Neuron Specialization: Leveraging intrinsic task modularity for multilingual machine translation
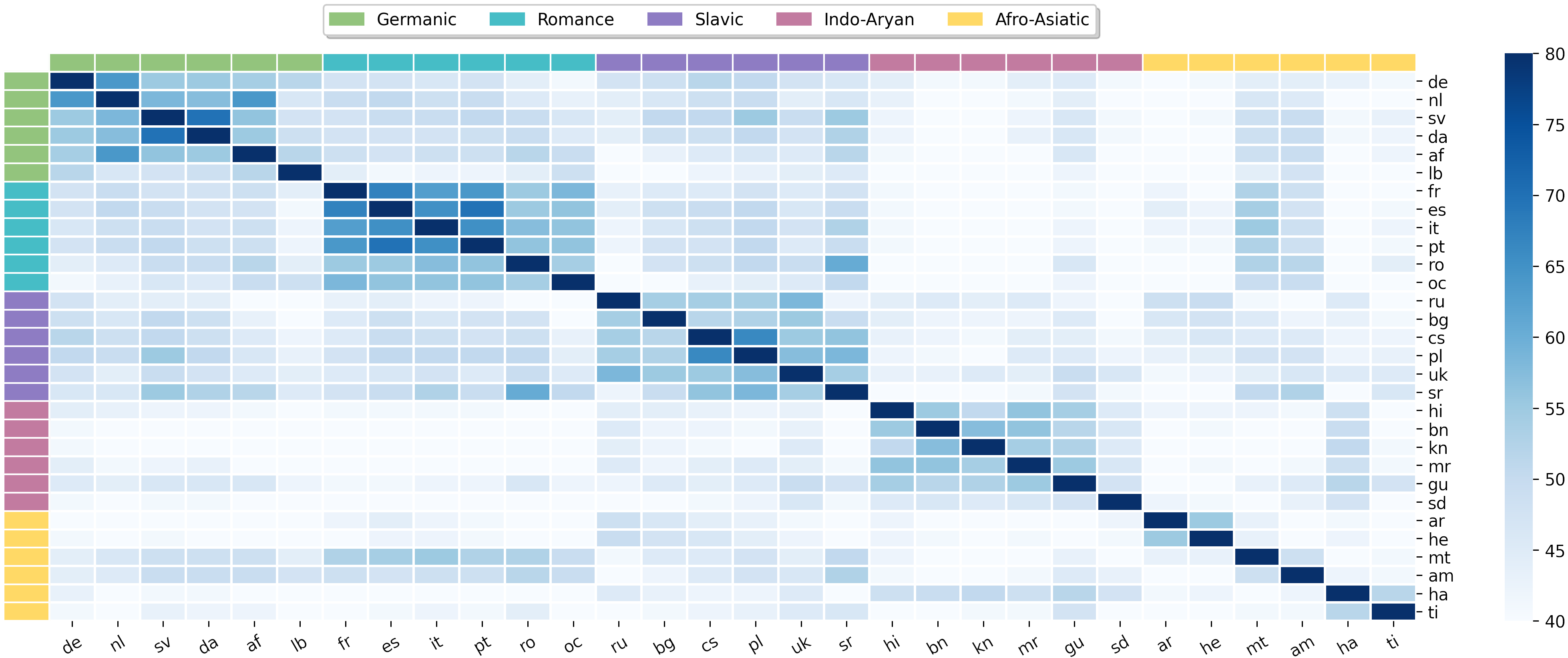
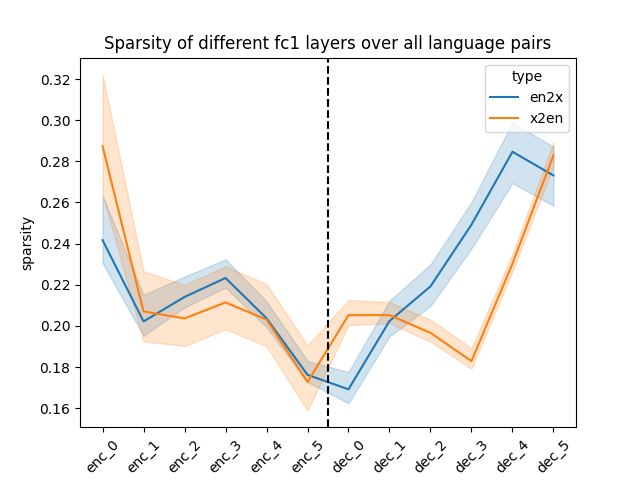
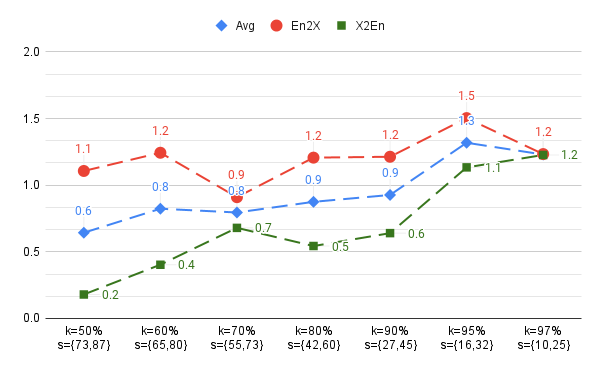
Abstract: Training a unified multilingual model promotes knowledge transfer but inevitably introduces negative interference. Language-specific modeling methods show promise in reducing interference. However, they often rely on heuristics to distribute capacity and struggle to foster cross-lingual transfer via isolated modules. In this paper, we explore intrinsic task modularity within multilingual networks and leverage these observations to circumvent interference under multilingual translation. We show that neurons in the feed-forward layers tend to be activated in a language-specific manner. Meanwhile, these specialized neurons exhibit structural overlaps that reflect language proximity, which progress across layers. Based on these findings, we propose Neuron Specialization, an approach that identifies specialized neurons to modularize feed-forward layers and then continuously updates them through sparse networks. Extensive experiments show that our approach achieves consistent performance gains over strong baselines with additional analyses demonstrating reduced interference and increased knowledge transfer.
- Massively multilingual neural machine translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3874–3884.
- Ali Araabi and Christof Monz. 2020. Optimizing transformer for low-resource neural machine translation. In Proceedings of the 28th International Conference on Computational Linguistics, pages 3429–3435.
- Ankur Bapna and Orhan Firat. 2019. Simple, scalable adaptation for neural machine translation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1538–1548.
- When is multilinguality a curse? language modeling for 250 high-and low-resource languages. arXiv preprint arXiv:2311.09205.
- Cross-lingual transfer with language-specific subnetworks for low-resource dependency parsing. Computational Linguistics, 49(3):613–641.
- Examining modularity in multilingual lms via language-specialized subnetworks. arXiv preprint arXiv:2311.08273.
- Language-family adapters for low-resource multilingual neural machine translation. In Proceedings of the The Sixth Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2023), pages 59–72.
- Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451.
- No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672.
- Brain-like functional specialization emerges spontaneously in deep neural networks. Science advances, 8(11):eabl8913.
- Beyond english-centric multilingual machine translation. The Journal of Machine Learning Research, 22(1):4839–4886.
- Ntrex-128–news test references for mt evaluation of 128 languages. In Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, pages 21–24.
- Jonathan Frankle and Michael Carbin. 2018. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations.
- Gradient-based gradual pruning for language-specific multilingual neural machine translation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 654–670.
- Dan Hendrycks and Kevin Gimpel. 2016. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415.
- Google’s multilingual neural machine translation system: Enabling zero-shot translation. Transactions of the Association for Computational Linguistics, 5:339–351.
- Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71.
- Investigating multilingual nmt representations at scale. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1565–1575.
- Bloom: A 176b-parameter open-access multilingual language model.
- Xian Li and Hongyu Gong. 2021. Robust optimization for multilingual translation with imbalanced data. Advances in Neural Information Processing Systems, 34:25086–25099.
- Parameter-efficient fine-tuning without introducing new latency. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4242–4260, Toronto, Canada. Association for Computational Linguistics.
- Make pre-trained model reversible: From parameter to memory efficient fine-tuning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Learning language specific sub-network for multilingual machine translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 293–305.
- fairseq: A fast, extensible toolkit for sequence modeling. arXiv preprint arXiv:1904.01038.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Lifting the curse of multilinguality by pre-training modular transformers. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3479–3495.
- Modular deep learning. Transactions on Machine Learning Research. Survey Certification.
- How multilingual is multilingual bert? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4996–5001.
- Learning language-specific layers for multilingual machine translation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14767–14783.
- Maja Popović. 2017. chrf++: words helping character n-grams. In Proceedings of the second conference on machine translation, pages 612–618.
- Matt Post. 2018. A call for clarity in reporting bleu scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 186–191.
- Comet: A neural framework for mt evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685–2702.
- Causes and cures for interference in multilingual translation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada. Association for Computational Linguistics.
- Shaomu Tan and Christof Monz. 2023. Towards a better understanding of variations in zero-shot neural machine translation performance. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13553–13568.
- Attention is all you need. Advances in neural information processing systems, 30.
- Neurons in large language models: Dead, n-gram, positional. arXiv preprint arXiv:2309.04827.
- Qian Wang and Jiajun Zhang. 2022. Parameter differentiation based multilingual neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11440–11448.
- Gradient vaccine: Investigating and improving multi-task optimization in massively multilingual models. In International Conference on Learning Representations.
- Beyond shared vocabulary: Increasing representational word similarities across languages for multilingual machine translation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore. Association for Computational Linguistics.
- Do current multi-task optimization methods in deep learning even help? Advances in neural information processing systems, 35:13597–13609.
- Task representations in neural networks trained to perform many cognitive tasks. Nature neuroscience, 22(2):297–306.
- Share or not? learning to schedule language-specific capacity for multilingual translation. In International Conference on Learning Representations.
- Improving massively multilingual neural machine translation and zero-shot translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1628–1639.
- Emergent modularity in pre-trained transformers. In Findings of the Association for Computational Linguistics: ACL 2023, pages 4066–4083, Toronto, Canada. Association for Computational Linguistics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

