ReAct Meets ActRe: When Language Agents Enjoy Training Data Autonomy
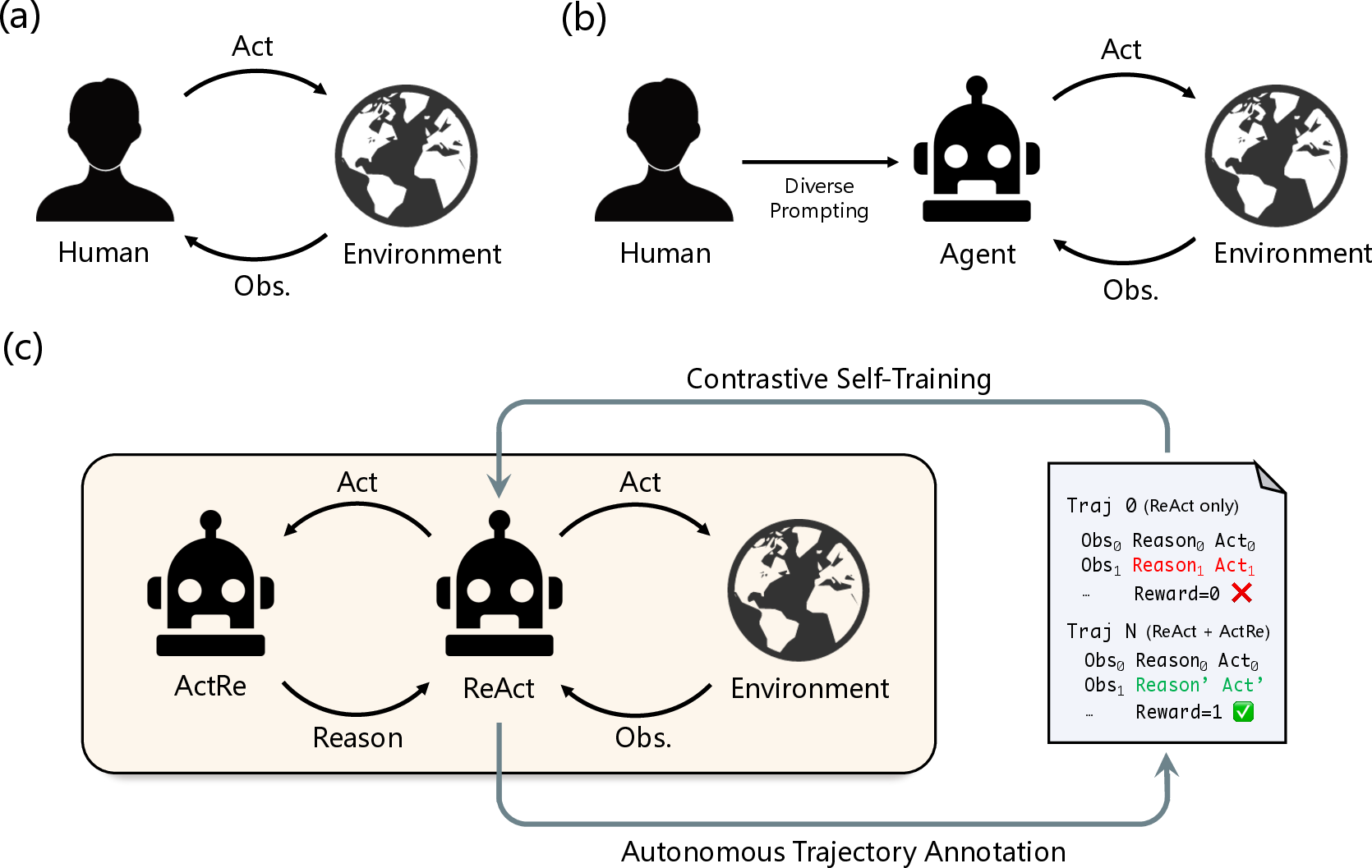
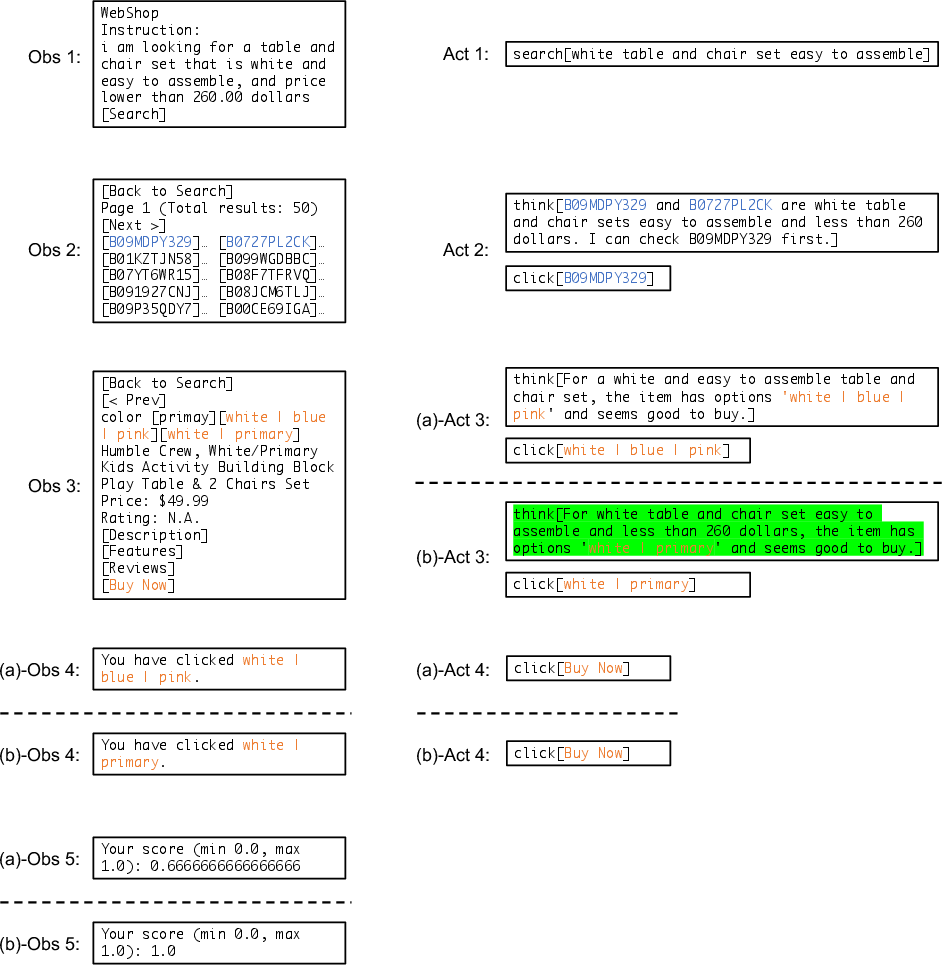
Abstract: Language agents have demonstrated autonomous decision-making abilities by reasoning with foundation models. Recently, efforts have been made to train language agents for performance improvement, with multi-step reasoning and action trajectories as the training data. However, collecting such trajectories still requires considerable human effort, by either artificial annotation or implementations of diverse prompting frameworks. In this work, we propose A$3$T, a framework that enables the Autonomous Annotation of Agent Trajectories in the style of ReAct. The central role is an ActRe prompting agent, which explains the reason for an arbitrary action. When randomly sampling an external action, the ReAct-style agent could query the ActRe agent with the action to obtain its textual rationales. Novel trajectories are then synthesized by prepending the posterior reasoning from ActRe to the sampled action. In this way, the ReAct-style agent executes multiple trajectories for the failed tasks, and selects the successful ones to supplement its failed trajectory for contrastive self-training. Realized by policy gradient methods with binarized rewards, the contrastive self-training with accumulated trajectories facilitates a closed loop for multiple rounds of language agent self-improvement. We conduct experiments using QLoRA fine-tuning with the open-sourced Mistral-7B-Instruct-v0.2. In AlfWorld, the agent trained with A$3$T obtains a 1-shot success rate of 96%, and 100% success with 4 iterative rounds. In WebShop, the 1-shot performance of the A$3$T agent matches human average, and 4 rounds of iterative refinement lead to the performance approaching human experts. A$3$T agents significantly outperform existing techniques, including prompting with GPT-4, advanced agent frameworks, and fully fine-tuned LLMs.
- Rest meets react: Self-improvement for multi-step reasoning llm agent. arXiv preprint arXiv:2312.10003, 2023.
- Fireact: Toward language agent fine-tuning. arXiv preprint arXiv:2310.05915, 2023.
- Self-play fine-tuning converts weak language models to strong language models, 2024.
- Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023.
- Multimodal web navigation with instruction-finetuned foundation models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=efFmBWioSc.
- V-star: Training verifiers for self-taught reasoners. arXiv preprint arXiv:2402.06457, 2024.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
- Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267, 2023.
- Reason for future, act for now: A principled framework for autonomous llm agents with provable sample efficiency. arXiv preprint arXiv:2309.17382, 2023.
- Agentlite: A lightweight library for building and advancing task-oriented llm agent system. arXiv preprint arXiv:2402.15538, 2024.
- Agentboard: An analytical evaluation board of multi-turn llm agents. arXiv preprint arXiv:2401.13178, 2024.
- Language models are few-shot butlers. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 9312–9318, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.734. URL https://aclanthology.org/2021.emnlp-main.734.
- Large language models as general pattern machines. In Proceedings of the 7th Conference on Robot Learning (CoRL), 2023.
- OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023. doi: 10.48550/ARXIV.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
- Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 2023.
- Reflexion: language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=vAElhFcKW6.
- ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. In Proceedings of the International Conference on Learning Representations (ICLR), 2021. URL https://arxiv.org/abs/2010.03768.
- Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585, 2023.
- Trial and error: Exploration-based trajectory optimization for llm agents. arXiv preprint arXiv:2403.02502, 2024.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Openchat: Advancing open-source language models with mixed-quality data. In The Twelfth International Conference on Learning Representations, 2024.
- Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv: Arxiv-2305.16291, 2023.
- Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992.
- Os-copilot: Towards generalist computer agents with self-improvement, 2024.
- Towards unified alignment between agents, humans, and environment. arXiv preprint arXiv:2402.07744, 2024.
- Webshop: Towards scalable real-world web interaction with grounded language agents. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 20744–20757. Curran Associates, Inc., 2022.
- React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=WE_vluYUL-X.
- Agent lumos: Unified and modular training for open-source language agents. arXiv preprint arXiv:2311.05657, 2023.
- Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024.
- Agenttuning: Enabling generalized agent abilities for llms. arXiv preprint arXiv:2310.12823, 2023.
- Agentohana: Design unified data and training pipeline for effective agent learning. arXiv preprint arXiv:2402.15506, 2024.
- Gpt-4v(ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614, 2024.
- Language agent tree search unifies reasoning acting and planning in language models, 2023a.
- Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36, 2023b.
- Archer: Training language model agents via hierarchical multi-turn rl. arXiv preprint arXiv:2402.19446, 2024.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

