ConCLVD: Controllable Chinese Landscape Video Generation via Diffusion Model
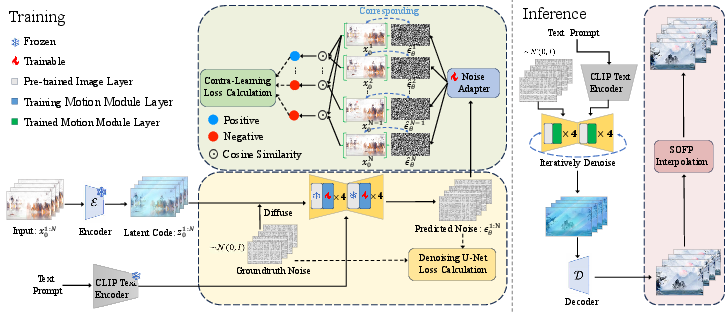
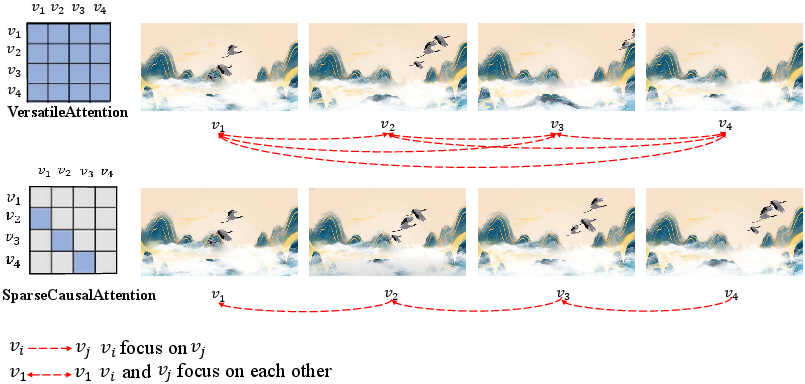
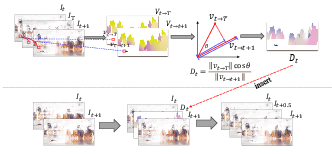
Abstract: Chinese landscape painting is a gem of Chinese cultural and artistic heritage that showcases the splendor of nature through the deep observations and imaginations of its painters. Limited by traditional techniques, these artworks were confined to static imagery in ancient times, leaving the dynamism of landscapes and the subtleties of artistic sentiment to the viewer's imagination. Recently, emerging text-to-video (T2V) diffusion methods have shown significant promise in video generation, providing hope for the creation of dynamic Chinese landscape paintings. However, challenges such as the lack of specific datasets, the intricacy of artistic styles, and the creation of extensive, high-quality videos pose difficulties for these models in generating Chinese landscape painting videos. In this paper, we propose CLV-HD (Chinese Landscape Video-High Definition), a novel T2V dataset for Chinese landscape painting videos, and ConCLVD (Controllable Chinese Landscape Video Diffusion), a T2V model that utilizes Stable Diffusion. Specifically, we present a motion module featuring a dual attention mechanism to capture the dynamic transformations of landscape imageries, alongside a noise adapter to leverage unsupervised contrastive learning in the latent space. Following the generation of keyframes, we employ optical flow for frame interpolation to enhance video smoothness. Our method not only retains the essence of the landscape painting imageries but also achieves dynamic transitions, significantly advancing the field of artistic video generation. The source code and dataset are available at https://anonymous.4open.science/r/ConCLVD-EFE3.
- Latent-shift: Latent diffusion with temporal shift for efficient text-to-video generation. ArXiv, 2023.
- Sundial-gan: A cascade generative adversarial networks framework for deciphering oracle bone inscriptions. In Proceedings of the 30th ACM International Conference on Multimedia, 2022.
- A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, 2020.
- Generating long sequences with sparse transformers. ArXiv, 2019.
- Efficiency-optimized video diffusion models. Proceedings of the 31st ACM International Conference on Multimedia, 2023.
- Mv-diffusion: Motion-aware video diffusion model. Proceedings of the 31st ACM International Conference on Multimedia, 2023.
- Tim Dettmers. The best gpus for deep learning in 2023 — an in-depth analysis, 2023.
- Diffusion models beat gans on image synthesis, 2021.
- Structure and content-guided video synthesis with diffusion models, 2023.
- Institute for Intelligent Computing. Text-to-video-synthesis model in open domain — modelscope.cn. https://modelscope.cn/models/iic/text-to-video-synthesis/summary, 2024.
- Tokenflow: Consistent diffusion features for consistent video editing. ArXiv, 2023.
- Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. ArXiv, 2023.
- Imagine this! scripts to compositions to videos. In European Conference on Computer Vision, 2018.
- Prompt-to-prompt image editing with cross attention control. ArXiv, 2022.
- Asymmetric bilateral motion estimation for video frame interpolation. 2021.
- Real-time intermediate flow estimation for video frame interpolation. In European Conference on Computer Vision, 2020.
- Text2video-zero: Text-to-image diffusion models are zero-shot video generators. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, 2023.
- Autodiffusion: Training-free optimization of time steps and architectures for automated diffusion model acceleration. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, 2023.
- Transform a simple sketch to a chinese painting by a multiscale deep neural network. Algorithms, 2018.
- Animatediff-lightning: Cross-model diffusion distillation, 2024.
- Cross-modal dual learning for sentence-to-video generation. Proceedings of the 27th ACM International Conference on Multimedia, 2019.
- Follow your pose: Pose-guided text-to-video generation using pose-free videos. In AAAI Conference on Artificial Intelligence, 2023.
- Attentive semantic video generation using captions. 2017 IEEE International Conference on Computer Vision (ICCV), 2017.
- Sync-draw: Automatic video generation using deep recurrent attentive architectures. Proceedings of the 25th ACM International Conference on Multimedia, 2016.
- To create what you tell: Generating videos from captions. Proceedings of the 25th ACM International Conference on Multimedia, 2017.
- Pika labs. Pika — pika.art. https://pika.art/, 2024. [Accessed 25-03-2024].
- Fatezero: Fusing attentions for zero-shot text-based video editing. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
- Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 2021.
- High-resolution image synthesis with latent diffusion models. pages 10674–10685, 2021.
- U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015 - 18th International Conference Munich, Germany, October 5 - 9, 2015, Proceedings, Part III, 2015.
- RunwayML Research Team. Gen-2 by Runway — research.runwayml.com. https://research.runwayml.com/gen2, 2024. [Accessed 25-03-2024].
- Make-a-video: Text-to-video generation without text-video data. 2023.
- Denoising diffusion implicit models. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021.
- Raft: Recurrent all-pairs field transforms for optical flow. In European Conference on Computer Vision, 2020.
- Attention is all you need. In Neural Information Processing Systems, 2017.
- Animatelcm: Accelerating the animation of personalized diffusion models and adapters with decoupled consistency learning, 2024.
- Videofactory: Swap attention in spatiotemporal diffusions for text-to-video generation. ArXiv, 2023.
- Chinastyle: A mask-aware generative adversarial network for chinese traditional image translation. SIGGRAPH Asia 2019 Technical Briefs, 2019.
- Cclap: Controllable chinese landscape painting generation via latent diffusion model. 2023 IEEE International Conference on Multimedia and Expo (ICME), 2023.
- Lamp: Learn a motion pattern for few-shot-based video generation. ArXiv, 2023.
- Make-your-video: Customized video generation using textual and structural guidance. IEEE Transactions on Visualization and Computer Graphics, 2023.
- Alice Xue. End-to-end chinese landscape painting creation using generative adversarial networks. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
- Seco: Exploring sequence supervision for unsupervised representation learning. In AAAI Conference on Artificial Intelligence, 2020.
- Learning to generate poetic chinese landscape painting with calligraphy. 2022.
- Clearer frames, anytime: Resolving velocity ambiguity in video frame interpolation, 2023.
- An interactive and generative approach for chinese shanshui painting document. 2019 International Conference on Document Analysis and Recognition (ICDAR), 2019.
- Magicvideo: Efficient video generation with latent diffusion models. ArXiv, 2022.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

