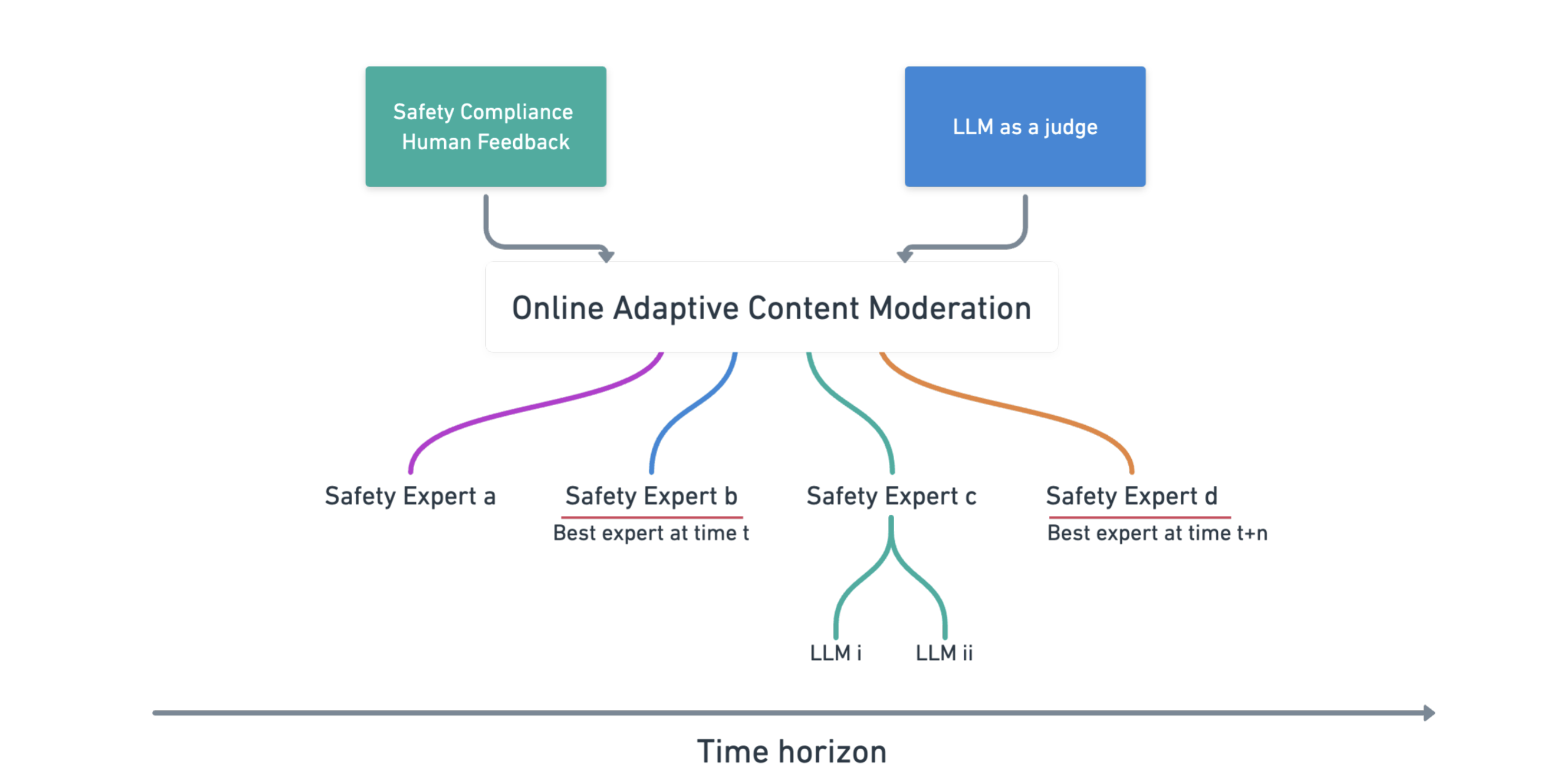
AEGIS: Online Adaptive AI Content Safety Moderation with Ensemble of LLM Experts
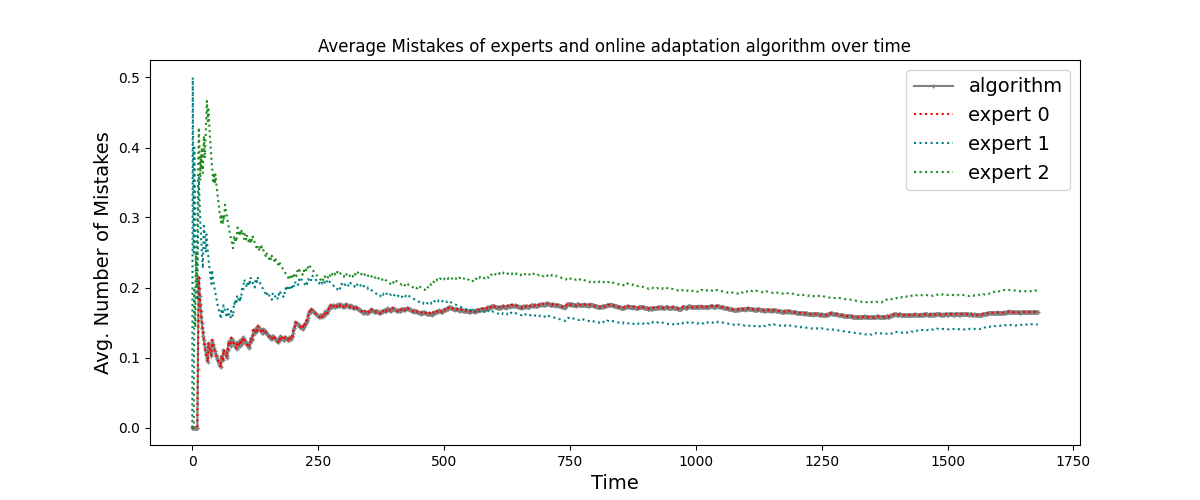
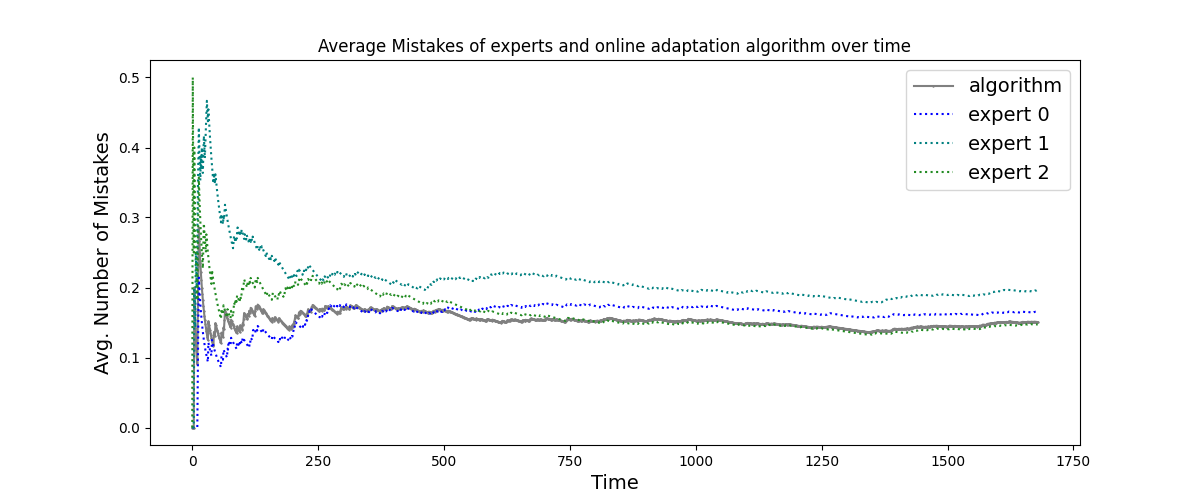
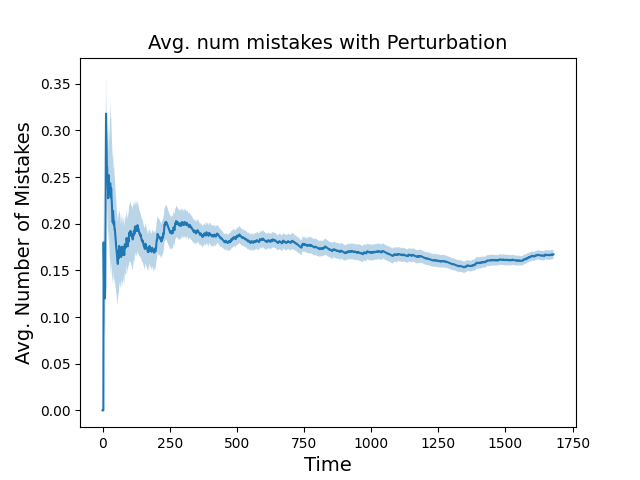
Abstract: As LLMs and generative AI become more widespread, the content safety risks associated with their use also increase. We find a notable deficiency in high-quality content safety datasets and benchmarks that comprehensively cover a wide range of critical safety areas. To address this, we define a broad content safety risk taxonomy, comprising 13 critical risk and 9 sparse risk categories. Additionally, we curate AEGISSAFETYDATASET, a new dataset of approximately 26, 000 human-LLM interaction instances, complete with human annotations adhering to the taxonomy. We plan to release this dataset to the community to further research and to help benchmark LLM models for safety. To demonstrate the effectiveness of the dataset, we instruction-tune multiple LLM-based safety models. We show that our models (named AEGISSAFETYEXPERTS), not only surpass or perform competitively with the state-of-the-art LLM-based safety models and general purpose LLMs, but also exhibit robustness across multiple jail-break attack categories. We also show how using AEGISSAFETYDATASET during the LLM alignment phase does not negatively impact the performance of the aligned models on MT Bench scores. Furthermore, we propose AEGIS, a novel application of a no-regret online adaptation framework with strong theoretical guarantees, to perform content moderation with an ensemble of LLM content safety experts in deployment
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Red-teaming large language models using chain of utterances for safety-alignment. arXiv preprint arXiv:2308.09662, 2023.
- Prediction, learning, and games. Cambridge university press, 2006.
- How to use expert advice. Journal of the ACM (JACM), 44(3):427–485, 1997.
- Improved second-order bounds for prediction with expert advice. Machine Learning, 66:321–352, 2007.
- Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419, 2023.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf. arXiv preprint arXiv:2310.05344, 2023.
- Emil Julius Gumbel. Les valeurs extrêmes des distributions statistiques. In Annales de l’institut Henri Poincaré, volume 5, pp. 115–158, 1935.
- James Hannan. Approximation to bayes risk in repeated play. Contributions to the Theory of Games, 3(2):97–139, 1957.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674, 2023.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- A new generation of perspective api: Efficient multilingual character-level transformers. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 3197–3207, 2022.
- Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation. arXiv preprint arXiv:2310.17389, 2023.
- The weighted majority algorithm. Information and computation, 108(2):212–261, 1994.
- A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp. 15009–15018, 2023.
- Tree of attacks: Jailbreaking black-box llms automatically. arXiv preprint arXiv:2312.02119, 2023.
- Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Trustllm: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561, 2024.
- Cappy: Outperforming and boosting large multi-task lms with a small scorer. Advances in Neural Information Processing Systems, 36, 2024.
- Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- The art of defending: A systematic evaluation and analysis of llm defense strategies on safety and over-defensiveness. arXiv preprint arXiv:2401.00287, 2023.
- Simplesafetytests: a test suite for identifying critical safety risks in large language models. arXiv preprint arXiv:2311.08370, 2023.
- Vladimir G Vovk. A game of prediction with expert advice. In Proceedings of the eighth annual conference on Computational learning theory, pp. 51–60, 1995.
- Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36, 2024.
- Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- Rigorllm: Resilient guardrails for large language models against undesired content. arXiv preprint arXiv:2403.13031, 2024.
- Biasx:” thinking slow” in toxic content moderation with explanations of implied social biases. arXiv preprint arXiv:2305.13589, 2023.
- Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

