mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
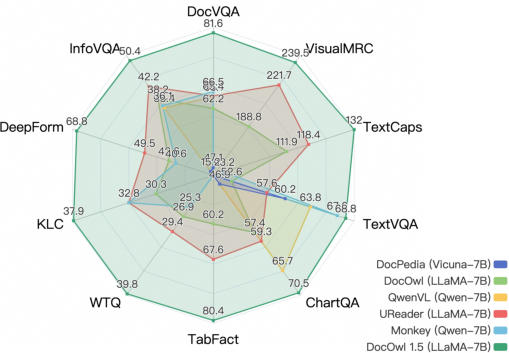
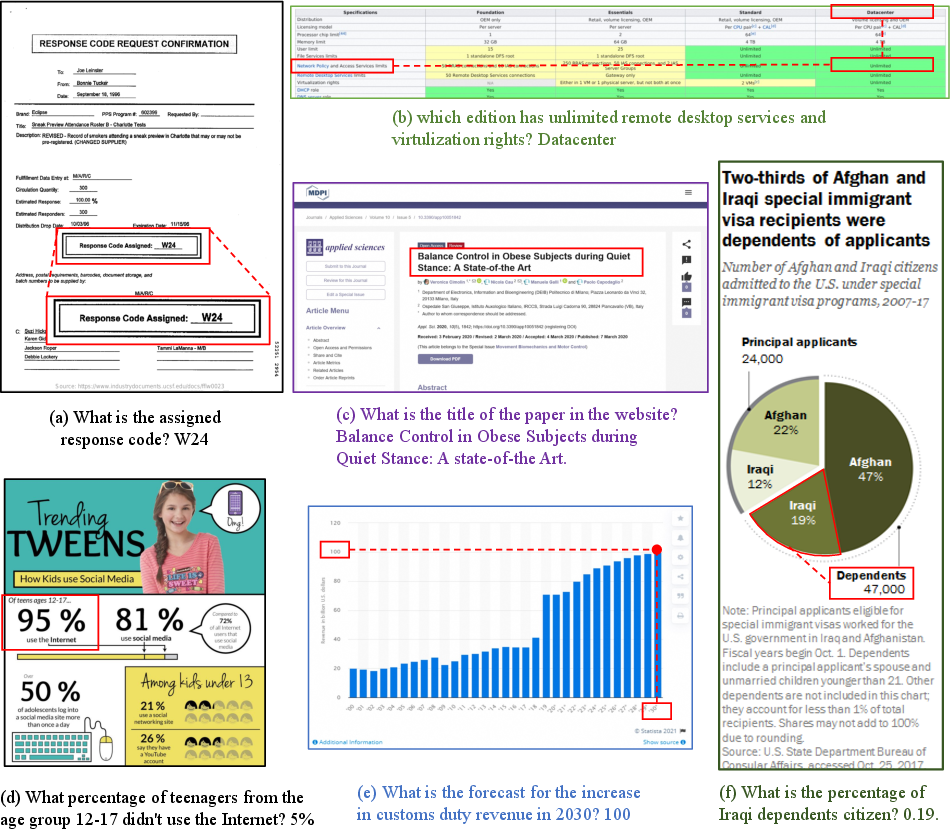
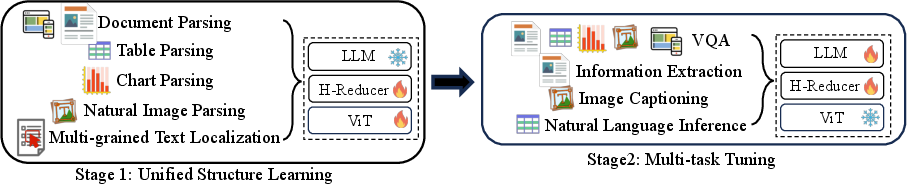
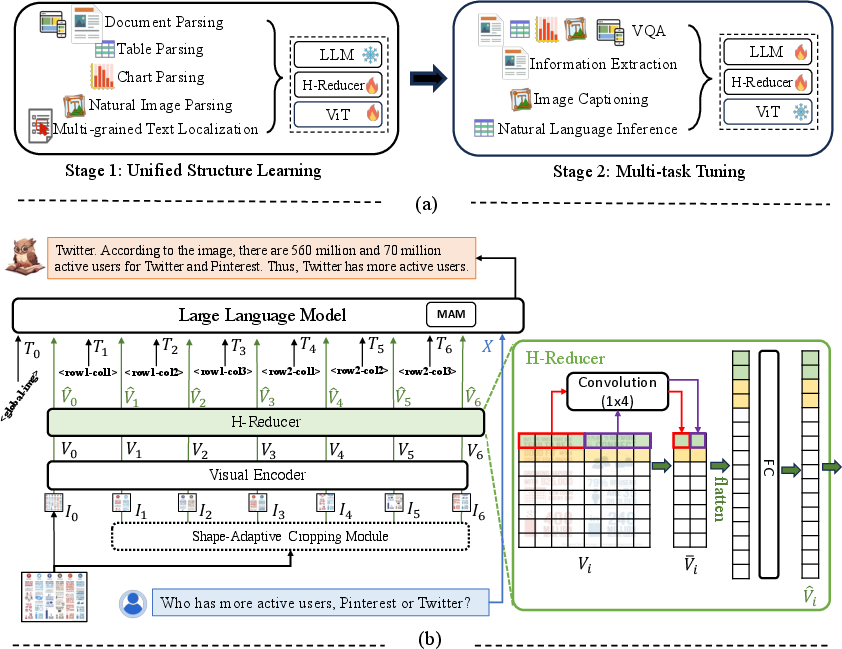
Abstract: Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal LLMs (MLLMs) for Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks. Our codes, models, and datasets are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5.
- Flamingo: a visual language model for few-shot learning. ArXiv, abs/2204.14198, 2022.
- Qwen technical report. arXiv preprint arXiv:2309.16609, 2023a.
- Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023b.
- DUE: end-to-end document understanding benchmark. In NeurIPS Datasets and Benchmarks, 2021.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/coyo-dataset, 2022.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR, pages 3558–3568. Computer Vision Foundation / IEEE, 2021.
- Tabfact : A large-scale dataset for table-based fact verification. In International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, April 2020.
- Websrc: A dataset for web-based structural reading comprehension. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4173–4185, 2021.
- Instructblip: Towards general-purpose vision-language models with instruction tuning. CoRR, abs/2305.06500, 2023.
- TURL: table understanding through representation learning. SIGMOD Rec., 51(1):33–40, 2022.
- An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR. OpenReview.net, 2021.
- Docpedia: Unleashing the power of large multimodal model in the frequency domain for versatile document understanding. CoRR, abs/2311.11810, 2023.
- Evaluation of deep convolutional nets for document image classification and retrieval. In ICDAR, pages 991–995. IEEE Computer Society, 2015.
- Cogagent: A visual language model for GUI agents. CoRR, abs/2312.08914, 2023.
- Question-controlled text-aware image captioning. In ACM Multimedia, pages 3097–3105. ACM, 2021.
- mplug-paperowl: Scientific diagram analysis with the multimodal large language model. arXiv preprint arXiv:2311.18248, 2023.
- Layoutlmv3: Pre-training for document AI with unified text and image masking. In ACM Multimedia, pages 4083–4091. ACM, 2022.
- DVQA: understanding data visualizations via question answering. In CVPR, pages 5648–5656. Computer Vision Foundation / IEEE Computer Society, 2018.
- Figureqa: An annotated figure dataset for visual reasoning. In ICLR (Workshop). OpenReview.net, 2018.
- Chart-to-text: A large-scale benchmark for chart summarization. In ACL (1), pages 4005–4023. Association for Computational Linguistics, 2022.
- Ocr-free document understanding transformer. In ECCV (28), volume 13688 of Lecture Notes in Computer Science, pages 498–517. Springer, 2022.
- Pix2struct: Screenshot parsing as pretraining for visual language understanding. In ICML, volume 202 of Proceedings of Machine Learning Research, pages 18893–18912. PMLR, 2023.
- BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. CoRR, abs/2301.12597, 2023a.
- Monkey: Image resolution and text label are important things for large multi-modal models. CoRR, abs/2311.06607, 2023b.
- Improved baselines with visual instruction tuning. CoRR, abs/2310.03744, 2023a.
- Visual instruction tuning. CoRR, abs/2304.08485, 2023b.
- On the hidden mystery of ocr in large multimodal models. arXiv preprint arXiv:2305.07895, 2023c.
- Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In ACL (Findings), pages 2263–2279. Association for Computational Linguistics, 2022.
- Docvqa: A dataset for VQA on document images. In WACV, pages 2199–2208. IEEE, 2021.
- Infographicvqa. In WACV, pages 2582–2591. IEEE, 2022.
- Plotqa: Reasoning over scientific plots. In WACV, pages 1516–1525. IEEE, 2020.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Compositional semantic parsing on semi-structured tables. In ACL (1), pages 1470–1480. The Association for Computer Linguistics, 2015.
- Kosmos-2: Grounding multimodal large language models to the world. CoRR, abs/2306.14824, 2023.
- Learning transferable visual models from natural language supervision. In ICML, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021.
- LAION-5B: an open large-scale dataset for training next generation image-text models. In NeurIPS, 2022.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL (1), pages 2556–2565. Association for Computational Linguistics, 2018.
- Textcaps: A dataset for image captioning with reading comprehension. In ECCV (2), volume 12347 of Lecture Notes in Computer Science, pages 742–758. Springer, 2020.
- Towards VQA models that can read. In CVPR, pages 8317–8326. Computer Vision Foundation / IEEE, 2019.
- Kleister: Key information extraction datasets involving long documents with complex layouts. In ICDAR (1), volume 12821 of Lecture Notes in Computer Science, pages 564–579. Springer, 2021.
- S Svetlichnaya. Deepform: Understand structured documents at scale, 2020.
- Visualmrc: Machine reading comprehension on document images. In AAAI, pages 13878–13888. AAAI Press, 2021.
- Vistext: A benchmark for semantically rich chart captioning. In ACL (1), pages 7268–7298. Association for Computational Linguistics, 2023a.
- Unifying vision, text, and layout for universal document processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19254–19264, 2023b.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Ccpdf: Building a high quality corpus for visually rich documents from web crawl data. In ICDAR (3), volume 14189 of Lecture Notes in Computer Science, pages 348–365. Springer, 2023.
- Vicuna. Vicuna: An open chatbot impressing gpt-4. https://github.com/lm-sys/FastChat, 2023.
- OFA: unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In ICML, volume 162 of Proceedings of Machine Learning Research, pages 23318–23340. PMLR, 2022.
- Cogvlm: Visual expert for pretrained language models. CoRR, abs/2311.03079, 2023a.
- Layout and task aware instruction prompt for zero-shot document image question answering. CoRR, abs/2306.00526, 2023b.
- E2E-VLP: end-to-end vision-language pre-training enhanced by visual learning. In ACL/IJCNLP (1), pages 503–513. Association for Computational Linguistics, 2021a.
- Layoutlmv2: Multi-modal pre-training for visually-rich document understanding. In ACL/IJCNLP (1), pages 2579–2591. Association for Computational Linguistics, 2021b.
- TAP: text-aware pre-training for text-vqa and text-caption. In CVPR, pages 8751–8761. Computer Vision Foundation / IEEE, 2021.
- mplug-docowl: Modularized multimodal large language model for document understanding. CoRR, abs/2307.02499, 2023a.
- Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model. In EMNLP (Findings), pages 2841–2858. Association for Computational Linguistics, 2023b.
- mplug-owl: Modularization empowers large language models with multimodality. CoRR, abs/2304.14178, 2023c.
- mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. CoRR, abs/2311.04257, 2023d.
- Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601, 2024.
- MPMQA: multimodal question answering on product manuals. CoRR, abs/2304.09660, 2023a.
- Tablellama: Towards open large generalist models for tables. CoRR, abs/2311.09206, 2023b.
- A survey of large language models. CoRR, abs/2303.18223, 2023.
- Image-based table recognition: Data, model, and evaluation. In ECCV (21), volume 12366 of Lecture Notes in Computer Science, pages 564–580. Springer, 2020.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.