- The paper demonstrates how fine-tuning LLMs with a mix of oracle and distractor documents improves domain-specific retrieval accuracy.
- RAFT employs a novel retrieval-augmented fine-tuning methodology that simulates open-book testing to enhance reasoning and citation precision.
- Experimental results on datasets like PubMed QA and HotpotQA show RAFT’s robust performance compared to traditional fine-tuning approaches.
Adapting LLMs to Domain-Specific Retrieval-Augmented Generation with RAFT
Introduction
The paper "RAFT: Adapting LLM to Domain Specific RAG" presents a novel approach for fine-tuning LLMs in specialized domains using Retrieval-Augmented Generation (RAG). This approach, Retrieval Augmented Fine Tuning (RAFT), is designed to improve LLM performance in domain-specific, open-book settings. The primary goal is to enhance the model's ability to reason and cite relevant documents to answer questions accurately.
Challenges in Adaptation
LLMs are increasingly pivotal in tasks within specialized domains, requiring not just general knowledge but high precision from specific document sets, such as enterprise documentation or recent publication databases. In such settings, fine-tuning can be implemented either through in-context learning with RAG or supervised learning. In-context learning with RAG allows the model to reference documents during question answering. However, it does not necessarily prepare models for the open-book nature of test settings where document relevance is critical.
Supervised fine-tuning affords pattern recognition within fixed domains, aligning with end-user needs but often failing to optimize document retrieval quality during training. These challenges are akin to preparing for an open-book exam, wherein RAFT simulates effective study practices by focusing on reasoning and relevant citations.
RAFT Methodology
RAFT innovatively combines supervised fine-tuning with RAG by training the model to discern and cite relevant documents while ignoring distractor documents. This approach ensures robustness against retrieval inaccuracies, fostering domain-specific expertise without forgoing general retrieval efficiency. The training data is curated to include both ‘oracle’ documents containing relevant information and distractor documents irrelevant to the query context. This dual document strategy forces models to distinguish between pertinent and non-pertinent documents during training.

Figure 1: RAFT approach leverages fine-tuning with question-answer pairs while referencing documents in a simulated imperfect retrieval setting to prepare for open-book exam settings.
Experimental Evaluation
RAFT was evaluated using multiple datasets, such as PubMed QA, HotpotQA, and Gorilla API Benchmarks, demonstrating significant improvement in domain-specific question answering compared to conventional methods. In these experiments, RAFT consistently outperformed both domain-specific fine-tuning and general RAG settings, underlining its efficacy in specialized contexts.
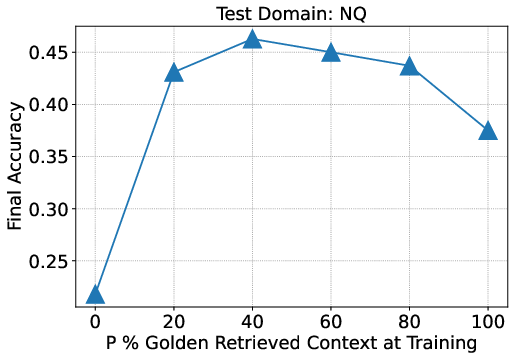
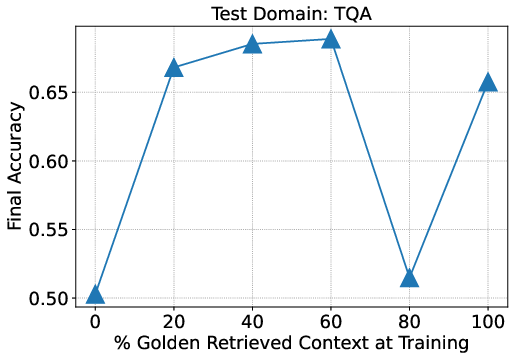
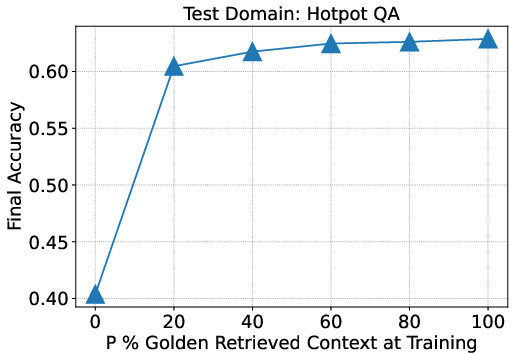
Figure 2: Results on NQ, TQA, and HotpotQA suggest that mixing a fraction of data without the oracle document in its context is helpful for in-domain RAG.
One critical finding was that training with a mix of oracle and distractor documents optimizes retrieval performance, challenging prior assumptions that strict oracle inclusion is optimal. This nuanced training approach improves model robustness, enabling efficient navigation through varying numbers of test documents.
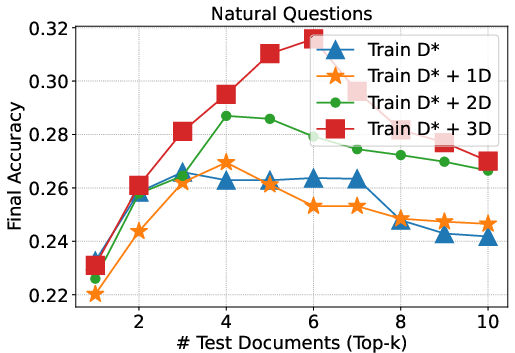
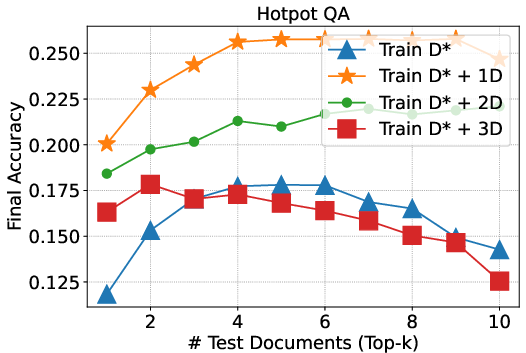
Figure 3: Study on robustness to the varying number of test-time documents provided by the retriever highlights training with 4 documents as optimal for NQ and 2 for HotpotQA.
Implications and Future Work
RAFT offers potent strategies for enhancing LLMs in domain-specific settings by refining their ability to reason through retrieved documents, potentially influencing future LLM developments in specialized applications. Its design principles of leveraging distractor documents and chain-of-thought answers suggest pathways for refined document processing capabilities.
The broader implications suggest the potential for smaller, fine-tuned models to match or exceed general-purpose LLMs on domain-specific tasks. RAFT’s open-source availability encourages widespread application and further experimentation in the domain-specific alignment of LLMs.
Conclusion
RAFT proposes an efficient methodology for adapting LLMs to domain-specific retrieval tasks by integrating distractor documents into fine-tuning processes. The approach successfully enhances retrieval performance and robustness, offering significant potential for future LLM advancements in specialized contexts. The paper's insights underline the necessity for domain-specific adaptation strategies, paving the way for improved application-specific LLM deployments.