Next-slot OFDM-CSI Prediction: Multi-head Self-attention or State Space Model?
Abstract: The ongoing fifth-generation (5G) standardization is exploring the use of deep learning (DL) methods to enhance the new radio (NR) interface. Both in academia and industry, researchers are investigating the performance and complexity of multiple DL architecture candidates for specific one-sided and two-sided use cases such as channel state estimation (CSI) feedback, CSI prediction, beam management, and positioning. In this paper, we set focus on the CSI prediction task and study the performance and generalization of the two main DL layers that are being extensively benchmarked within the DL community, namely, multi-head self-attention (MSA) and state-space model (SSM). We train and evaluate MSA and SSM layers to predict the next slot for uplink and downlink communication scenarios over urban microcell (UMi) and urban macrocell (UMa) OFDM 5G channel models. Our numerical results demonstrate that SSMs exhibit better prediction and generalization capabilities than MSAs only for SISO cases. For MIMO scenarios, however, the MSA layer outperforms the SSM one. While both layers represent potential DL architectures for future DL-enabled 5G use cases, the overall investigation of this paper favors MSAs over SSMs.
- J. Yang, H. Jin, R. Tang, X. Han, Q. Feng, H. Jiang, S. Zhong, B. Yin, and X. Hu, “Harnessing the power of llms in practice: A survey on chatgpt and beyond,” ACM Transactions on Knowledge Discovery from Data, vol. 18, no. 6, pp. 1–32, 2024.
- L. Bariah, Q. Zhao, H. Zou, Y. Tian, F. Bader, and M. Debbah, “Large generative ai models for telecom: The next big thing?” IEEE Communications Magazine, 2024.
- X. Lin, “An overview of the 3gpp study on artificial intelligence for 5g new radio,” arXiv preprint arXiv:2308.05315, 2023.
- H. Kim, S. Kim, H. Lee, C. Jang, Y. Choi, and J. Choi, “Massive mimo channel prediction: Kalman filtering vs. machine learning,” IEEE Transactions on Communications, vol. 69, no. 1, pp. 518–528, 2020.
- J. B. Andersen, J. Jensen, S. H. Jensen, and F. Frederiksen, “Prediction of future fading based on past measurements,” in Gateway to 21st Century Communications Village. VTC 1999-Fall. IEEE VTS 50th Vehicular Technology Conference (Cat. No. 99CH36324), vol. 1. IEEE, 1999, pp. 151–155.
- W. Peng, M. Zou, and T. Jiang, “Channel prediction in time-varying massive mimo environments,” IEEE Access, vol. 5, pp. 23 938–23 946, 2017.
- W. Jiang and H. D. Schotten, “Neural network-based fading channel prediction: A comprehensive overview,” IEEE Access, vol. 7, pp. 118 112–118 124, 2019.
- Y. Yang, F. Gao, Z. Zhong, B. Ai, and A. Alkhateeb, “Deep transfer learning-based downlink channel prediction for fdd massive mimo systems,” IEEE Transactions on Communications, vol. 68, no. 12, pp. 7485–7497, 2020.
- C. Luo, J. Ji, Q. Wang, X. Chen, and P. Li, “Channel state information prediction for 5g wireless communications: A deep learning approach,” IEEE transactions on network science and engineering, vol. 7, no. 1, pp. 227–236, 2018.
- J. Wang, Y. Ding, S. Bian, Y. Peng, M. Liu, and G. Gui, “Ul-csi data driven deep learning for predicting dl-csi in cellular fdd systems,” IEEE Access, vol. 7, pp. 96 105–96 112, 2019.
- Y. Zhang, J. Wang, J. Sun, B. Adebisi, H. Gacanin, G. Gui, and F. Adachi, “Cv-3dcnn: Complex-valued deep learning for csi prediction in fdd massive mimo systems,” IEEE Wireless Communications Letters, vol. 10, no. 2, pp. 266–270, 2020.
- S. Mourya, P. Reddy, S. Amuru, and K. K. Kuchi, “Spectral temporal graph neural network for massive mimo csi prediction,” IEEE Wireless Communications Letters, 2024.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate channel prediction based on transformer: Making mobility negligible,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 9, pp. 2717–2732, 2022.
- A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, 2023.
- S. Jelassi, D. Brandfonbrener, S. M. Kakade, and E. Malach, “Repeat after me: Transformers are better than state space models at copying,” arXiv preprint arXiv:2402.01032, 2024.
- E. Nguyen, K. Goel, A. Gu, G. Downs, P. Shah, T. Dao, S. Baccus, and C. Ré, “S4nd: Modeling images and videos as multidimensional signals with state spaces,” Advances in neural information processing systems, vol. 35, pp. 2846–2861, 2022.
- M. M. Islam and G. Bertasius, “Long movie clip classification with state-space video models,” in European Conference on Computer Vision. Springer, 2022, pp. 87–104.
- C. Wang, O. Tsepa, J. Ma, and B. Wang, “Graph-mamba: Towards long-range graph sequence modeling with selective state spaces,” arXiv preprint arXiv:2402.00789, 2024.
- M. Akrout, A. Mezghani, E. Hossain, F. Bellili, and R. W. Heath, “From multilayer perceptron to gpt: A reflection on deep learning research for wireless physical layer,” arXiv preprint arXiv:2307.07359, 2023.
- M. Akrout, A. Feriani, F. Bellili, A. Mezghani, and E. Hossain, “Domain generalization in machine learning models for wireless communications: Concepts, state-of-the-art, and open issues,” IEEE Communications Surveys & Tutorials, 2023.
- Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 13 001–13 008.
- R. G. Lopes, D. Yin, B. Poole, J. Gilmer, and E. D. Cubuk, “Improving robustness without sacrificing accuracy with patch gaussian augmentation,” arXiv preprint arXiv:1906.02611, 2019.
- C. M. Bishop, “Training with noise is equivalent to tikhonov regularization,” Neural computation, vol. 7, no. 1, pp. 108–116, 1995.
- A. Tustin, “A method of analysing the behaviour of linear systems in terms of time series,” Journal of the Institution of Electrical Engineers-Part IIA: Automatic Regulators and Servo Mechanisms, vol. 94, no. 1, pp. 130–142, 1947.
- A. Gu, K. Goel, and C. Ré, “Efficiently modeling long sequences with structured state spaces,” arXiv preprint arXiv:2111.00396, 2021.
- A. Gu, T. Dao, S. Ermon, A. Rudra, and C. Ré, “Hippo: Recurrent memory with optimal polynomial projections,” Advances in neural information processing systems, vol. 33, pp. 1474–1487, 2020.
- G. T. 38.901, “Study on channel model for frequencies from 0.5 to 100 ghz,” 2017.
- J. Hoydis, S. Cammerer, F. A. Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,” arXiv preprint arXiv:2203.11854, 2022.
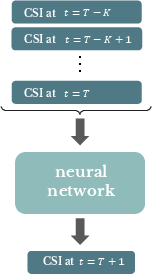
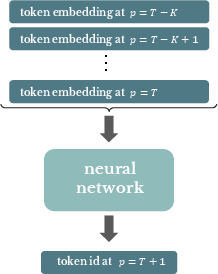
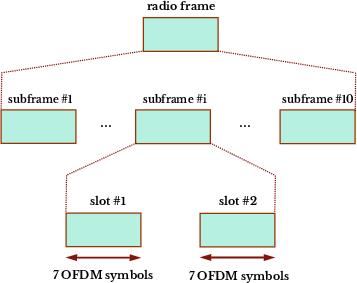
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.