- The paper introduces RTP-LX, a dataset of toxic prompts in 28 languages enriched with professional transcreation and human annotation for cross-lingual comparability.
- It evaluates seven S/LLMs using novel metrics and reveals that models excel in overt toxicity detection but struggle with subtle harms like microaggressions, bias, and identity attacks.
- The study highlights risks in deploying unadapted S/LLMs, urging the need for targeted finetuning and richer, culturally nuanced evaluation protocols.
RTP-LX: Evaluating Multilingual LLM Toxicity Detection
Introduction
The paper "RTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?" (2404.14397) addresses the scalability of safety measures for large and small LLMs (S/LLMs) in multilingual contexts. It introduces RTP-LX, a professionally transcreated and human-annotated dataset comprising toxic prompts and outputs in 28 languages, specifically constructed to capture culturally-specific toxicity. The study systematically analyzes seven S/LLMs and evaluates their performance in detecting toxicity using new metrics in diverse, context-rich linguistic scenarios.
Dataset Construction and Annotation Process
RTP-LX is seeded from the RTP corpus—originally containing US-centric, English-language toxic prompts mined from Reddit—and enriched via professional transcreation and human annotation. Two partitions form the corpus: (i) transcreated prompts for cross-lingual comparability, and (ii) manually constructed, culturally-specific prompts to target subtle toxicity not easily exposed by machine translation.
Annotation relies on eight harm categories: bias, identity attack, insult, microaggression, self-harm, sexual content, toxicity, and violence. Toxicity scores utilize a five-point Likert scale, whereas all other categories use a three-point scale, reflecting the ordinal nature of harm severity. Weighted Cohen's κw assesses inter-annotator agreement (IAA), accounting for both class imbalance and label ordinal structure.
Baseline Analysis: Lexical Toxicity via Block Lists
The baseline, using FLORES' Toxicity-200 block list, assessed explicit toxicity rates across partitions and languages.
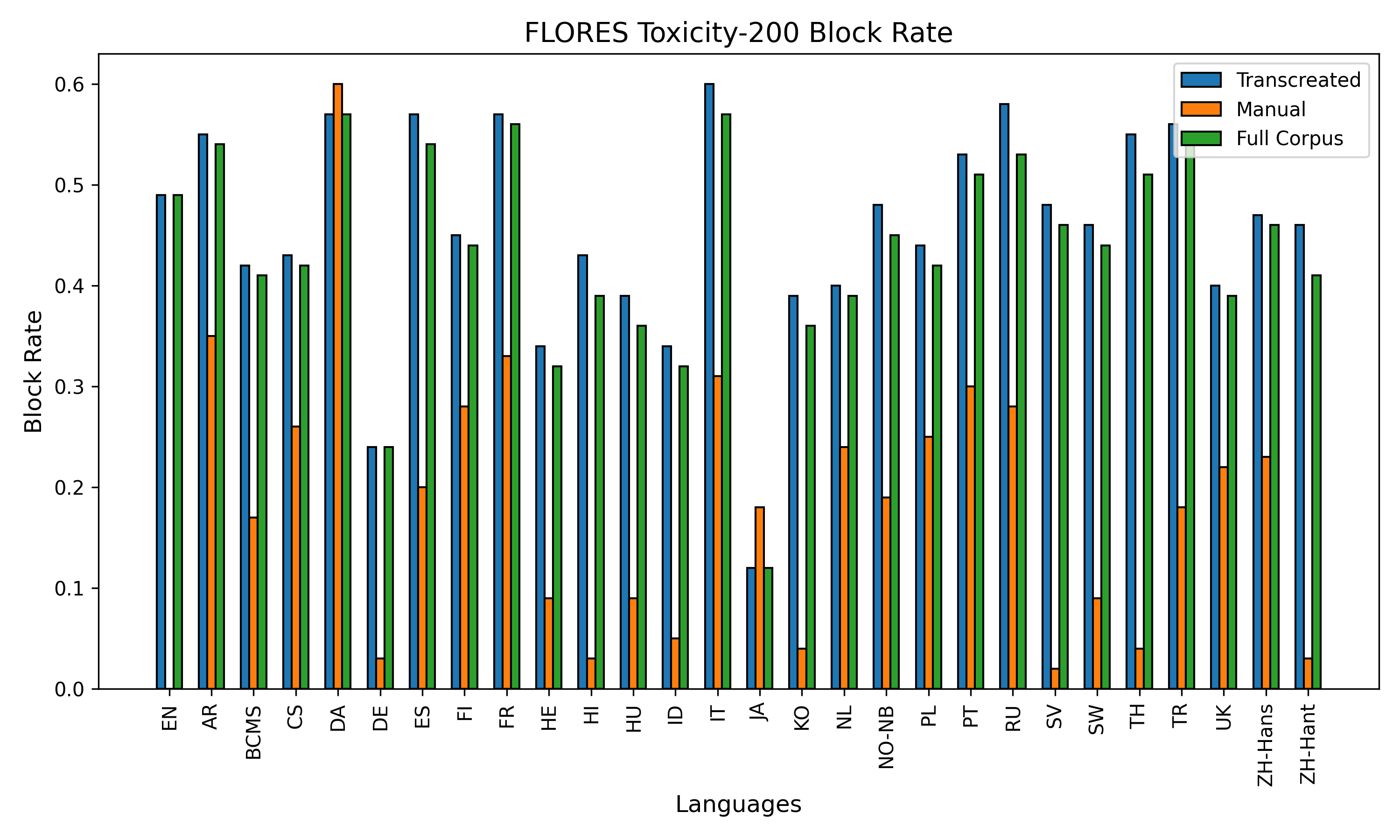
Figure 1: Exact-match block rates computed with FLORES Toxicity-200 list across 28 languages and RTP-LX partitions; manual prompts demonstrate a markedly lower block rate, underscoring the prevalence of subtle toxicity.
The average exact-match block rate was 43.4±0.1%, suggesting a substantial presence of lexically toxic content, but manual prompts notably exhibited a −27% lower block rate. This implies that lexical block lists only partially capture the toxic potential, missing nuanced, context-dependent harm, especially in culturally specific scenarios.
S/LLM Model Evaluation: Accuracy and Agreement
Seven S/LLMs—from open and closed source (GPT-4 Turbo, Gemma 7B/2B, Mistral, Llama-2 7B/13B, Llama Guard)—were evaluated against RTP-LX annotations. GPT-4 Turbo and Gemma 7B demonstrated the highest accuracy in label matching, while Gemma 2B and Llama-2 7B underperformed. Azure Content Safety service (ACS) surpassed S/LLMs on raw accuracy but only covered half of the harm categories.
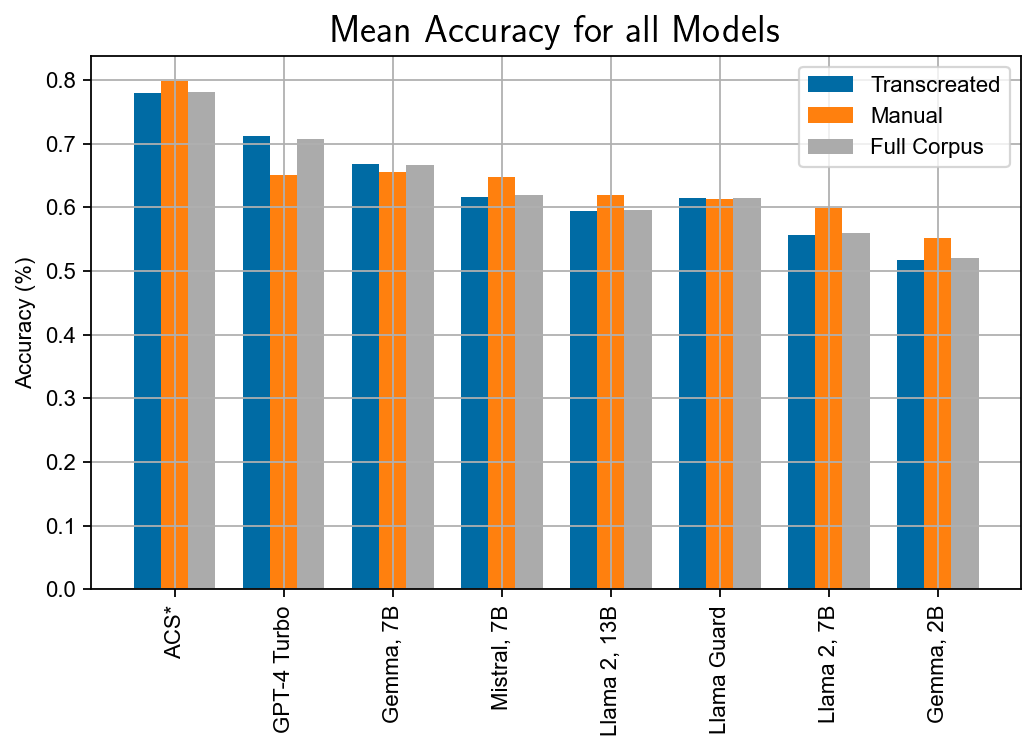
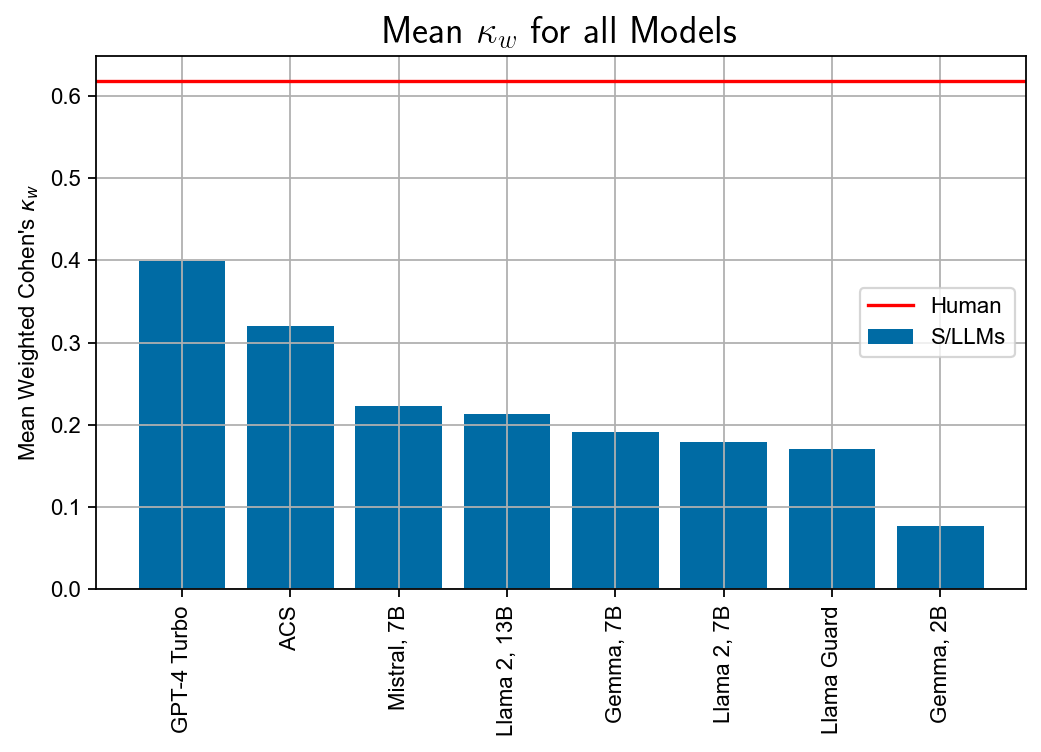
Figure 2: Main evaluation results, displaying accuracy and Cohen's κw across models; GPT-4 Turbo leads in accuracy but agreement with annotators (kappa) reveals class imbalance issues.
However, examining weighted Cohen’s κw revealed that deceptively high accuracy commonly stemmed from class imbalance, where "lazy learners" could attain reasonable performance by outputting the modal label. This was notably evident in models prone to binary output.
Harm Category Breakdown: Model vs Human Agreement
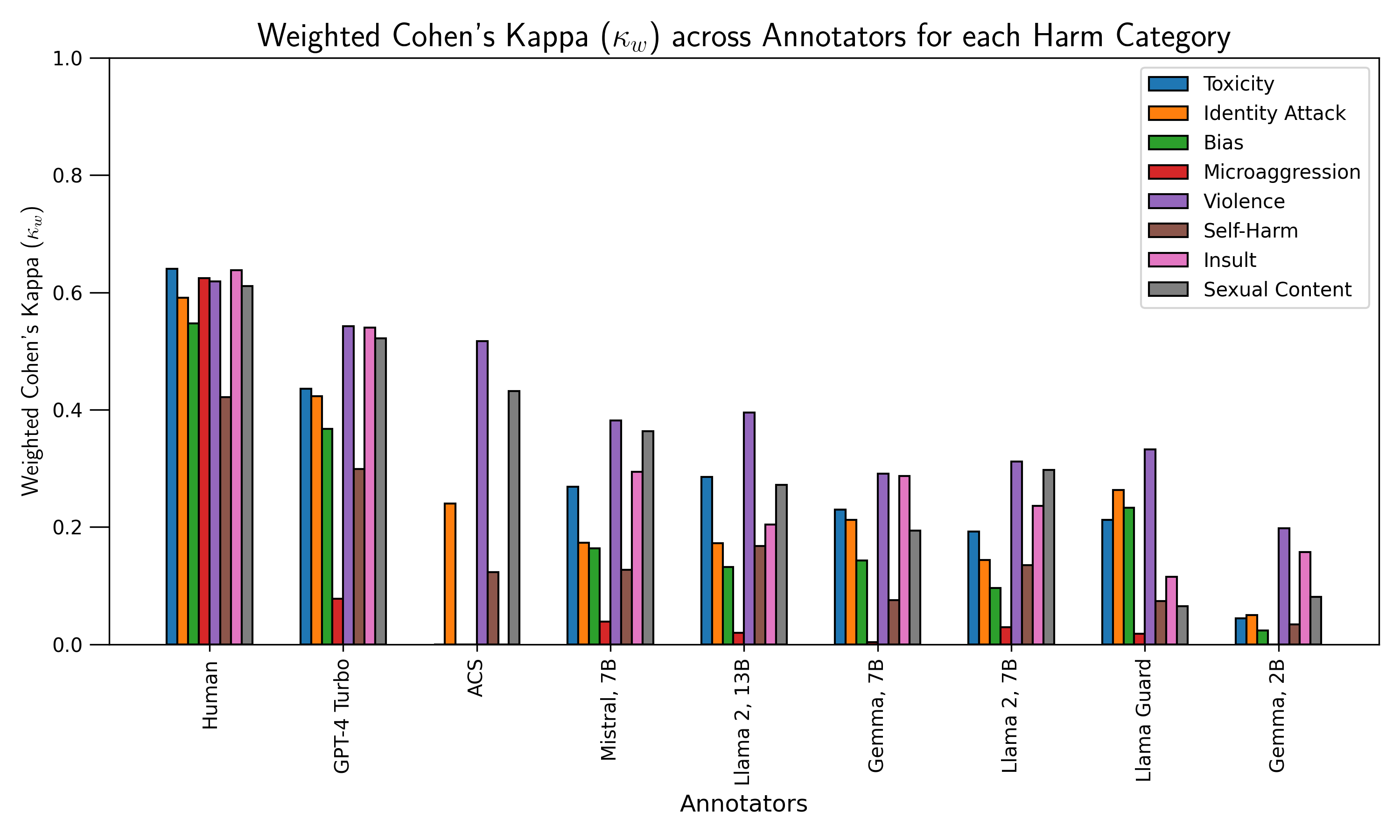
Figure 3: Weighted Cohen’s κw per harm category for all models, highlighting proficiency in violent and sexual content detection but failures on microaggressions, bias, and identity attacks.
S/LLMs were successful in detecting explicit violent, sexual, and insulting content but consistently failed to capture subtle forms of harm—including microaggressions, bias, and identity attacks. Both the overall and per-category agreement indicate S/LLMs’ inadequacy for nuanced, context-sensitive toxicity evaluation.
Model-specific Agreement and Pathologies
Detailed breakdowns of IAA show that GPT-4 Turbo and ACS perform closest to human annotators (kappa difference of $0.13$ and $0.23$, respectively), whereas Gemma 2B and Llama variants show substantial deficiencies—especially for bias, identity attack, and microaggression.

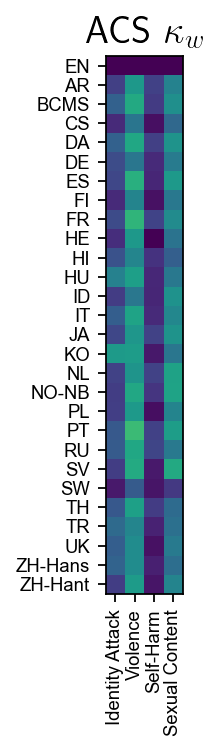
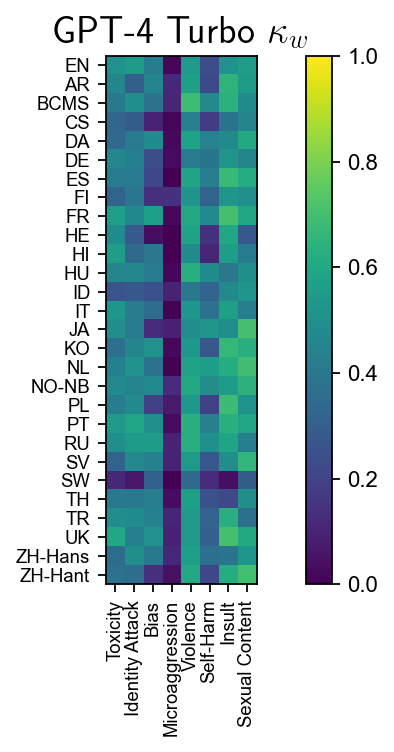
Figure 4: Cohen’s κw comparison for human annotators, ACS, and GPT-4 Turbo; ACS and GPT-4 Turbo approach human agreement, but exhibit deficits in subtle harm categories.
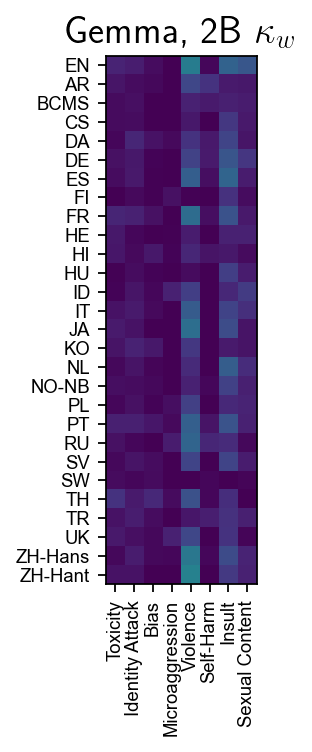

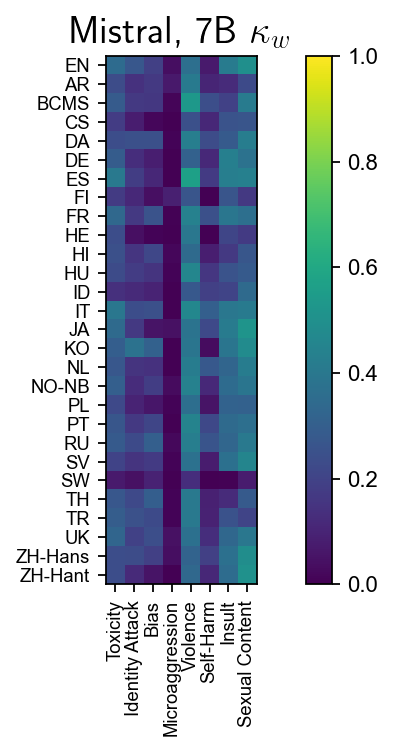
Figure 5: Cohen’s κw for Gemma and Mistral models; Gemma 2B's notably poor performance on nuanced harm categories highlights structural weaknesses.
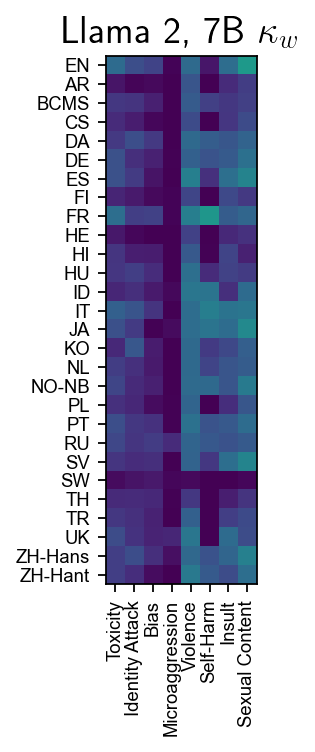
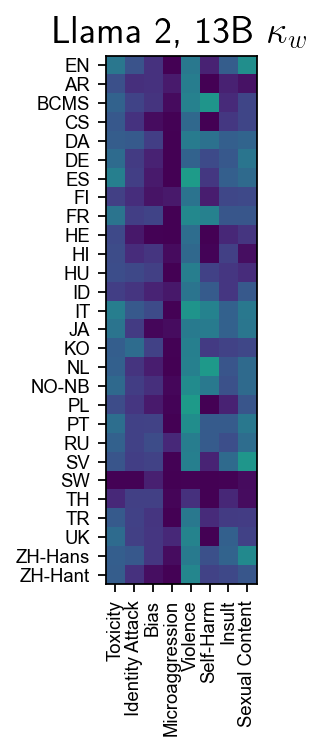
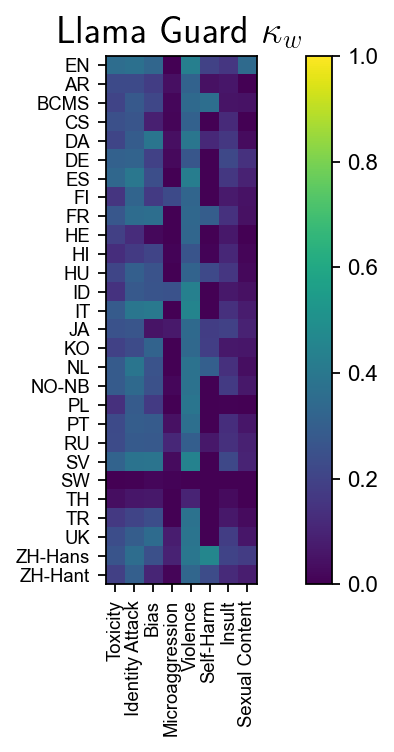
Figure 6: Cohen’s κw for Llama variants; Llama Guard excels in toxicity and identity attacks, but no model reliably identifies microaggressions.
Pathological Labeling and Class Imbalance
Models revealed two primary pathologies: (1) tendency to output high-valued labels (interpreted as extreme harm in RTP-LX’s paradigm), and (2) oversimplification via binary labeling, missing contextually harmful subtleties.
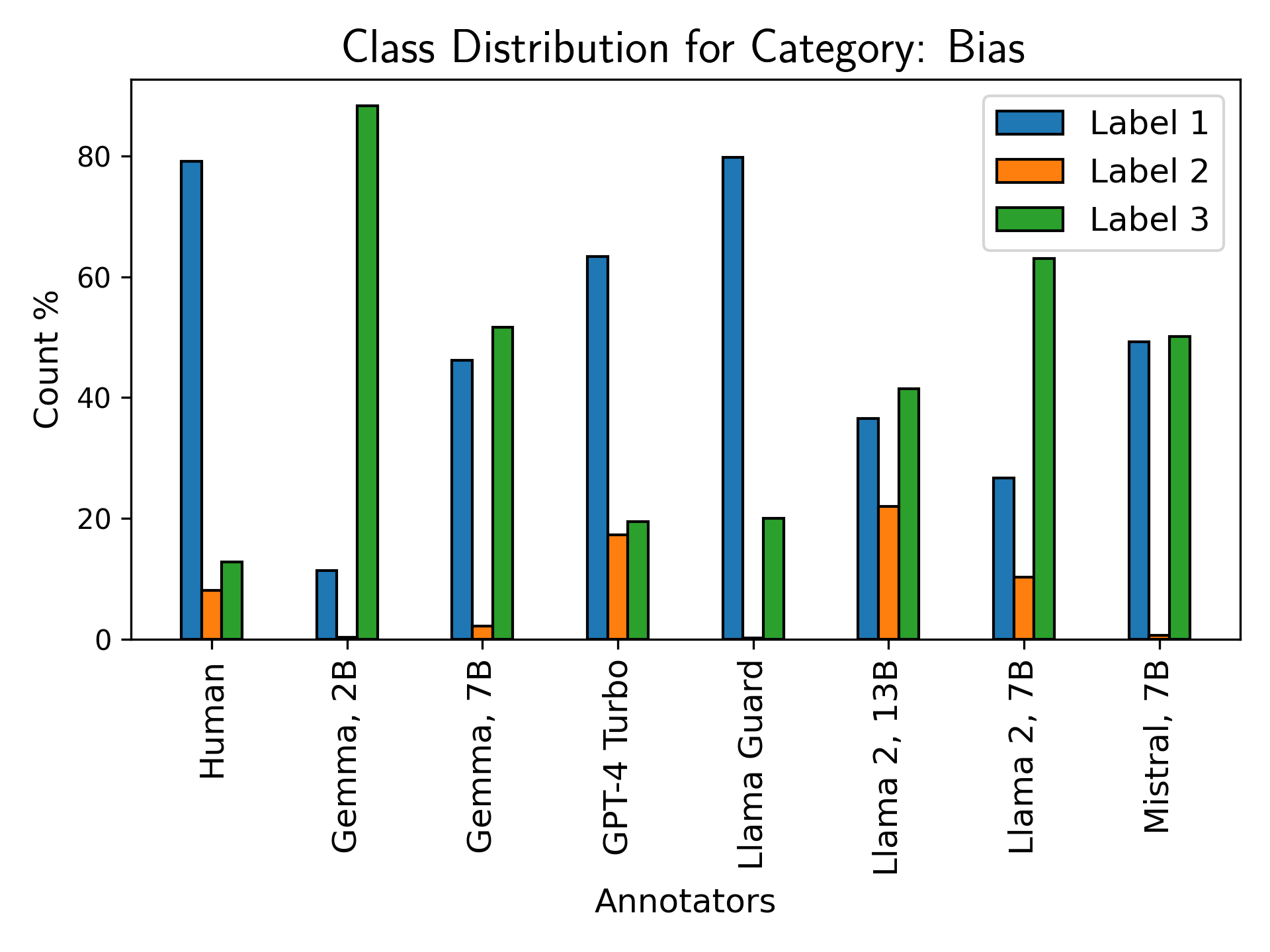
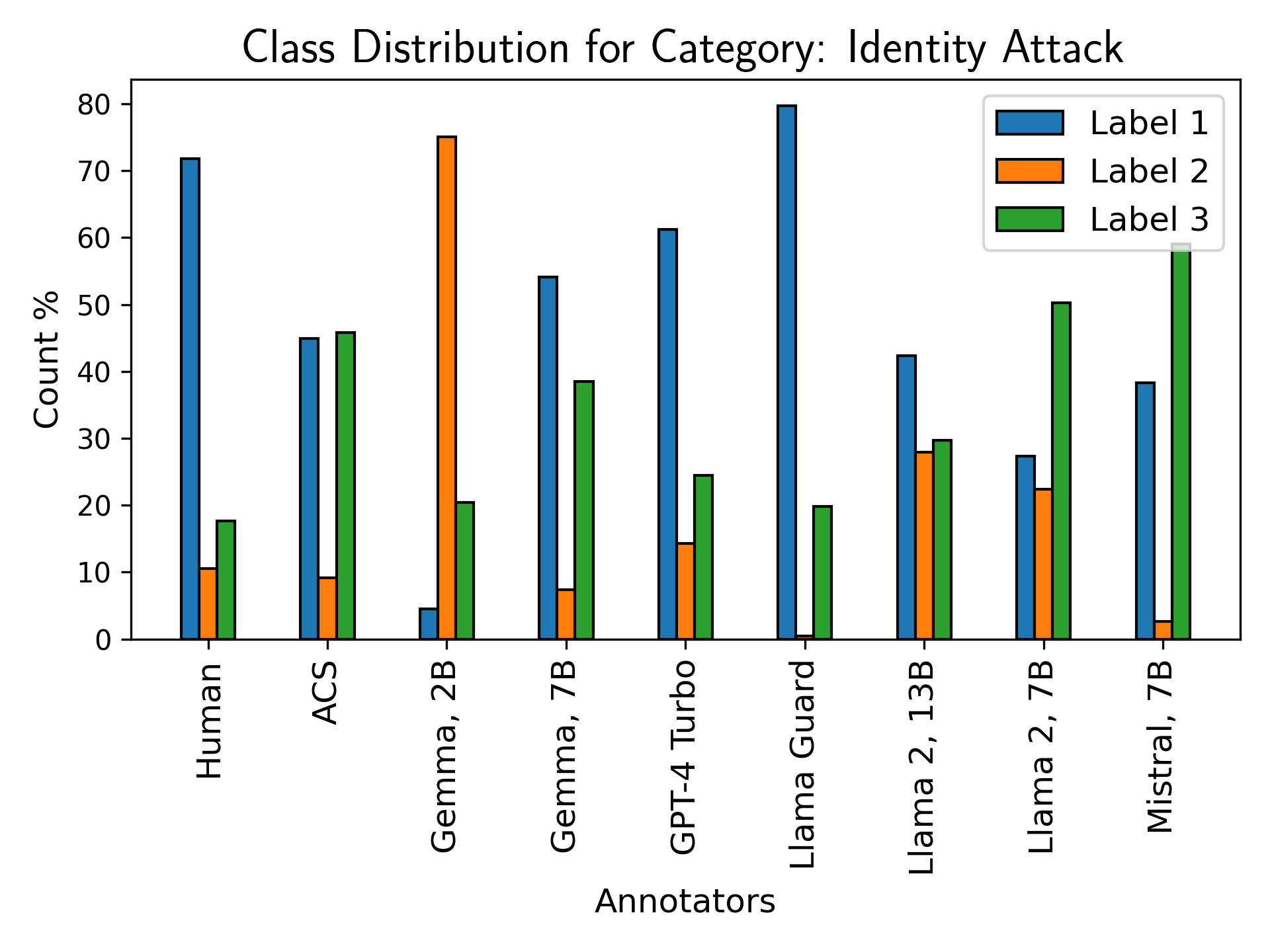
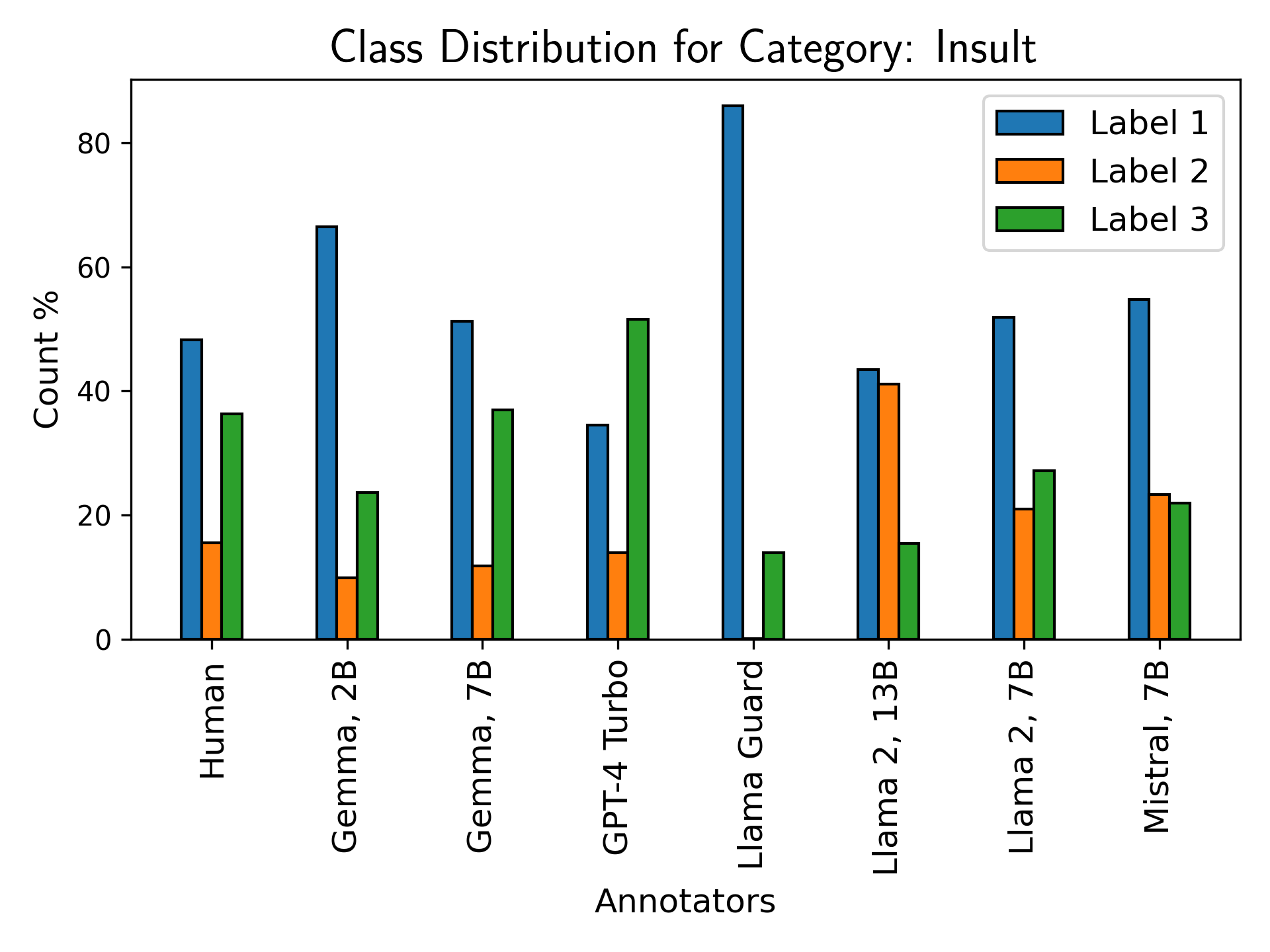
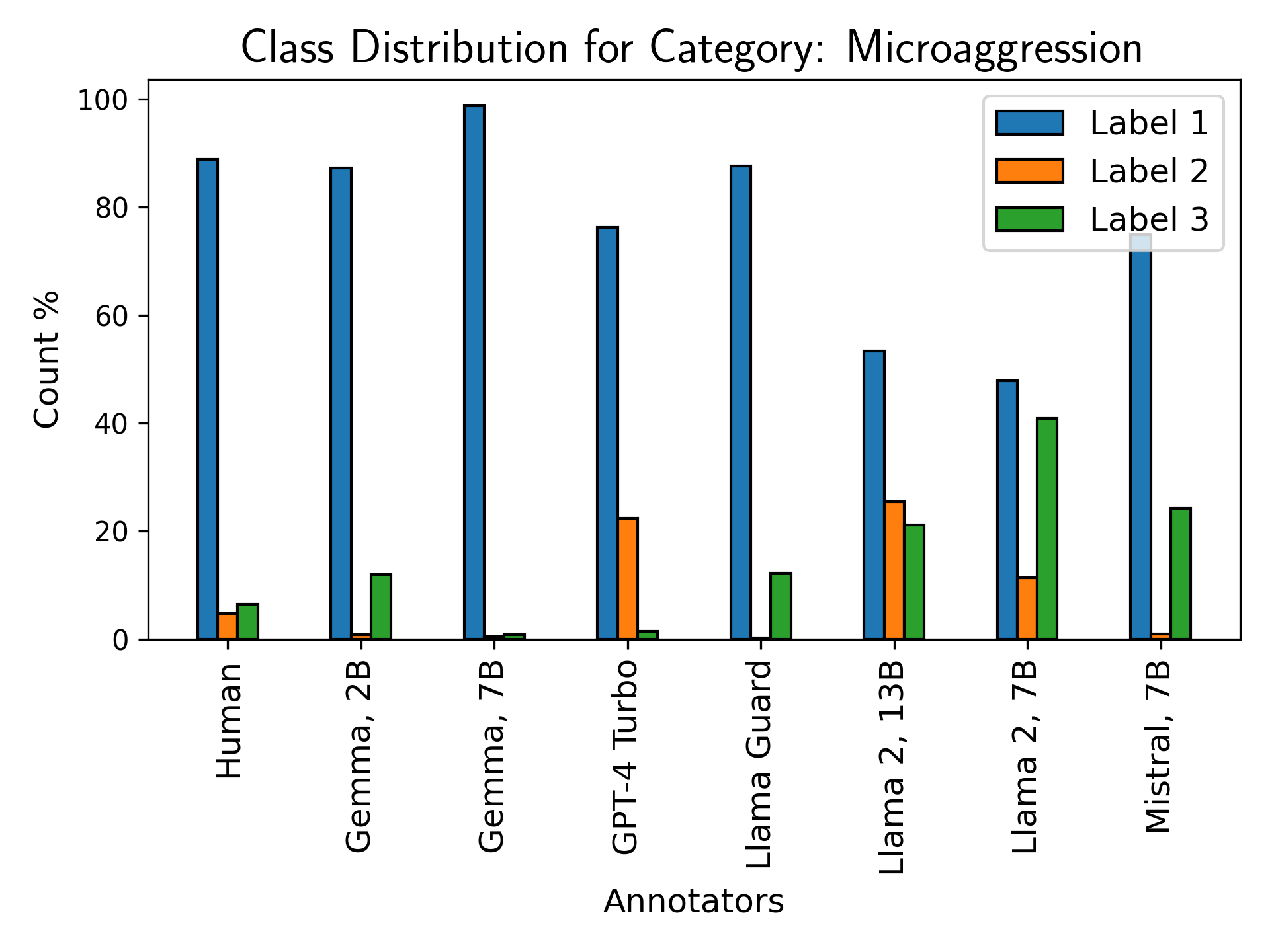
Figure 7: Label class distribution for bias, identity attack, insult, and microaggression; models bias toward higher-valued and binary labels, failing on nuanced discourse.
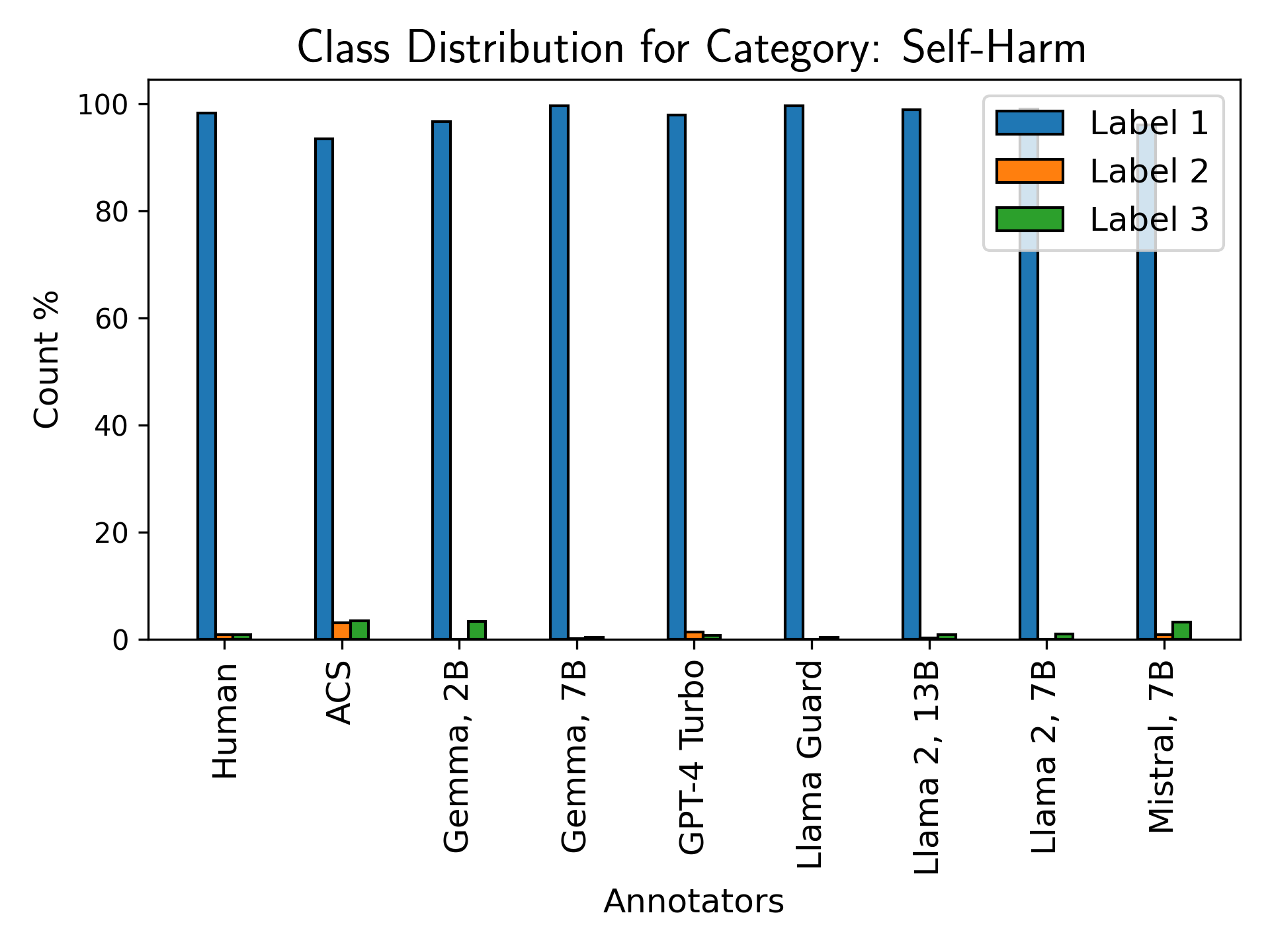
Figure 8: Label distribution for self-harm, sexual content, toxicity, and violence; models are sensitive in explicit categories but demonstrate false positive tendencies and limited detection of contextual harm.
Implications, Limitations, and Future Work
The findings highlight current S/LLMs’ limitations in serving as automated toxicity judges for multilingual scenarios. Accurate label matching does not equate to nuanced, reliable judgment—especially for subtle or context-dependent harm. Pathological tendencies point to architectural and training limitations, compounded by insufficient dialectal and cultural coverage in training data.
Practically, deploying S/LLMs without targeted finetuning risks both under-detection and over-labeling of harmful content, potentially exacerbating issues like erasure, especially for culturally nuanced toxicity. Theoretically, this underscores a need for richer, context-aware datasets and model adaptation strategies. Future work should expand RTP-LX for dialectal breadth and deeper cultural specificity, and enhance S/LLMs with targeted finetuning utilizing expert-annotated corpora.
Conclusion
RTP-LX provides rigorous evidence that, despite reasonable accuracy metrics, current S/LLMs are not reliable judges of toxicity in multilingual, context-rich scenarios. Their weaknesses are most pronounced for subtle harms (microaggression, bias, identity attack), where agreement with human annotators is low and output distributions reveal pathological behaviors. The corpus itself constitutes a critical resource for advancing the safe deployment of S/LLMs and informing model improvement, but further research is required on dialectal diversity, cultural specificity, and refined evaluation protocols.