- The paper introduces LISA, a novel approach that selectively freezes less critical layers to enhance memory efficiency during LLM fine-tuning.
- It employs layerwise importance sampling with AdamW to achieve significant memory savings while maintaining or improving model performance compared to LoRA.
- Empirical results demonstrate up to 36% performance gains on benchmarks like MT-Bench, confirming LISA's effectiveness in balancing memory and accuracy.
LISA: Layerwise Importance Sampling for Memory-Efficient LLM Fine-Tuning
Introduction
The paper "LISA: Layerwise Importance Sampling for Memory-Efficient LLM Fine-Tuning" (2403.17919) introduces a novel approach named Layerwise Importance Sampled AdamW (LISA). The motivation behind LISA is to address the significant memory consumption issues faced by LLMs during fine-tuning. While techniques like Low-Rank Adaptation (LoRA) offer memory savings, they often fall short of achieving performance comparable to full parameter tuning. LISA proposes an alternative that surpasses both LoRA and full parameter tuning in various tasks with similar or reduced memory costs.
Methodology
Observations and Motivation
In exploring LoRA's performance, the paper identifies a skewed distribution of weight norms across layers during training. Specifically, certain layers, such as the bottom and top layers, dominate weight updates, while intermediate layers experience minimal changes.
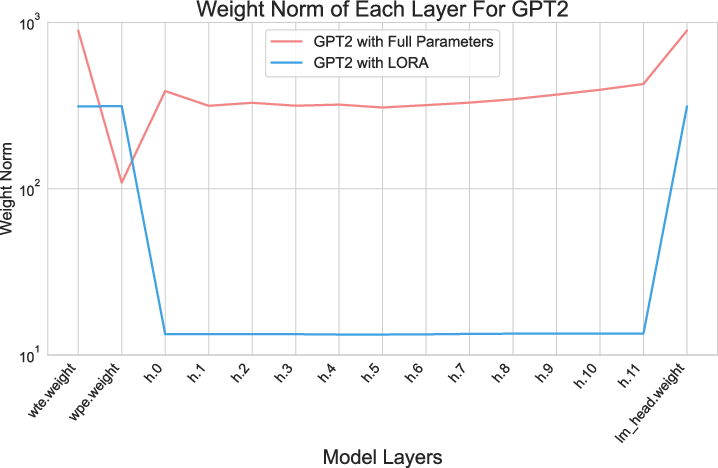
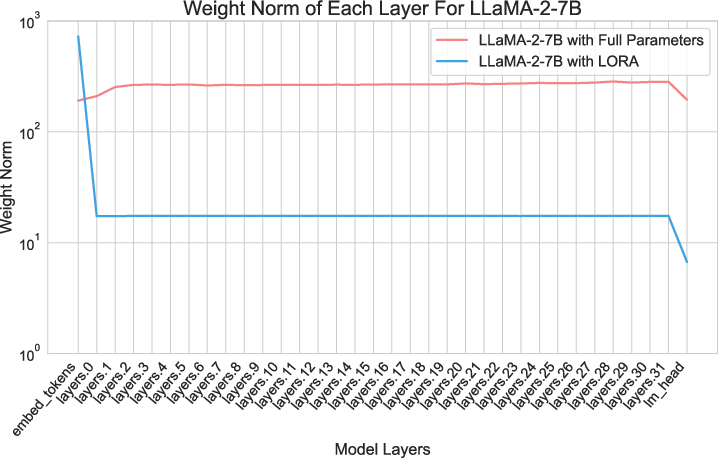
Figure 1: Layer-wise weight norms during training of GPT2 and LLaMA-2-7B Model with LoRA and Full Parameters training.
This observation drives the key insight behind LISA: not all layers hold equal importance during updates. This motivates the adoption of an importance sampling strategy, selectively freezing layers deemed less critical during optimization. This approach effectively imitates LoRA’s pattern without its inherent limitations in low-rank representation.
Layerwise Importance Sampled AdamW (LISA)
LISA introduces a simple method employing importance sampling where layers are randomly frozen based on their computed importance. The method strategically updates essential layers to achieve memory-efficient training without sacrificing performance. LISA’s sampling configuration, with probabilities assigned to each layer, ensures that the total memory footprint aligns closely with LoRA, but with distinct performance advantages.
Experimental Results
The empirical analysis demonstrates LISA's efficacy across various LLMs and tasks. Experiments cover moderate scale fine-tuning datasets like Alpaca-GPT4, employing evaluation benchmarks such as MT-Bench, GSM8K, and PubMedQA.
Memory Efficiency
LISA achieves considerable memory savings, comparable or superior to LoRA. The memory reduction results from the selective updating of layers, which minimizes unnecessary parameter adjustments.
In the evaluation on instruction-following tasks, LISA consistently exceeds LoRA by 8%-36% in MT-Bench scores. In large models like LLaMA-2-70B, it performs on par or better than LoRA in terms of both domain-specific tasks and general fine-tuning tasks.
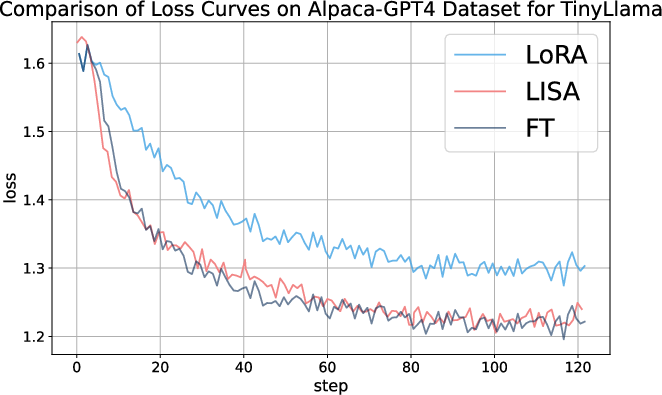
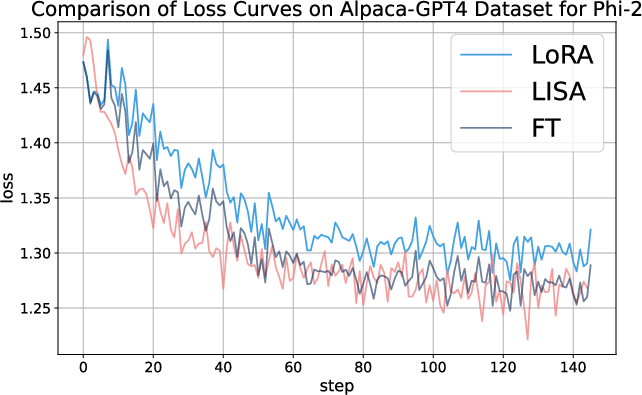
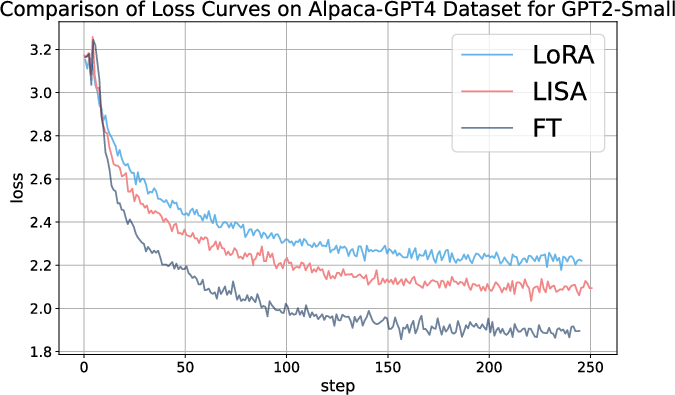
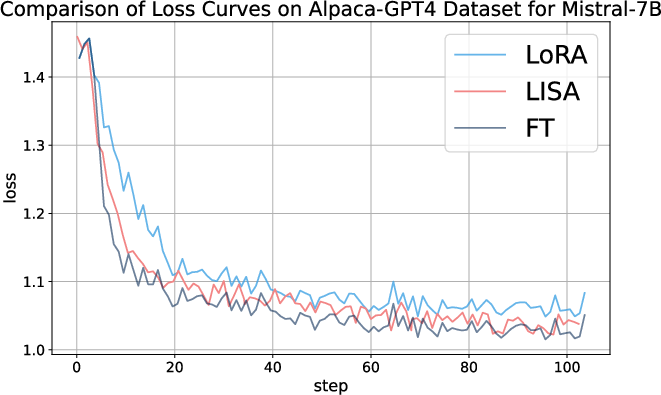
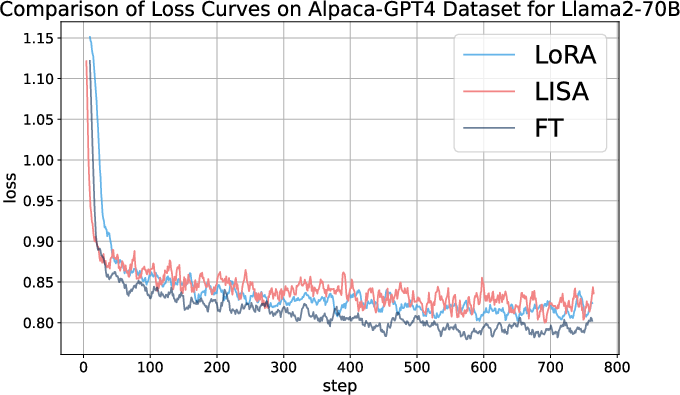
Figure 2: Loss curves for LoRA, LISA and full-parameter tuning on the Alpaca-GPT4 dataset across different models.
Ablation Studies
The paper explores the impact of LISA's hyperparameters, such as the number of sampling layers (gamma) and the sampling period (K). It concludes that a higher number of sampled layers and a longer sampling period substantially enhance performance, though proper tuning is critical for maximizing efficiency.
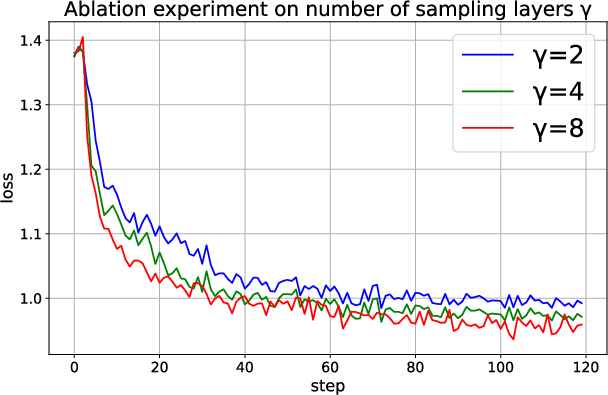
Figure 3: Comparison of loss curves for the gamma (number of sampling layers) ablation experiment.
Figure 4: Comparison of loss curves for the sampling period K ablation experiment.
Conclusion
LISA emerges as an effective alternative to existing parameter-efficient fine-tuning strategies, presenting substantial benefits in both memory efficiency and task performance. By leveraging layerwise importance sampling, LISA achieves significant strides in memory consumption reduction while either matching or surpassing the performance of full parameter training and LoRA. Future explorations could involve refining the importance sampling strategy to further boost the optimization efficiency and exploring integrations with advanced memory reduction techniques.

