From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
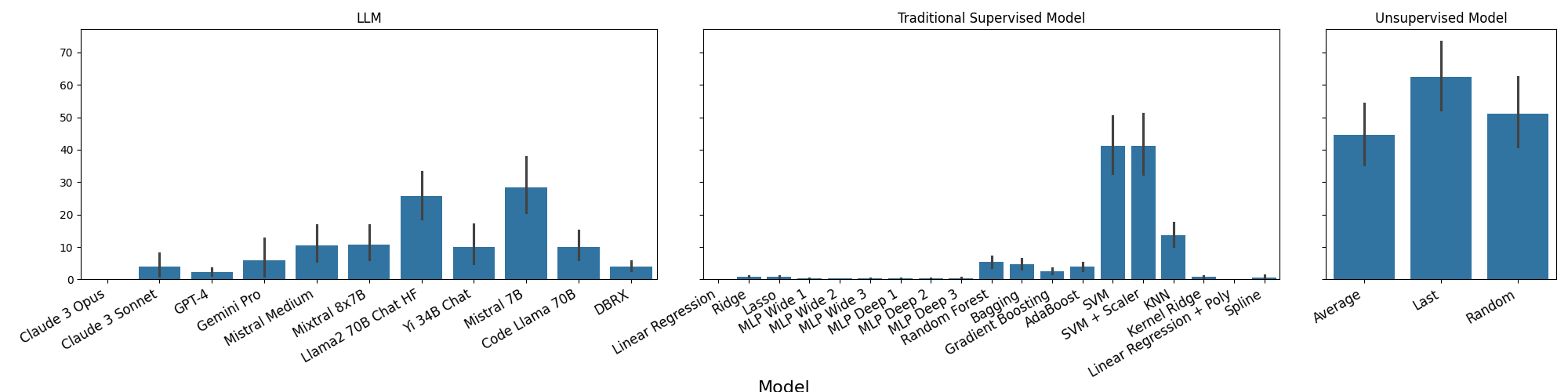
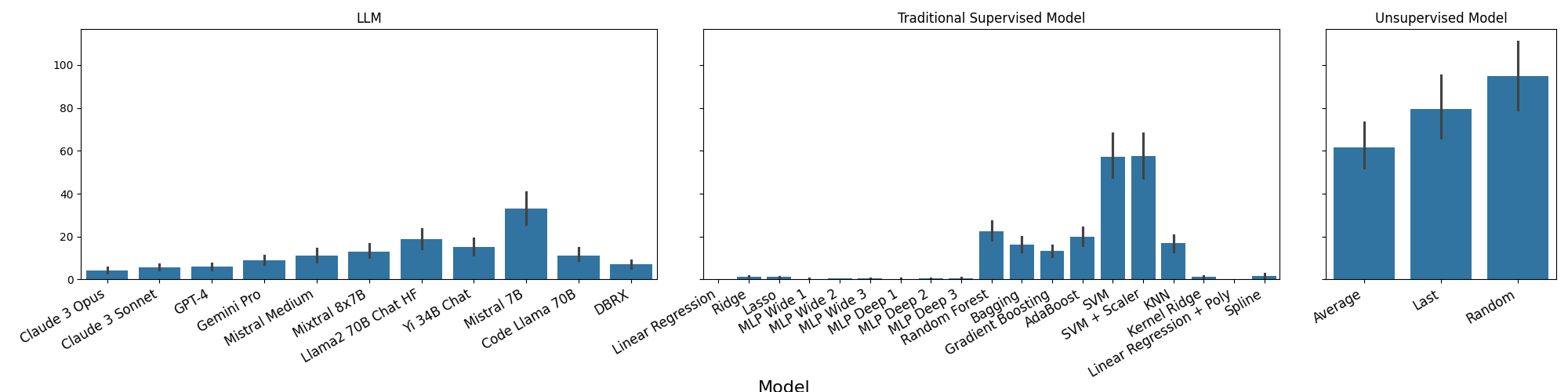
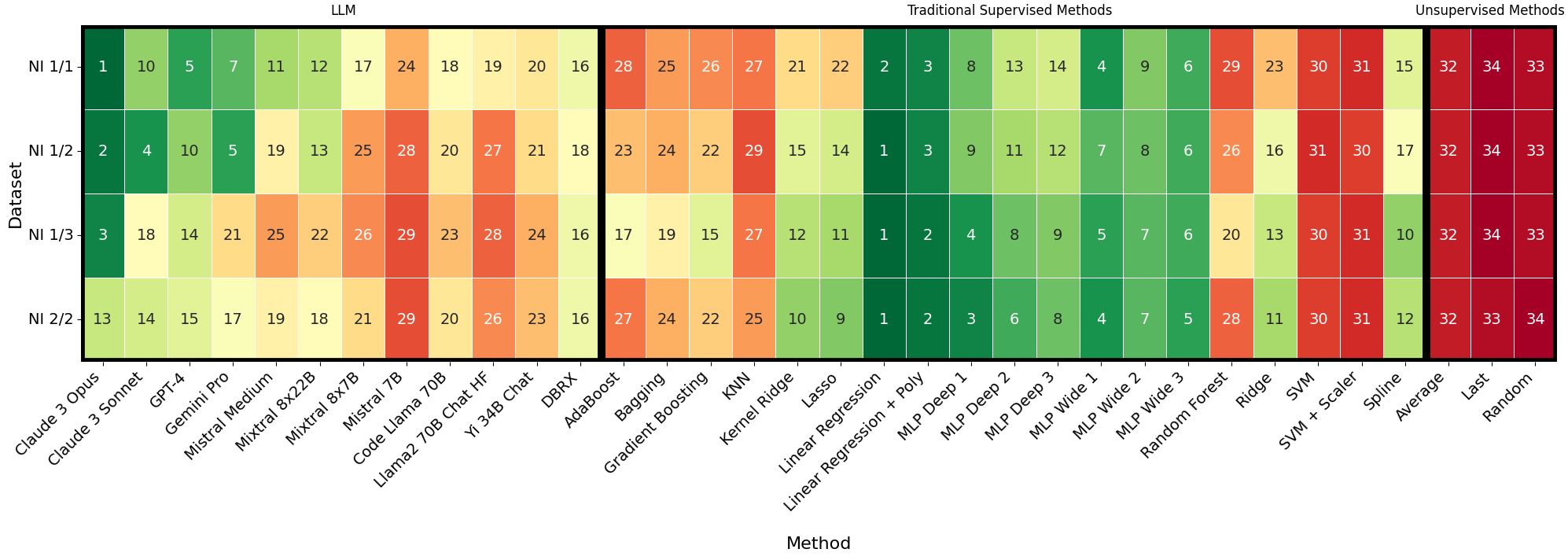
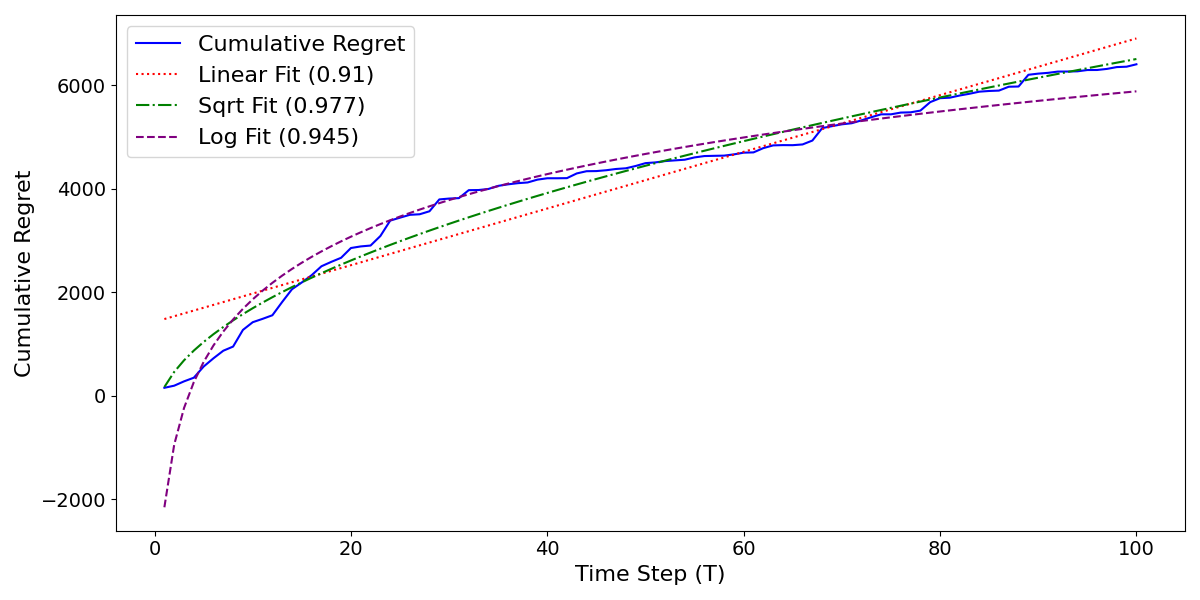
Abstract: We analyze how well pre-trained LLMs (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several LLMs (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of LLMs scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
- Gpt-4 technical report. 2023. URL https://api.semanticscholar.org/CorpusID:257532815.
- Transformers learn to implement preconditioned gradient descent for in-context learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=LziniAXEI9.
- Yi: Open foundation models by 01.ai, 2024.
- What learning algorithm is in-context learning? investigations with linear models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=0g0X4H8yN4I.
- The falcon series of open language models. ArXiv, abs/2311.16867, 2023. URL https://api.semanticscholar.org/CorpusID:265466629.
- Anthropic. The claude 3 model family: Opus, sonnet, haiku. URL https://api.semanticscholar.org/CorpusID:268232499.
- Transformers as statisticians: Provable in-context learning with in-context algorithm selection. In Workshop on Efficient Systems for Foundation Models @ ICML2023, 2023. URL https://openreview.net/forum?id=vlCG5HKEkI.
- Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological), 57(1):289–300, 1995. ISSN 00359246. URL http://www.jstor.org/stable/2346101.
- Understanding in-context learning in transformers and LLMs by learning to learn discrete functions. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ekeyCgeRfC.
- L. Breiman. Random forests. Machine Learning, 45:5–32, 2001. URL https://api.semanticscholar.org/CorpusID:89141.
- Leo Breiman. Bagging predictors. Machine Learning, 24(2):123–140, 1996. ISSN 1573-0565. doi: 10.1007/bf00058655. URL http://dx.doi.org/10.1007/BF00058655.
- Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 1877–1901. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Data distributional properties drive emergent in-context learning in transformers, 2022.
- Transformers implement functional gradient descent to learn non-linear functions in context. ArXiv, abs/2312.06528, 2023. URL https://api.semanticscholar.org/CorpusID:266162320.
- Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, pp. 4005–4019, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.247. URL https://aclanthology.org/2023.findings-acl.247.
- Olive Jean Dunn. Multiple comparisons among means. Journal of the American Statistical Association, 56:52–64, 1961. URL https://api.semanticscholar.org/CorpusID:122009246.
- Online meta-learning. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 1920–1930. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/finn19a.html.
- Jerome H. Friedman. Multivariate Adaptive Regression Splines. The Annals of Statistics, 19(1):1 – 67, 1991. doi: 10.1214/aos/1176347963. URL https://doi.org/10.1214/aos/1176347963.
- Jerome H. Friedman. Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29:1189–1232, 2001. URL https://api.semanticscholar.org/CorpusID:39450643.
- What can transformers learn in-context? a case study of simple function classes. ArXiv, abs/2208.01066, 2022. URL https://api.semanticscholar.org/CorpusID:251253368.
- Time travel in LLMs: Tracing data contamination in large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=2Rwq6c3tvr.
- How do transformers learn in-context beyond simple functions? a case study on learning with representations. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ikwEDva1JZ.
- Understanding in-context learning via supportive pretraining data. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12660–12673, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.708. URL https://aclanthology.org/2023.acl-long.708.
- In-context learning creates task vectors. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 9318–9333, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.624. URL https://aclanthology.org/2023.findings-emnlp.624.
- Multilayer feedforward networks are universal approximators. Neural Netw., 2(5):359–366, jul 1989. ISSN 0893-6080.
- In-context convergence of transformers. ArXiv, abs/2310.05249, 2023. URL https://api.semanticscholar.org/CorpusID:263829335.
- Mixtral of experts. ArXiv, abs/2401.04088, 2024. URL https://api.semanticscholar.org/CorpusID:266844877.
- Mistral 7b. ArXiv, abs/2310.06825, 2023. URL https://api.semanticscholar.org/CorpusID:263830494.
- In-context learning learns label relationships but is not conventional learning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=YPIA7bgd5y.
- Training nonlinear transformers for efficient in-context learning: A theoretical learning and generalization analysis. ArXiv, abs/2402.15607, 2024.
- In-context vectors: Making in context learning more effective and controllable through latent space steering. ArXiv, abs/2311.06668, 2023. URL https://api.semanticscholar.org/CorpusID:265149781.
- One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=8p3fu56lKc.
- Rethinking the role of demonstrations: What makes in-context learning work? In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11048–11064, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.759. URL https://aclanthology.org/2022.emnlp-main.759.
- Large language models as general pattern machines. In 7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/forum?id=RcZMI8MSyE.
- In-context learning and gradient descent revisited. ArXiv, abs/2311.07772, 2023.
- Francesco Orabona. A modern introduction to online learning. ArXiv, abs/1912.13213, 2019.
- Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 27730–27744. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf.
- What in-context learning “learns” in-context: Disentangling task recognition and task learning. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, pp. 8298–8319, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.527. URL https://aclanthology.org/2023.findings-acl.527.
- Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- RWKV: Reinventing RNNs for the transformer era. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 14048–14077, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.936. URL https://aclanthology.org/2023.findings-emnlp.936.
- Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning, 2023a. URL https://api.semanticscholar.org/CorpusID:257050308.
- StripedHyena: Moving Beyond Transformers with Hybrid Signal Processing Models, 12 2023b. URL https://github.com/togethercomputer/stripedhyena.
- Impact of pretraining term frequencies on few-shot numerical reasoning. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 840–854, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.59. URL https://aclanthology.org/2022.findings-emnlp.59.
- Code llama: Open foundation models for code. ArXiv, abs/2308.12950, 2023. URL https://api.semanticscholar.org/CorpusID:261100919.
- David Ruppert. The elements of statistical learning: Data mining, inference, and prediction. Journal of the American Statistical Association, 99:567 – 567, 2004. URL https://api.semanticscholar.org/CorpusID:118901444.
- NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 10776–10787, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.722. URL https://aclanthology.org/2023.findings-emnlp.722.
- Robert E. Schapire. The strength of weak learnability. Machine Learning, 5:197–227, 1989. URL https://api.semanticscholar.org/CorpusID:6207294.
- Do pretrained transformers really learn in-context by gradient descent? ArXiv, abs/2310.08540, 2023. URL https://api.semanticscholar.org/CorpusID:268499126.
- Gemini: A family of highly capable multimodal models, 2023.
- Scan and snap: Understanding training dynamics and token composition in 1-layer transformer. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=l3HUgVHqGQ.
- Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023. URL https://api.semanticscholar.org/CorpusID:259950998.
- Linear transformers are versatile in-context learners. ArXiv, abs/2402.14180, 2024.
- Transformers learn in-context by gradient descent. In International Conference on Machine Learning, 2022. URL https://api.semanticscholar.org/CorpusID:254685643.
- Uncovering mesa-optimization algorithms in transformers. ArXiv, abs/2309.05858, 2023.
- Larger language models do in-context learning differently. ArXiv, abs/2303.03846, 2023. URL https://api.semanticscholar.org/CorpusID:257378479.
- The learnability of in-context learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=f3JNQd7CHM.
- An explanation of in-context learning as implicit bayesian inference. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=RdJVFCHjUMI.
- Benefits of transformer: In-context learning in linear regression tasks with unstructured data. ArXiv, abs/2402.00743, 2024.
- Trained transformers learn linear models in-context. In R0-FoMo:Robustness of Few-shot and Zero-shot Learning in Large Foundation Models, 2023. URL https://openreview.net/forum?id=MpDSo3Rglq.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

