Splat-MOVER: Multi-Stage, Open-Vocabulary Robotic Manipulation via Editable Gaussian Splatting
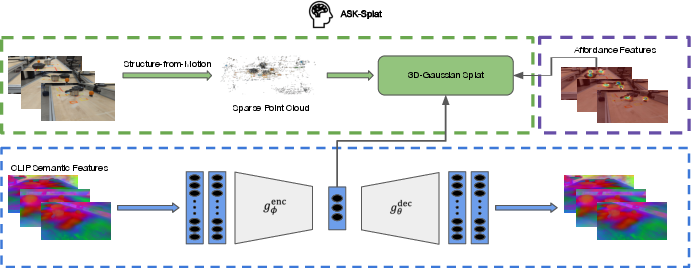
Abstract: We present Splat-MOVER, a modular robotics stack for open-vocabulary robotic manipulation, which leverages the editability of Gaussian Splatting (GSplat) scene representations to enable multi-stage manipulation tasks. Splat-MOVER consists of: (i) ASK-Splat, a GSplat representation that distills semantic and grasp affordance features into the 3D scene. ASK-Splat enables geometric, semantic, and affordance understanding of 3D scenes, which is critical in many robotics tasks; (ii) SEE-Splat, a real-time scene-editing module using 3D semantic masking and infilling to visualize the motions of objects that result from robot interactions in the real-world. SEE-Splat creates a "digital twin" of the evolving environment throughout the manipulation task; and (iii) Grasp-Splat, a grasp generation module that uses ASK-Splat and SEE-Splat to propose affordance-aligned candidate grasps for open-world objects. ASK-Splat is trained in real-time from RGB images in a brief scanning phase prior to operation, while SEE-Splat and Grasp-Splat run in real-time during operation. We demonstrate the superior performance of Splat-MOVER in hardware experiments on a Kinova robot compared to two recent baselines in four single-stage, open-vocabulary manipulation tasks and in four multi-stage manipulation tasks, using the edited scene to reflect changes due to prior manipulation stages, which is not possible with existing baselines. Video demonstrations and the code for the project are available at https://splatmover.github.io.
- J. J. Gibson, “The ecological approach to the visual perception of pictures,” Leonardo, vol. 11, no. 3, pp. 227–235, 1978.
- A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International Conference on Machine Learning (ICML). PMLR, 2021, pp. 8748–8763.
- C. Zhou, C. C. Loy, and B. Dai, “Extract free dense labels from CLIP,” in European Conference on Computer Vision (ECCV). Springer, 2022, pp. 696–712.
- W. Shen, G. Yang, A. Yu, J. Wong, L. P. Kaelbling, and P. Isola, “Distilled feature fields enable few-shot language-guided manipulation,” in 7th Annual Conference on Robot Learning (CoRL), 2023.
- S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak, “Affordances from human videos as a versatile representation for robotics,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 13 778–13 790.
- S. Kobayashi, E. Matsumoto, and V. Sitzmann, “Decomposing nerf for editing via feature field distillation,” in Advances in Neural Information Processing Systems, vol. 35, 2022. [Online]. Available: https://arxiv.org/pdf/2205.15585.pdf
- H.-S. Fang, C. Wang, M. Gou, and C. Lu, “Graspnet-1billion: A large-scale benchmark for general object grasping,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 444–11 453.
- A. Rashid, S. Sharma, C. M. Kim, J. Kerr, L. Y. Chen, A. Kanazawa, and K. Goldberg, “Language embedded radiance fields for zero-shot task-oriented grasping,” in 7th Annual Conference on Robot Learning (CoRL). PMLR, 2023, pp. 178–200.
- B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021.
- J. T. Barron, B. Mildenhall, D. Verbin, P. P. Srinivasan, and P. Hedman, “Mip-nerf 360: Unbounded anti-aliased neural radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5470–5479.
- ——, “Zip-nerf: Anti-aliased grid-based neural radiance fields,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19 697–19 705.
- T. Müller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,” ACM transactions on graphics (TOG), vol. 41, no. 4, pp. 1–15, 2022.
- T. Takikawa, A. Evans, J. Tremblay, T. Müller, M. McGuire, A. Jacobson, and S. Fidler, “Variable bitrate neural fields,” in ACM SIGGRAPH 2022 Conference Proceedings, 2022, pp. 1–9.
- S. Fridovich-Keil, A. Yu, M. Tancik, Q. Chen, B. Recht, and A. Kanazawa, “Plenoxels: Radiance fields without neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5501–5510.
- X. Wu, J. Xu, Z. Zhu, H. Bao, Q. Huang, J. Tompkin, and W. Xu, “Scalable neural indoor scene rendering,” ACM transactions on graphics, vol. 41, no. 4, 2022.
- B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,” ACM Transactions on Graphics, vol. 42, no. 4, pp. 1–14, 2023.
- J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik, “LERF: Language embedded radiance fields,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 19 729–19 739.
- M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 2021, pp. 9630–9640. [Online]. Available: https://doi.org/10.1109/ICCV48922.2021.00951
- M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” arXiv preprint arXiv:2312.16084, 2023.
- X. Hu, Y. Wang, L. Fan, J. Fan, J. Peng, Z. Lei, Q. Li, and Z. Zhang, “Semantic anything in 3d gaussians,” arXiv preprint arXiv:2401.17857, 2024.
- S. Zhou, H. Chang, S. Jiang, Z. Fan, Z. Zhu, D. Xu, P. Chari, S. You, Z. Wang, and A. Kadambi, “Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,” arXiv preprint arXiv:2312.03203, 2023.
- X. Zuo, P. Samangouei, Y. Zhou, Y. Di, and M. Li, “Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding,” arXiv preprint arXiv:2401.01970, 2024.
- C. Wang, M. Chai, M. He, D. Chen, and J. Liao, “CLIP-NeRF: Text-and-image driven manipulation of neural radiance fields,” in CVPR, 2022, pp. 3835–3844.
- B. Li, K. Q. Weinberger, S. Belongie, V. Koltun, and R. Ranftl, “Language-driven semantic segmentation,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=RriDjddCLN
- H. O. Song, M. Fritz, D. Goehring, and T. Darrell, “Learning to detect visual grasp affordance,” IEEE Transactions on Automation Science and Engineering, vol. 13, no. 2, pp. 798–809, 2015.
- P. Ardón, E. Pairet, R. P. Petrick, S. Ramamoorthy, and K. S. Lohan, “Learning grasp affordance reasoning through semantic relations,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4571–4578, 2019.
- N. Yamanobe, W. Wan, I. G. Ramirez-Alpizar, D. Petit, T. Tsuji, S. Akizuki, M. Hashimoto, K. Nagata, and K. Harada, “A brief review of affordance in robotic manipulation research,” Advanced Robotics, vol. 31, no. 19-20, pp. 1086–1101, 2017.
- A. Myers, C. L. Teo, C. Fermüller, and Y. Aloimonos, “Affordance detection of tool parts from geometric features,” in 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 1374–1381.
- A. Roy and S. Todorovic, “A multi-scale CNN for affordance segmentation in RGB images,” in 14th European Conference on Computer Vision (ECCV). Springer, 2016, pp. 186–201.
- M. Hassanin, S. Khan, and M. Tahtali, “Visual affordance and function understanding: A survey,” ACM Computing Surveys (CSUR), vol. 54, no. 3, pp. 1–35, 2021.
- C. Pohl, K. Hitzler, R. Grimm, A. Zea, U. D. Hanebeck, and T. Asfour, “Affordance-based grasping and manipulation in real world applications,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 9569–9576.
- T. Nagarajan, C. Feichtenhofer, and K. Grauman, “Grounded human-object interaction hotspots from video,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 8688–8697.
- M. Goyal, S. Modi, R. Goyal, and S. Gupta, “Human hands as probes for interactive object understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 3293–3303.
- R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y. Zhu, S. Song, A. Kapoor, K. Hausman et al., “Foundation models in robotics: Applications, challenges, and the future,” arXiv preprint arXiv:2312.07843, 2023.
- W. Shen, G. Yang, A. Yu, J. Wong, L. P. Kaelbling, and P. Isola, “Distilled feature fields enable few-shot language-guided manipulation,” arXiv preprint arXiv:2308.07931, 2023.
- Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004.
- D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price et al., “Scaling egocentric vision: The epic-kitchens dataset,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 720–736.
- L. Medeiros, “Language Segment-Anything,” https://github.com/luca-medeiros/lang-segment-anything, 2023.
- X. Dai, Y. Chen, B. Xiao, D. Chen, M. Liu, L. Yuan, and L. Zhang, “Dynamic head: Unifying object detection heads with attentions,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7373–7382.
- N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213–229.
- H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y. Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” arXiv preprint arXiv:2203.03605, 2022.
- M. Tancik, E. Weber, R. Li, B. Yi, T. Wang, A. Kristoffersen, J. Austin, K. Salahi, A. Ahuja, D. McAllister, A. Kanazawa, and E. Ng, “Nerfstudio: A framework for neural radiance field development,” in SIGGRAPH, 2023.
- J. L. Schönberger and J.-M. Frahm, “Structure-from-motion revisited,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- D. Coleman, I. A. Şucan, S. Chitta, and N. Correll, “Reducing the barrier to entry of complex robotic software: a moveit! case study,” Journal of Software Engineering for Robotics, vol. 5(1), p. 3–16, 2014.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.