Decentralized and Lifelong-Adaptive Multi-Agent Collaborative Learning
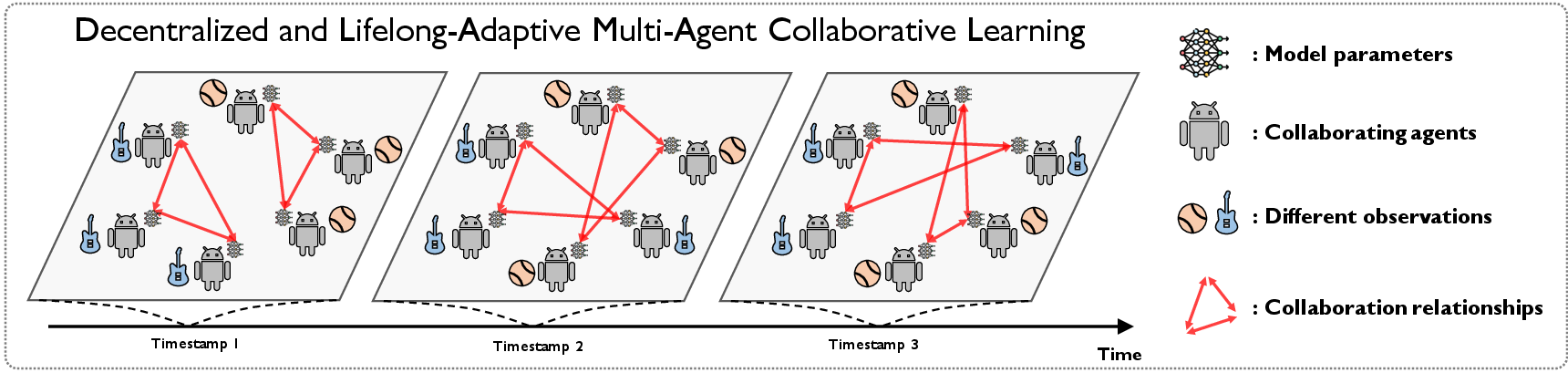
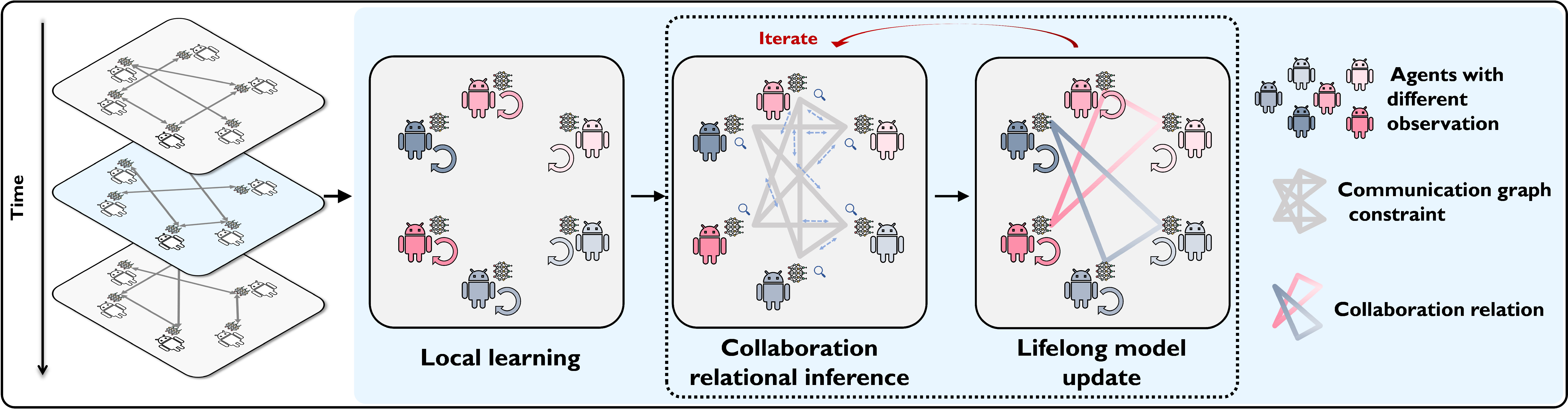
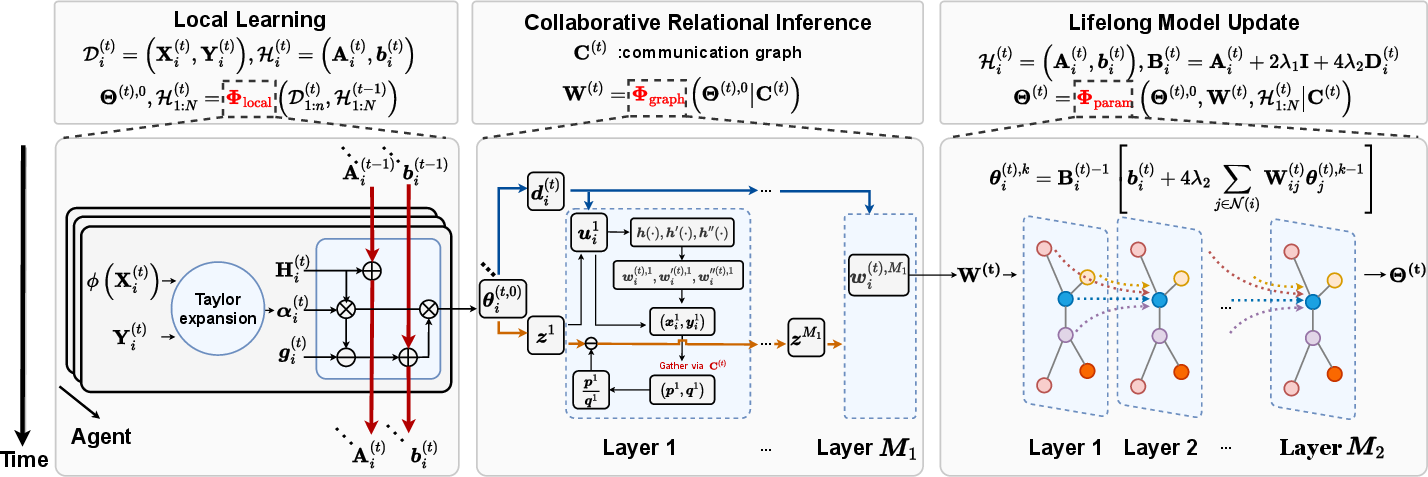
Abstract: Decentralized and lifelong-adaptive multi-agent collaborative learning aims to enhance collaboration among multiple agents without a central server, with each agent solving varied tasks over time. To achieve efficient collaboration, agents should: i) autonomously identify beneficial collaborative relationships in a decentralized manner; and ii) adapt to dynamically changing task observations. In this paper, we propose DeLAMA, a decentralized multi-agent lifelong collaborative learning algorithm with dynamic collaboration graphs. To promote autonomous collaboration relationship learning, we propose a decentralized graph structure learning algorithm, eliminating the need for external priors. To facilitate adaptation to dynamic tasks, we design a memory unit to capture the agents' accumulated learning history and knowledge, while preserving finite storage consumption. To further augment the system's expressive capabilities and computational efficiency, we apply algorithm unrolling, leveraging the advantages of both mathematical optimization and neural networks. This allows the agents to `learn to collaborate' through the supervision of training tasks. Our theoretical analysis verifies that inter-agent collaboration is communication efficient under a small number of communication rounds. The experimental results verify its ability to facilitate the discovery of collaboration strategies and adaptation to dynamic learning scenarios, achieving a 98.80% reduction in MSE and a 188.87% improvement in classification accuracy. We expect our work can serve as a foundational technique to facilitate future works towards an intelligent, decentralized, and dynamic multi-agent system. Code is available at https://github.com/ShuoTang123/DeLAMA.
- A. W. Woolley, C. F. Chabris, A. Pentland, N. Hashmi, and T. W. Malone, “Evidence for a collective intelligence factor in the performance of human groups,” science, vol. 330, no. 6004, pp. 686–688, 2010.
- E. A. Mennis, “The wisdom of crowds: Why the many are smarter than the few and how collective wisdom shapes business, economies, societies, and nations,” Business Economics, vol. 41, no. 4, pp. 63–65, 2006.
- C. Jung, D. Lee, S. Lee, and D. H. Shim, “V2x-communication-aided autonomous driving: System design and experimental validation,” Sensors, vol. 20, no. 10, p. 2903, 2020.
- Y. Li, D. Ma, Z. An, Z. Wang, Y. Zhong, S. Chen, and C. Feng, “V2x-sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 914–10 921, 2022.
- W. Burgard, M. Moors, C. Stachniss, and F. E. Schneider, “Coordinated multi-robot exploration,” IEEE Transactions on robotics, vol. 21, no. 3, pp. 376–386, 2005.
- W. Burgard, M. Moors, D. Fox, R. Simmons, and S. Thrun, “Collaborative multi-robot exploration,” in Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), vol. 1. IEEE, 2000, pp. 476–481.
- B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- Y. Hu, S. Fang, Z. Lei, Y. Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confidence maps,” Advances in neural information processing systems, vol. 35, pp. 4874–4886, 2022.
- J. Zhao, X. Xie, X. Xu, and S. Sun, “Multi-view learning overview: Recent progress and new challenges,” Information Fusion, vol. 38, pp. 43–54, 2017.
- A. Hogan, E. Blomqvist, M. Cochez, C. d’Amato, G. D. Melo, C. Gutierrez, S. Kirrane, J. E. L. Gayo, R. Navigli, S. Neumaier et al., “Knowledge graphs,” ACM Computing Surveys (Csur), vol. 54, no. 4, pp. 1–37, 2021.
- M. Rostami, S. Kolouri, K. Kim, and E. Eaton, “Multi-agent distributed lifelong learning for collective knowledge acquisition,” in Adaptive Agents and Multi-Agent Systems, 2017.
- T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” Proceedings of Machine Learning and Systems, vol. 2, pp. 429–450, 2020.
- L. Collins, H. Hassani, A. Mokhtari, and S. Shakkottai, “Exploiting shared representations for personalized federated learning,” in International Conference on Machine Learning. PMLR, 2021, pp. 2089–2099.
- S. Liu, S. J. Pan, and Q. Ho, “Distributed multi-task relationship learning,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017, pp. 937–946.
- J. Wang, M. Kolar, and N. Srerbo, “Distributed multi-task learning,” in Artificial intelligence and statistics. PMLR, 2016, pp. 751–760.
- A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi-agent communication,” in International Conference on Machine Learning. PMLR, 2019, pp. 1538–1546.
- M. Rangwala and R. Williams, “Learning multi-agent communication through structured attentive reasoning,” Advances in Neural Information Processing Systems, vol. 33, pp. 10 088–10 098, 2020.
- K. Zhang, Z. Yang, and T. Başar, “Multi-agent reinforcement learning: A selective overview of theories and algorithms,” Handbook of reinforcement learning and control, pp. 321–384, 2021.
- Y. Zheng, Y. Zhu, and L. Wang, “Consensus of heterogeneous multi-agent systems,” IET Control Theory & Applications, vol. 5, no. 16, pp. 1881–1888, 2011.
- B. Lindqvist, P. Sopasakis, and G. Nikolakopoulos, “A scalable distributed collision avoidance scheme for multi-agent uav systems,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 9212–9218.
- J. Yu, J. A. Vincent, and M. Schwager, “Dinno: Distributed neural network optimization for multi-robot collaborative learning,” IEEE Robotics and Automation Letters, vol. PP, pp. 1–1, 2021.
- L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehensive survey of continual learning: Theory, method and application,” arXiv preprint arXiv:2302.00487, 2023.
- V. Monga, Y. Li, and Y. C. Eldar, “Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,” IEEE Signal Processing Magazine, vol. 38, no. 2, pp. 18–44, 2021.
- U. S. Kamilov, C. A. Bouman, G. T. Buzzard, and B. Wohlberg, “Plug-and-play methods for integrating physical and learned models in computational imaging: Theory, algorithms, and applications,” IEEE Signal Processing Magazine, vol. 40, no. 1, pp. 85–97, 2023.
- X. Pu, T. Cao, X. Zhang, X. Dong, and S. Chen, “Learning to learn graph topologies,” in Neural Information Processing Systems, 2021.
- O. Banerjee, L. El Ghaoui, and A. d’Aspremont, “Model selection through sparse maximum likelihood estimation for multivariate gaussian or binary data,” The Journal of Machine Learning Research, vol. 9, pp. 485–516, 2008.
- Z. Li and D. Hoiem, “Learning without forgetting,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935–2947, 2017.
- D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning,” Advances in neural information processing systems, vol. 30, 2017.
- X. Dong, D. Thanou, P. Frossard, and P. Vandergheynst, “Learning laplacian matrix in smooth graph signal representations,” IEEE Transactions on Signal Processing, vol. 64, no. 23, pp. 6160–6173, 2016.
- J. Gorski, F. Pfeuffer, and K. Klamroth, “Biconvex sets and optimization with biconvex functions: a survey and extensions,” Mathematical methods of operations research, vol. 66, pp. 373–407, 2007.
- W. Rudin, “Real and complex analysis. 1987,” Cited on, vol. 156, p. 16, 1987.
- F. Huszár, “Note on the quadratic penalties in elastic weight consolidation,” Proceedings of the National Academy of Sciences, vol. 115, no. 11, pp. E2496–E2497, 2018.
- T.-C. Kao, K. Jensen, G. van de Ven, A. Bernacchia, and G. Hennequin, “Natural continual learning: success is a journey, not (just) a destination,” Advances in neural information processing systems, vol. 34, pp. 28 067–28 079, 2021.
- A. Almaatouq, A. Noriega-Campero, A. Alotaibi, P. Krafft, M. Moussaid, and A. Pentland, “Adaptive social networks promote the wisdom of crowds,” Proceedings of the National Academy of Sciences, vol. 117, no. 21, pp. 11 379–11 386, 2020.
- S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learning,” in International Conference on Machine Learning. PMLR, 2020, pp. 5132–5143.
- T. Li, S. Hu, A. Beirami, and V. Smith, “Ditto: Fair and robust federated learning through personalization,” in International Conference on Machine Learning. PMLR, 2021, pp. 6357–6368.
- R. Ye, Z. Ni, F. Wu, S. Chen, and Y. Wang, “Personalized federated learning with inferred collaboration graphs,” in Proceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research. PMLR, 2023.
- X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent,” in Neural Information Processing Systems, 2017.
- S. Pu and A. Nedić, “Distributed stochastic gradient tracking methods,” Mathematical Programming, vol. 187, pp. 409 – 457, 2018.
- T. Sun, D. Li, and B. Wang, “Decentralized federated averaging,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4289–4301, 2022.
- N. Meinshausen and P. Bühlmann, “High-dimensional graphs and variable selection with the lasso,” The Annals of Statistics, vol. 34, no. 3, pp. 1436–1462, 2006.
- A.-L. Barabási, “Network science,” Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 371, no. 1987, p. 20120375, 2013.
- J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, and T. Tuytelaars, “Memory aware synapses: Learning what (not) to forget,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 139–154.
- A. Chaudhry, M. Ranzato, M. Rohrbach, and M. Elhoseiny, “Efficient lifelong learning with a-gem,” ArXiv, vol. abs/1812.00420, 2018.
- Y. LeCun, C. Cortes, and C. Burges, “Mnist handwritten digit database,” ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, vol. 2, 2010.
- A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Technical report, University of Toronto, 2009.
- T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non-identical data distribution for federated visual classification,” arXiv preprint arXiv:1909.06335, 2019.
- A. Kalervo, J. Ylioinas, M. Häikiö, A. Karhu, and J. Kannala, “Cubicasa5k: A dataset and an improved multi-task model for floorplan image analysis,” in Image Analysis: 21st Scandinavian Conference, SCIA 2019, Norrköping, Sweden, June 11–13, 2019, Proceedings 21. Springer, 2019, pp. 28–40.
- A. Singh, T. Jain, and S. Sukhbaatar, “Learning when to communicate at scale in multiagent cooperative and competitive tasks,” arXiv preprint arXiv:1812.09755, 2018.
- F. Qureshi and D. Terzopoulos, “Smart camera networks in virtual reality,” Proceedings of the IEEE, vol. 96, no. 10, pp. 1640–1656, 2008.
- Y. Li, B. Bhanu, and W. Lin, “Auction protocol for camera active control,” in 2010 IEEE International Conference on Image Processing. IEEE, 2010, pp. 4325–4328.
- S. Sukhbaatar, R. Fergus et al., “Learning multiagent communication with backpropagation,” Advances in neural information processing systems, vol. 29, 2016.
- Y.-C. Liu, J. Tian, N. Glaser, and Z. Kira, “When2com: Multi-agent perception via communication graph grouping,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020, pp. 4105–4114.
- R. Wang, X. He, R. Yu, W. Qiu, B. An, and Z. Rabinovich, “Learning efficient multi-agent communication: An information bottleneck approach,” in International Conference on Machine Learning. PMLR, 2020, pp. 9908–9918.
- I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y. Bengio, “An empirical investigation of catastrophic forgetting in gradient-based neural networks,” arXiv preprint arXiv:1312.6211, 2013.
- F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” in International conference on machine learning. PMLR, 2017, pp. 3987–3995.
- S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 2001–2010.
- F. M. Castro, M. J. Marín-Jiménez, N. Guil, C. Schmid, and K. Alahari, “End-to-end incremental learning,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 233–248.
- H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,” Advances in neural information processing systems, vol. 30, 2017.
- P. Bhat, B. Zonooz, and E. Arani, “Task-aware information routing from common representation space in lifelong learning,” arXiv e-prints, pp. arXiv–2302, 2023.
- A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,” arXiv preprint arXiv:1606.04671, 2016.
- Y. Zhang and D.-Y. Yeung, “A convex formulation for learning task relationships in multi-task learning,” arXiv preprint arXiv:1203.3536, 2012.
- T. Evgeniou and M. Pontil, “Regularized multi–task learning,” in Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 2004, pp. 109–117.
- I. M. Baytas, M. Yan, A. K. Jain, and J. Zhou, “Asynchronous multi-task learning,” in 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 2016, pp. 11–20.
- T. Evgeniou, C. A. Micchelli, M. Pontil, and J. Shawe-Taylor, “Learning multiple tasks with kernel methods.” Journal of machine learning research, vol. 6, no. 4, 2005.
- R. Ye, Z. Ni, C. Xu, J. Wang, S. Chen, and Y. C. Eldar, “Fedfm: Anchor-based feature matching for data heterogeneity in federated learning,” arXiv preprint arXiv:2210.07615, 2022.
- S. J. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Konečný, S. Kumar, and H. B. McMahan, “Adaptive federated optimization,” in International Conference on Learning Representations, 2021.
- J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” Advances in neural information processing systems, vol. 33, pp. 7611–7623, 2020.
- R. Ye, M. Xu, J. Wang, C. Xu, S. Chen, and Y. Wang, “Feddisco: Federated learning with discrepancy-aware collaboration,” arXiv preprint arXiv:2305.19229, 2023.
- V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” Advances in neural information processing systems, vol. 30, 2017.
- C. T Dinh, N. Tran, and J. Nguyen, “Personalized federated learning with moreau envelopes,” Advances in Neural Information Processing Systems, vol. 33, pp. 21 394–21 405, 2020.
- M. G. Arivazhagan, V. Aggarwal, A. K. Singh, and S. Choudhary, “Federated learning with personalization layers,” arXiv preprint arXiv:1912.00818, 2019.
- F. Sattler, K.-R. Müller, and W. Samek, “Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints,” IEEE transactions on neural networks and learning systems, vol. 32, no. 8, pp. 3710–3722, 2020.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.