding “static” noise to it, then teaching a model to remove that noise step by step until the image looks real again. If you can reliably reverse that noise, you can generate realistic images.
- In this paper, the world model is a diffusion model that predicts the next game frame (image) based on:
- previous frames it has “seen”
- the agent’s action (like moving left or shooting)
- a process of “denoising” that turns a noisy guess into a clean frame
How the agent learns
The training loop works like this:
- The agent spends a short time collecting real gameplay data (about 2 hours per game).
- The diffusion world model learns to predict the next frame from this data (basically, it learns the rules of the game’s visuals).
- The agent then practices inside the world model—its “imagination”—so it can try many strategies cheaply and safely.
- Repeat: collect a bit more data, improve the world model, train the agent more in imagination.
Smart design choices
- The authors use a particular diffusion setup called EDM (Elucidated Diffusion Model) instead of a more common one (DDPM). EDM helps produce stable, high-quality predictions with fewer “denoising steps,” which makes training and imagining faster.
- They found that too few denoising steps can make images blur or drift away from reality over time. Using around 3 steps strikes a good balance: visuals stay crisp, and the model stays fast.
- The agent uses simple “frame stacking” (keeping a few recent frames) for short-term memory, and separate small networks for reward and “is the game over?” predictions.
What did they find?
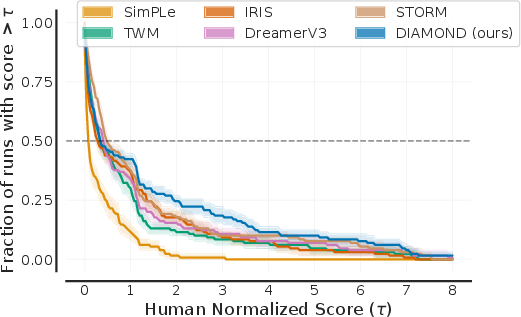
- On the challenging Atari 100k benchmark (26 classic games, with only 100,000 actions allowed for learning), the diamond agent achieves a mean human-normalized score of 1.46. In simple terms, 1.0 means “about human level,” so 1.46 is about 46% above that on average. It’s superhuman on 11 games.
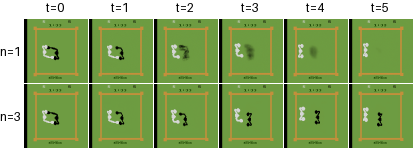
- The biggest gains show up in games where tiny visual details matter, like Asterix, Breakout, and Road Runner. For example, the model keeps scores, bricks, and rewards consistent frame to frame.
- Compared to a popular world model called IRIS (which compresses images into discrete tokens and predicts those), diamond’s diffusion images are more consistent over time. IRIS sometimes flips an enemy into a reward and back due to token errors; diamond avoids these small but important mistakes.
- Despite the good visuals, diamond isn’t slower or heavier: it uses fewer steps per frame and fewer parameters than some baselines.
Why is this important?
When training agents in the real world (like robots or self-driving cars), it’s risky and costly to learn purely by trial and error. Good world models let agents learn more safely and efficiently by practicing in imagination. But if the imagined world misses small visual details, the agent might learn bad habits. This paper shows that diffusion-based world models can keep those details and improve the agent’s performance, even with limited real data.
Implications and potential impact
- Safer, more sample-efficient learning: Agents can get strong results with much less real gameplay, which saves time, money, and risk.
- Better decisions from better visuals: Small objects, scores, or signals (like a tiny traffic light) can change what an agent should do. Keeping those details accurate helps the agent learn smarter strategies.
- Future directions: The authors suggest trying the method on continuous-action tasks (like controlling robots), giving the model longer-term memory (possibly with transformers), and integrating reward predictions directly into the diffusion model. They’ve also released code and “playable world models,” which can help other researchers build on this work.
Overall, this paper shows that using diffusion models for world modeling can make imagined practice more realistic and useful, leading to better performance with limited real-world experience.
Collections
Sign up for free to add this paper to one or more collections.