A Comprehensive Survey on Process-Oriented Automatic Text Summarization with Exploration of LLM-Based Methods
Abstract: Automatic Text Summarization (ATS), utilizing NLP algorithms, aims to create concise and accurate summaries, thereby significantly reducing the human effort required in processing large volumes of text. ATS has drawn considerable interest in both academic and industrial circles. Many studies have been conducted in the past to survey ATS methods; however, they generally lack practicality for real-world implementations, as they often categorize previous methods from a theoretical standpoint. Moreover, the advent of LLMs has altered conventional ATS methods. In this survey, we aim to 1) provide a comprehensive overview of ATS from a ``Process-Oriented Schema'' perspective, which is best aligned with real-world implementations; 2) comprehensively review the latest LLM-based ATS works; and 3) deliver an up-to-date survey of ATS, bridging the two-year gap in the literature. To the best of our knowledge, this is the first survey to specifically investigate LLM-based ATS methods.
- N. Agarwal, K. Gvr, R. S. Reddy, and C. P. Rosé, “Scisumm: a multi-document summarization system for scientific articles,” in Proc. 49th Annu. Meeting Assoc. Comput. Linguistics: Human Lang. Technol.: Syst.Demonstrations, ser. HLT ’11. USA: Assoc. Comput. Linguistics, 2011, p. 115–120.
- G. Lev, M. Shmueli-Scheuer, J. Herzig, A. Jerbi, and D. Konopnicki, “Talksumm: A dataset and scalable annotation method for scientific paper summarization based on conference talks,” in Proc. 57th Annu. Meeting Assoc. Comput. Linguistics, A. Korhonen, D. Traum, and L. Màrquez, Eds. Florence, Italy: Assoc. Comput. Linguistics, Jul. 2019, pp. 2125–2131.
- N. Nazari and M. A. Mahdavi, “A survey on automatic text summarization,” J. AI and Data Mining, vol. 7, no. 1, pp. 121–135, 2019.
- D. Suleiman and A. Awajan, “Deep learning based abstractive text summarization: Approaches, datasets, evaluation measures, and challenges,” Math. Problems Eng., pp. 1–29, 2020.
- S. Gupta and S. K. Gupta, “Abstractive summarization: An overview of the state of the art,” Expert Syst. Appl., vol. 121, pp. 49–65, 2019.
- H. Lin and V. Ng, “Abstractive summarization: A survey of the state of the art,” Proc. AAAI Conf. Artif. Intell., vol. 33, no. 01, pp. 9815–9822, Jul. 2019.
- I. K. Bhat, M. Mohd, and R. Hashmy, “Sumitup: A hybrid single-document text summarizer,” in Soft Comput.: Theories and Appl., M. Pant, K. Ray, T. K. Sharma, S. Rawat, and A. Bandyopadhyay, Eds. Singap.: Springer Singap., 2018, pp. 619–634.
- E. Lloret, M. T. Romá-Ferri, and M. Palomar, “Compendium: A text summarization system for generating abstracts of research papers,” Data & Knowl. Eng., vol. 88, pp. 164–175, 2013.
- X. Feng, X. Feng, and B. Qin, “A survey on dialogue summarization: Recent advances and new frontiers,” in Proc. 31st Int. Joint Conf. Artif. Intell., IJCAI 2022, Vienna, Austria, 23-29 July 2022, L. D. Raedt, Ed. ijcai.org, 2022, pp. 5453–5460.
- H. D. Menéndez, L. Plaza, and D. Camacho, “Combining graph connectivity and genetic clustering to improve biomedical summarization,” in 2014 IEEE Congr. Evol. Comput. (CEC), 2014, pp. 2740–2747.
- A. Chaves, C. Y. Kesiku, and B. Garcia-Zapirain, “Automatic text summarization of biomedical text data: A systematic review,” Inf., vol. 13, p. 393, 2022.
- A. Sahni and S. Palwe, “Topic modeling on online news extraction,” in Intell. Comput. and Inf. and Commun., S. Bhalla, V. Bhateja, A. A. Chandavale, A. S. Hiwale, and S. C. Satapathy, Eds. Singap.: Springer Singap., 2018, pp. 611–622.
- P. Sethi, S. Sonawane, S. Khanwalker, and R. B. Keskar, “Automatic text summarization of news articles,” in 2017 Int. Conf. Big Data, IoT and Data Sci. (BID), 2017, pp. 23–29.
- N. Vijay Kumar and M. Janga Reddy, “Factual instance tweet summarization and opinion analysis of sport competition,” in Soft Comput. and Signal Process., J. Wang, G. R. M. Reddy, V. K. Prasad, and V. S. Reddy, Eds. Singap.: Springer Singap., 2019, pp. 153–162.
- S. Dutta, V. Chandra, K. Mehra, S. Ghatak, A. K. Das, and S. Ghosh, “Summarizing microblogs during emergency events: A comparison of extractive summarization algorithms,” in Emerg. Technol. Data Mining and Inf. Security, A. Abraham, P. Dutta, J. K. Mandal, A. Bhattacharya, and S. Dutta, Eds. Singap.: Springer Singap., 2019, pp. 859–872.
- K. Merchant and Y. Pande, “Nlp based latent semantic analysis for legal text summarization,” in 2018 Int. Conf. Advances in Comput., Commun. and Inform. (ICACCI), 2018, pp. 1803–1807.
- D. Anand and R. Wagh, “Effective deep learning approaches for summarization of legal texts,” J. of King Saud Univ. - Comput. and Inf. Sci., vol. 34, no. 5, pp. 2141–2150, 2022.
- N. Alampalli Ramu, M. S. Bandarupalli, M. S. S. Nekkanti, and G. Ramesh, “Summarization of research publications using automatic extraction,” in Intell. Data Commun. Technol. and Internet of Things, D. J. Hemanth, S. Shakya, and Z. Baig, Eds. Cham: Springer Int. Publishing, 2020, pp. 1–10.
- X.-J. Jiang, X.-L. Mao, B.-S. Feng, X. Wei, B.-B. Bian, and H. Huang, “Hsds: An abstractive model for automatic survey generation,” in Database Syst. Adv. Appl., G. Li, J. Yang, J. Gama, J. Natwichai, and Y. Tong, Eds. Cham: Springer Int. Publishing, 2019, pp. 70–86.
- Y. Liu, T. Safavi, A. Dighe, and D. Koutra, “Graph summarization methods and applications: A survey,” ACM Comput. Surv., vol. 51, no. 3, jun 2018.
- O. Tas and F. Kiyani, “A survey automatic text summarization,” PressAcademia Procedia, vol. 5, no. 1, pp. 205–213, 2007.
- S. Gholamrezazadeh, M. A. Salehi, and B. Gholamzadeh, “A comprehensive survey on text summarization systems,” in 2009 2nd Int. Conf. Comput. Sci. and its Appl. IEEE, 2009, pp. 1–6.
- V. Gupta and G. S. Lehal, “A survey of text summarization extractive techniques,” J. of Emerg. Technol. in Web Intell., vol. 2, no. 3, pp. 258–268, Aug. 2010.
- Moratanch, N. and Chitrakala, S., “A survey on extractive text summarization,” in 2017 Int. Conf. Comput., Commun. and Signal Process. (ICCCSP), 2017, pp. 1–6.
- N. Moratanch and S. Chitrakala, “A survey on extractive text summarization,” 2017 Int. Conf. Comput., Commun. and Signal Process. (ICCCSP), pp. 1–6, 2017.
- W. S. El-Kassas, C. R. Salama, A. A. Rafea, and H. K. Mohamed, “Automatic text summarization: A comprehensive survey,” Expert Syst. Appl., vol. 165, p. 113679, 2021.
- A. A. Syed, F. L. Gaol, and T. Matsuo, “A survey of the state-of-the-art models in neural abstractive text summarization,” IEEE Access, vol. 9, pp. 13 248–13 265, 2021.
- M. F. Mridha, A. A. Lima, K. Nur, S. C. Das, M. Hasan, and M. M. Kabir, “A survey of automatic text summarization: Progress, process and challenges,” IEEE Access, vol. 9, pp. 156 043–156 070, 2021.
- Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,” ACM Comput. Surveys, vol. 55, no. 12, pp. 1–38, 2023.
- H. Y. Koh, J. Ju, M. Liu, and S. Pan, “An empirical survey on long document summarization: Datasets, models, and metrics,” ACM Comput. Surv., vol. 55, no. 8, dec 2022.
- H. P. Luhn, “The automatic creation of literature abstracts,” IBM J. of Res. and development, vol. 2, no. 2, pp. 159–165, 1958.
- A. P. Widyassari, S. Rustad, G. F. Shidik, E. Noersasongko, A. Syukur, A. Affandy et al., “Review of automatic text summarization techniques & methods,” J. of King Saud Univ.-Comput. and Inf. Sci., vol. 34, no. 4, pp. 1029–1046, 2022.
- L. Hou, P. Hu, and C. Bei, “Abstractive document summarization via neural model with joint attention,” in Natural Lang. Process. and Chin. Comput.: 6th CCF Int. Conf. , NLPCC 2017, Dalian, China, November 8–12, 2017, Proc. 6. Springer, 2018, pp. 329–338.
- T. Mikolov, M. Karafiát, L. Burget, J. Cernockỳ, and S. Khudanpur, “Recurrent neural network based language model.” in Interspeech, vol. 2, no. 3. Makuhari, 2010, pp. 1045–1048.
- A. Vaswani, N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in NIPS, 2017.
- M. Kirmani, N. Manzoor Hakak, M. Mohd, and M. Mohd, “Hybrid text summarization: A survey,” in Soft Comput.: Theories and Appl., K. Ray, T. K. Sharma, S. Rawat, R. K. Saini, and A. Bandyopadhyay, Eds. Singap.: Springer Singap., 2019, pp. 63–73.
- H. Chen, X. Liu, D. Yin, and J. Tang, “A survey on dialogue systems: Recent advances and new frontiers,” SIGKDD Explor., vol. 19, no. 2, pp. 25–35, 2017.
- Q. Li, Y. Chen, J. Wang, Y. Chen, and H. Chen, “Web media and stock markets : A survey and future directions from a big data perspective,” IEEE Trans. on Knowl. and Data Eng., vol. 30, no. 2, pp. 381–399, 2018.
- A. Kanapala, S. Pal, and R. Pamula, “Text summarization from legal documents: a survey,” Artif. Intell. Review, vol. 51, no. 3, pp. 371–402, Mar 2019.
- N. Ibrahim Altmami and M. El Bachir Menai, “Automatic summarization of scientific articles: A survey,” J. of King Saud Univ. - Comput. and Inf. Sci., vol. 34, no. 4, pp. 1011–1028, 2022.
- C. Ma, W. E. Zhang, M. Guo, H. Wang, and Q. Z. Sheng, “Multi-document summarization via deep learning techniques: A survey,” ACM Comput. Surv., vol. 55, no. 5, dec 2022.
- R. Jain, A. Jangra, S. Saha, and A. Jatowt, “A survey on medical document summarization,” 2022.
- P. Bhattacharya, K. Hiware, S. Rajgaria, N. Pochhi, K. Ghosh, and S. Ghosh, “A comparative study of summarization algorithms applied to legal case judgments,” in Advances in Inf. Retrieval, L. Azzopardi, B. Stein, N. Fuhr, P. Mayr, C. Hauff, and D. Hiemstra, Eds. Cham: Springer Int. Publishing, 2019, pp. 413–428.
- D. Jain, M. D. Borah, and A. Biswas, “Summarization of legal documents: Where are we now and the way forward,” Comput. Sci. Review, vol. 40, p. 100388, 2021.
- X. Feng, X. Feng, B. Qin, and X. Geng, “Dialogue discourse-aware graph model and data augmentation for meeting summarization,” in Proc. 30th IJCAI, IJCAI-21, Z.-H. Zhou, Ed. IJCAI Org., 8 2021, pp. 3808–3814, main Track.
- X. Liu, S. Zang, C. Zhang, X. Chen, and Y. Ding, “Clts+: A new chinese long text summarization dataset with abstractive summaries,” in Int. Conf. Artif. Neural Networks. Springer, 2022, pp. 73–84.
- A. Asi, S. Wang, R. Eisenstadt, D. Geckt, Y. Kuper, Y. Mao, and R. Ronen, “An end-to-end dialogue summarization system for sales calls,” in Proc. 2022 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol.: Industry Track, A. Loukina, R. Gangadharaiah, and B. Min, Eds. Hybrid: Seattle, Washington + Online: Assoc. Comput. Linguistics, Jul. 2022, pp. 45–53.
- R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang, “Abstractive text summarization using sequence-to-sequence RNNs and beyond,” in Proc. 20th SIGNLL Conf. Computational Natural Lang. Learning, S. Riezler and Y. Goldberg, Eds. Berlin, Germany: Assoc. Comput. Linguistics, Aug. 2016, pp. 280–290.
- A. See, P. J. Liu, and C. D. Manning, “Get to the point: Summarization with pointer-generator networks,” in Proc. 55th Annu. Meeting Assoc. Comput. Linguistics (Volume 1: Long Papers), R. Barzilay and M.-Y. Kan, Eds. Vancouver, Canada: Assoc. Comput. Linguistics, Jul. 2017, pp. 1073–1083.
- S. Narayan, J. Maynez, J. Adamek, D. Pighin, B. Bratanic, and R. McDonald, “Stepwise extractive summarization and planning with structured transformers,” in EMNLP, B. Webber, T. Cohn, Y. He, and Y. Liu, Eds. Online: Assoc. Comput. Linguistics, Nov. 2020, pp. 4143–4159.
- M. Zhong, P. Liu, Y. Chen, D. Wang, X. Qiu, and X. Huang, “Extractive summarization as text matching,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 6197–6208.
- A. M. Rush, S. Chopra, and J. Weston, “A neural attention model for abstractive sentence summarization,” in EMNLP, L. Màrquez, C. Callison-Burch, and J. Su, Eds. Lisbon, Portugal: Assoc. Comput. Linguistics, Sep. 2015, pp. 379–389.
- U. Khandelwal, K. Clark, D. Jurafsky, and L. Kaiser, “Sample efficient text summarization using a single pre-trained transformer,” arXiv preprint arXiv:1905.08836, 2019.
- P. Li, W. Lam, L. Bing, and Z. Wang, “Deep recurrent generative decoder for abstractive text summarization,” in EMNLP, M. Palmer, R. Hwa, and S. Riedel, Eds. Copenhagen, Denmark: Assoc. Comput. Linguistics, Sep. 2017, pp. 2091–2100.
- D. Graff, J. Kong, K. Chen, and K. Maeda, “English gigaword,” Linguistic Data Consortium, Philadelphia, vol. 4, no. 1, p. 34, 2003.
- K. Song, B. Wang, Z. Feng, and F. Liu, “A new approach to overgenerating and scoring abstractive summaries,” in Proc. 2021 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, and Y. Zhou, Eds. Online: Assoc. Comput. Linguistics, Jun. 2021, pp. 1392–1404.
- K. Song, B. Wang, Z. Feng, R. Liu, and F. Liu, “Controlling the amount of verbatim copying in abstractive summarization,” in Proc. AAAI Conf. Artif. Intell., vol. 34, no. 05, 2020, pp. 8902–8909.
- S. Narayan, S. B. Cohen, and M. Lapata, “Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization,” in EMNLP, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Brussels, Belgium: Assoc. Comput. Linguistics, Oct.-Nov. 2018, pp. 1797–1807.
- Y. Liu and M. Lapata, “Text summarization with pretrained encoders,” in EMNLP-IJCNLP, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Hong Kong, China: Assoc. Comput. Linguistics, Nov. 2019, pp. 3730–3740.
- J. Zhang, Y. Zhao, M. Saleh, and P. J. Liu, “Pegasus: pre-training with extracted gap-sentences for abstractive summarization,” in Proc. 37th Int. Conf. Machine Learning, ser. ICML’20. JMLR.org, 2020.
- A. Fabbri, I. Li, T. She, S. Li, and D. Radev, “Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model,” in Proc. 57th Annu. Meeting Assoc. Comput. Linguistics, A. Korhonen, D. Traum, and L. Màrquez, Eds. Florence, Italy: Assoc. Comput. Linguistics, Jul. 2019, pp. 1074–1084.
- P. He, B. Peng, L. Lu, S. Wang, J. Mei, Y. Liu, R. Xu, H. H. Awadalla, Y. Shi, C. Zhu et al., “Z-code++: A pre-trained language model optimized for abstractive summarization,” arXiv preprint arXiv:2208.09770, 2022.
- D. Wang, P. Liu, Y. Zheng, X. Qiu, and X. Huang, “Heterogeneous graph neural networks for extractive document summarization,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 6209–6219.
- M. Yasunaga, J. Kasai, R. Zhang, A. R. Fabbri, I. Li, D. Friedman, and D. R. Radev, “Scisummnet: A large annotated corpus and content-impact models for scientific paper summarization with citation networks,” Proc. AAAI Conf. Artif. Intell., vol. 33, no. 01, pp. 7386–7393, Jul. 2019.
- I. Cachola, K. Lo, A. Cohan, and D. Weld, “TLDR: Extreme summarization of scientific documents,” in Findings Assoc. Comput. Linguistics: EMNLP, T. Cohn, Y. He, and Y. Liu, Eds. Online: Assoc. Comput. Linguistics, Nov. 2020, pp. 4766–4777.
- A. Ni, Z. Azerbayev, M. Mutuma, T. Feng, Y. Zhang, T. Yu, A. H. Awadallah, and D. Radev, “SummerTime: Text summarization toolkit for non-experts,” in EMNLP, H. Adel and S. Shi, Eds. Online and Punta Cana, Dominican Republic: Assoc. Comput. Linguistics, Nov. 2021, pp. 329–338.
- A. Cohan, F. Dernoncourt, D. S. Kim, T. Bui, S. Kim, W. Chang, and N. Goharian, “A discourse-aware attention model for abstractive summarization of long documents,” in Proc. 2018 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., Volume 2 (Short Papers), M. Walker, H. Ji, and A. Stent, Eds. New Orleans, Louisiana: Assoc. Comput. Linguistics, Jun. 2018, pp. 615–621.
- W. Xiao, I. Beltagy, G. Carenini, and A. Cohan, “PRIMERA: Pyramid-based masked sentence pre-training for multi-document summarization,” in Proc. 60th Annu. Meeting Assoc. Comput. Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Assoc. Comput. Linguistics, May 2022, pp. 5245–5263.
- S. Sotudeh, A. Cohan, and N. Goharian, “On generating extended summaries of long documents,” arXiv preprint arXiv:2012.14136, 2020.
- M. Koupaee and W. Y. Wang, “Wikihow: A large scale text summarization dataset,” ArXiv, vol. abs/1810.09305, 2018.
- A. Savelieva, B. Au-Yeung, and V. Ramani, “Abstractive summarization of spoken and written instructions with bert,” arXiv preprint arXiv:2008.09676, 2020.
- J. Lin, X. Sun, S. Ma, and Q. Su, “Global encoding for abstractive summarization,” in Proc. 56th Annu. Meeting Assoc. Comput. Linguistics (Volume 2: Short Papers), I. Gurevych and Y. Miyao, Eds. Melbourne, Australia: Assoc. Comput. Linguistics, Jul. 2018, pp. 163–169.
- S. Ma, X. Sun, J. Lin, and H. Wang, “Autoencoder as assistant supervisor: Improving text representation for Chinese social media text summarization,” in Proc. 56th Annu. Meeting Assoc. Comput. Linguistics (Volume 2: Short Papers), I. Gurevych and Y. Miyao, Eds. Melbourne, Australia: Assoc. Comput. Linguistics, Jul. 2018, pp. 725–731.
- K. M. Hermann, T. Kocisky, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, and P. Blunsom, “Teaching machines to read and comprehend,” Advances in neural Inf. Process. systems, vol. 28, 2015.
- D. Harman and P. Over, “The effects of human variation in duc summarization evaluation,” in Text Summarization Branches Out, 2004, pp. 10–17.
- B. Hu, Q. Chen, and F. Zhu, “LCSTS: A large scale Chinese short text summarization dataset,” in EMNLP, L. Màrquez, C. Callison-Burch, and J. Su, Eds. Lisbon, Portugal: Assoc. Comput. Linguistics, Sep. 2015, pp. 1967–1972.
- X. Feng, X. Feng, L. Qin, B. Qin, and T. Liu, “Language model as an annotator: Exploring DialoGPT for dialogue summarization,” in Proc. 59th Annu. Meeting Assoc. Comput. Linguistics and the 11th Int. Joint Conf. Natural Lang. Process. (Volume 1: Long Papers), C. Zong, F. Xia, W. Li, and R. Navigli, Eds. Online: Assoc. Comput. Linguistics, Aug. 2021, pp. 1479–1491.
- Y. Zhang, S. Sun, M. Galley, Y.-C. Chen, C. Brockett, X. Gao, J. Gao, J. Liu, and B. Dolan, “DIALOGPT : Large-scale generative pre-training for conversational response generation,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics: System Demonstrations, A. Celikyilmaz and T.-H. Wen, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 270–278.
- B. Chintagunta, N. Katariya, X. Amatriain, and A. Kannan, “Medically aware GPT-3 as a data generator for medical dialogue summarization,” in Proc. 2nd Workshop on Natural Lang. Process. for Medical Conversations, C. Shivade, R. Gangadharaiah, S. Gella, S. Konam, S. Yuan, Y. Zhang, P. Bhatia, and B. Wallace, Eds. Online: Assoc. Comput. Linguistics, Jun. 2021, pp. 66–76.
- A. Liu, S. Swayamdipta, N. A. Smith, and Y. Choi, “Wanli: Worker and ai collaboration for natural language inference dataset creation,” arXiv preprint arXiv:2201.05955, 2022.
- T. Goyal and G. Durrett, “Annotating and modeling fine-grained factuality in summarization,” in Proc. 2021 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, and Y. Zhou, Eds. Online: Assoc. Comput. Linguistics, Jun. 2021, pp. 1449–1462.
- W. Kryscinski, B. McCann, C. Xiong, and R. Socher, “Evaluating the factual consistency of abstractive text summarization,” in EMNLP, B. Webber, T. Cohn, Y. He, and Y. Liu, Eds. Online: Assoc. Comput. Linguistics, Nov. 2020, pp. 9332–9346.
- T. Goyal and G. Durrett, “Evaluating factuality in generation with dependency-level entailment,” in Findings Assoc. Comput. Linguistics: EMNLP, 2020, pp. 3592–3603.
- V. Balachandran, H. Hajishirzi, W. Cohen, and Y. Tsvetkov, “Correcting diverse factual errors in abstractive summarization via post-editing and language model infilling,” in EMNLP, 2022, pp. 9818–9830.
- T. Vodolazova, E. Lloret, R. Muñoz, and M. Palomar, “The role of statistical and semantic features in single-document extractive summarization,” Artif. Intell. Res., vol. 2, pp. 35–44, 2013.
- H. Saif, M. Fernández, Y. He, and H. Alani, “On stopwords, filtering and data sparsity for sentiment analysis of twitter,” in Int. Conf. Lang. Resources and Evaluation, 2014.
- E. Charniak, “Statistical techniques for natural language parsing,” AI Mag., vol. 18, no. 4, pp. 33–44, 1997.
- M. Y. Nuzumlali and A. Özgür, “Analyzing stemming approaches for turkish multi-document summarization,” in Conf. EMNLP, 2014.
- E. Galiotou, N. N. Karanikolas, and C. Tsoulloftas, “On the effect of stemming algorithms on extractive summarization: a case study,” in Panhellenic Conf. Inform., 2013.
- L. Hickman, S. Thapa, L. Tay, M. Cao, and P. Srinivasan, “Text preprocessing for text mining in organizational research: Review and recommendations,” Organizational Res. Methods, vol. 25, no. 1, pp. 114–146, 2022.
- J.-M. Torres-Moreno, “Beyond stemming and lemmatization: Ultra-stemming to improve automatic text summarization,” ArXiv, vol. abs/1209.3126, 2012.
- V. K. Gupta and T. J. Siddiqui, “Multi-document summarization using sentence clustering,” in 2012 4th Int. Conf. Intell. Human Comput. Interaction (IHCI). IEEE, 2012, pp. 1–5.
- G. Moro and L. Ragazzi, “Semantic self-segmentation for abstractive summarization of long documents in low-resource regimes,” in AAAI Conf. Artif. Intell., 2022.
- J. Wang, J. Tan, H. Jin, and S. Qi, “Unsupervised graph-clustering learning framework for financial news summarization,” 2021 Int. Conf. Data Mining Workshops (ICDMW), pp. 719–726, 2021.
- R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proc. 54th Annu. Meeting Assoc. Comput. Linguistics (Volume 1: Long Papers), K. Erk and N. A. Smith, Eds. Berlin, Germany: Assoc. Comput. Linguistics, Aug. 2016, pp. 1715–1725.
- Y. Wu, M. Schuster, Z. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey, J. Klingner, A. Shah, M. Johnson, X. Liu, L. Kaiser, S. Gouws, Y. Kato, T. Kudo, H. Kazawa, K. Stevens, G. Kurian, N. Patil, W. Wang, C. Young, J. R. Smith, J. Riesa, A. Rudnick, O. Vinyals, G. S. Corrado, M. Hughes, and J. Dean, “Google’s neural machine translation system: Bridging the gap between human and machine translation,” ArXiv, vol. abs/1609.08144, 2016.
- H. He and J. D. Choi, “The stem cell hypothesis: Dilemma behind multi-task learning with transformer encoders,” in EMNLP. Online and Punta Cana, Dominican Republic: Assoc. Comput. Linguistics, Nov. 2021, pp. 5555–5577.
- B. Gong, W.-L. Chao, K. Grauman, and F. Sha, “Diverse sequential subset selection for supervised video summarization,” in Proc. 27th Int. Conf. Neural Inf. Process. Syst.- Volume 2, ser. NIPS’14. Cambridge, MA, USA: MIT Press, 2014, p. 2069–2077.
- K. Gunaratna, K. Thirunarayan, and A. Sheth, “Faces: Diversity-aware entity summarization using incremental hierarchical conceptual clustering,” Proc. AAAI Conf. Artif. Intell., vol. 29, no. 1, Feb. 2015.
- M. Peyrard, “A simple theoretical model of importance for summarization,” in Proceedings 57th Annu. Meeting Assoc. Comput. Linguistics, A. Korhonen, D. Traum, and L. Màrquez, Eds. Florence, Italy: Assoc. Comput. Linguistics, Jul. 2019, pp. 1059–1073.
- R. Yan, H. Jiang, M. Lapata, S.-D. Lin, X. Lv, and X. Li, “i, poet: automatic chinese poetry composition through a generative summarization framework under constrained optimization,” in Proc. 23rd IJCAI, ser. IJCAI ’13. AAAI Press, 2013, p. 2197–2203.
- K. Wang, T. Liu, Z. Sui, and B. Chang, “Affinity-preserving random walk for multi-document summarization,” in EMNLP, M. Palmer, R. Hwa, and S. Riedel, Eds. Copenhagen, Denmark: Assoc. Comput. Linguistics, Sep. 2017, pp. 210–220.
- G. Shang, W. Ding, Z. Zhang, A. Tixier, P. Meladianos, M. Vazirgiannis, and J.-P. Lorré, “Unsupervised abstractive meeting summarization with multi-sentence compression and budgeted submodular maximization,” in Proc. 56th Annu. Meeting Assoc. Comput. Linguistics (Volume 1: Long Papers), I. Gurevych and Y. Miyao, Eds. Melbourne, Australia: Assoc. Comput. Linguistics, Jul. 2018, pp. 664–674.
- H. Christian, M. P. Agus, and D. Suhartono, “Single document automatic text summarization using term frequency-inverse document frequency (tf-idf),” ComTech, vol. 7, no. 4, 2016.
- N. Alsaedi, P. Burnap, and O. Rana, “Temporal tf-idf: A high performance approach for event summarization in twitter,” in 2016 IEEE/WIC/ACM Int. Conf. Web Intell. (WI), 2016, pp. 515–521.
- C. Rioux, S. A. Hasan, and Y. Chali, “Fear the REAPER: A system for automatic multi-document summarization with reinforcement learning,” in EMNLP, A. Moschitti, B. Pang, and W. Daelemans, Eds. Doha, Qatar: Assoc. Comput. Linguistics, Oct. 2014, pp. 681–690.
- W. Luo, F. Liu, Z. Liu, and D. Litman, “Automatic summarization of student course feedback,” in Proc. 2016 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., K. Knight, A. Nenkova, and O. Rambow, Eds. San Diego, California: Assoc. Comput. Linguistics, Jun. 2016, pp. 80–85.
- X. Qian and Y. Liu, “Fast joint compression and summarization via graph cuts,” in EMNLP, D. Yarowsky, T. Baldwin, A. Korhonen, K. Livescu, and S. Bethard, Eds. Seattle, Washington, USA: Assoc. Comput. Linguistics, Oct. 2013, pp. 1492–1502.
- C.-Y. Lin and E. Hovy, “Automatic evaluation of summaries using n-gram co-occurrence statistics,” in Proc. 2003 Human Lang. Technol. Conf. North American Chapter Assoc. Comput. Linguistics, 2003, pp. 150–157.
- M. Banko and L. Vanderwende, “Using n-grams to understand the nature of summaries,” in Proc. of HLT-NAACL 2004: Short Papers, ser. HLT-NAACL-Short ’04. USA: Assoc. Comput. Linguistics, 2004, p. 1–4.
- T. K. Landauer and S. T. Dumais, “Latent semantic analysis,” Scholarpedia, vol. 3, p. 4356, 2008.
- J.-Y. Yeh, H.-R. Ke, W.-P. Yang, and I.-H. Meng, “Text summarization using a trainable summarizer and latent semantic analysis,” Inf. Process. & Manage., vol. 41, no. 1, pp. 75–95, 2005, an Asian Digital Libraries Perspective.
- D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” J. of machine Learning Res., vol. 3, no. Jan, pp. 993–1022, 2003.
- A. Haghighi and L. Vanderwende, “Exploring content models for multi-document summarization,” in Proc. of human Lang. Technol.: The 2009 Annu. Conf. North American Chapter Assoc. Comput. Linguistics, 2009, pp. 362–370.
- Y. Lu, C. Zhai, and N. Sundaresan, “Rated aspect summarization of short comments,” in Proc. 18th Int. Conf. World Wide Web, ser. WWW ’09. New York, NY, USA: Assoc. for Comput. Machinery, 2009, p. 131–140.
- C. Allen and T. M. Hospedales, “Analogies explained: Towards understanding word embeddings,” in Int. Conf. Machine Learning, 2019.
- T. Mikolov, K. Chen, G. S. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” in Int. Conf. Learning Representations, 2013.
- G. Rossiello, P. Basile, and G. Semeraro, “Centroid-based text summarization through compositionality of word embeddings,” in Proc. MultiLing 2017 Workshop on Summarization and Summary Evaluation Across Source Types and Genres, G. Giannakopoulos, E. Lloret, J. M. Conroy, J. Steinberger, M. Litvak, P. Rankel, and B. Favre, Eds. Valencia, Spain: Assoc. Comput. Linguistics, Apr. 2017, pp. 12–21.
- M. M. Haider, M. A. Hossin, H. R. Mahi, and H. Arif, “Automatic text summarization using gensim word2vec and k-means clustering algorithm,” in 2020 IEEE Region 10 Symposium (TENSYMP). IEEE, 2020, pp. 283–286.
- S. Ji, N. Satish, S. Li, and P. K. Dubey, “Parallelizing word2vec in shared and distributed memory,” IEEE Trans. Parallel Distrib. Syst., vol. 30, no. 9, p. 2090–2100, sep 2019.
- U. Naseem, I. Razzak, S. K. Khan, and M. Prasad, “A comprehensive survey on word representation models: From classical to state-of-the-art word representation language models,” ACM Trans. Asian Low-Resour. Lang. Inf. Process., vol. 20, no. 5, jun 2021.
- J. Pennington, R. Socher, and C. Manning, “GloVe: Global vectors for word representation,” in EMNLP, A. Moschitti, B. Pang, and W. Daelemans, Eds. Doha, Qatar: Assoc. Comput. Linguistics, Oct. 2014, pp. 1532–1543.
- W. Xiao and G. Carenini, “Extractive summarization of long documents by combining global and local context,” in EMNLP-IJCNLP, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Hong Kong, China: Assoc. Comput. Linguistics, Nov. 2019, pp. 3011–3021.
- S. S. Nath and B. Roy, “Towards automatically generating release notes using extractive summarization technique,” arXiv preprint arXiv:2204.05345, 2022.
- Y. Wang, Y. Hou, W. Che, and T. Liu, “From static to dynamic word representations: a survey,” Int. J. Mach. Learn. Cybern., vol. 11, no. 7, pp. 1611–1630, 2020.
- H. Zheng and M. Lapata, “Sentence centrality revisited for unsupervised summarization,” in Proc.57th Annu. Meeting Assoc. Comput. Linguistics, A. Korhonen, D. Traum, and L. Màrquez, Eds. Florence, Italy: Assoc. Comput. Linguistics, Jul. 2019, pp. 6236–6247.
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. 2019 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Minneapolis, Minnesota: Assoc. Comput. Linguistics, Jun. 2019, pp. 4171–4186.
- T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Inf. Process. Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901.
- X. Qiu, T. Sun, Y. Xu, Y. Shao, N. Dai, and X. Huang, “Pre-trained models for natural language processing: A survey,” Science China Technol. Sci., vol. 63, no. 10, pp. 1872–1897, 2020.
- V. Joshi, M. Peters, and M. Hopkins, “Extending a parser to distant domains using a few dozen partially annotated examples,” in Proc. 56th Annu. Meeting Assoc. Comput. Linguistics (Volume 1: Long Papers), I. Gurevych and Y. Miyao, Eds. Melbourne, Australia: Assoc. Comput. Linguistics, Jul. 2018, pp. 1190–1199.
- J. Zhou and A. M. Rush, “Simple unsupervised summarization by contextual matching,” in Proc. 57th Annu. Meeting Assoc. Comput. Linguistics, 2019, pp. 5101–5106.
- K. Ethayarajh, “How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings,” in EMNLP-IJCNLP, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Hong Kong, China: Assoc. Comput. Linguistics, Nov. 2019, pp. 55–65.
- X. Zhang, F. Wei, and M. Zhou, “HIBERT: Document level pre-training of hierarchical bidirectional transformers for document summarization,” in Proceedings 57th Annu. Meeting Assoc. Comput. Linguistics, A. Korhonen, D. Traum, and L. Màrquez, Eds. Florence, Italy: Assoc. Comput. Linguistics, Jul. 2019, pp. 5059–5069.
- H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” ArXiv, vol. abs/2302.13971, 2023.
- Y. Dong, J.-B. Cordonnier, and A. Loukas, “Attention is not all you need: Pure attention loses rank doubly exponentially with depth,” in Int. Conf. Machine Learning. PMLR, 2021, pp. 2793–2803.
- T. R. Goodwin, M. E. Savery, and D. Demner-Fushman, “Flight of the pegasus? comparing transformers on few-shot and zero-shot multi-document abstractive summarization,” Proc. of COLING. Int. Conf. Comput. Linguistics, vol. 2020, pp. 5640 – 5646, 2020.
- M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 7871–7880.
- C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The J. of Machine Learning Res., vol. 21, no. 1, pp. 5485–5551, 2020.
- X. Yang, Y. Li, X. Zhang, H. Chen, and W. Cheng, “Exploring the limits of chatgpt for query or aspect-based text summarization,” ArXiv, vol. abs/2302.08081, 2023.
- R. Mihalcea and P. Tarau, “TextRank: Bringing order into text,” in EMNLP, D. Lin and D. Wu, Eds. Barcelona, Spain: Assoc. Comput. Linguistics, Jul. 2004, pp. 404–411.
- G. Erkan and D. R. Radev, “Lexrank: graph-based lexical centrality as salience in text summarization,” J. Artif. Int. Res., vol. 22, no. 1, p. 457–479, dec 2004.
- D. Gillick and B. Favre, “A scalable global model for summarization,” in Proc. Workshop on Integer Linear Programming for Natural Lang. Process., J. Clarke and S. Riedel, Eds. Boulder, Colorado: Assoc. Comput. Linguistics, Jun. 2009, pp. 10–18.
- Y. Zhang, Y. Xia, Y. Liu, and W. Wang, “Clustering sentences with density peaks for multi-document summarization,” in Proc. 2015 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., R. Mihalcea, J. Chai, and A. Sarkar, Eds. Denver, Colorado: Assoc. Comput. Linguistics, May–Jun. 2015, pp. 1262–1267.
- S. M. Mohammed, K. Jacksi, and S. R. Zeebaree, “Glove word embedding and dbscan algorithms for semantic document clustering,” in 2020 Int. Conf. Adv. Sci. and Eng. (ICOASE). IEEE, 2020, pp. 1–6.
- S. Abdel-Salam and A. Rafea, “Performance study on extractive text summarization using bert models,” Inf., vol. 13, no. 2, p. 67, 2022.
- Q. Xie, J. A. Bishop, P. Tiwari, and S. Ananiadou, “Pre-trained language models with domain knowledge for biomedical extractive summarization,” Knowl.-Based Systems, vol. 252, p. 109460, 2022.
- X. Shi, Z. Chen, H. Wang, D. Y. Yeung, W.-K. Wong, and W. chun Woo, “Convolutional lstm network: A machine learning approach for precipitation nowcasting,” in NIPS, 2015.
- J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” in NIPS 2014 Workshop on Deep Learning, December 2014, 2014.
- R. Nallapati, F. Zhai, and B. Zhou, “Summarunner: a recurrent neural network based sequence model for extractive summarization of documents,” in Proc. Thirty-1st AAAI Conf. Artif. Intell., ser. AAAI’17. AAAI Press, 2017, p. 3075–3081.
- S. Chopra, M. Auli, and A. M. Rush, “Abstractive sentence summarization with attentive recurrent neural networks,” in Proc. 2016 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., K. Knight, A. Nenkova, and O. Rambow, Eds. San Diego, California: Assoc. Comput. Linguistics, Jun. 2016, pp. 93–98.
- B. Lindemann, B. Maschler, N. Sahlab, and M. Weyrich, “A survey on anomaly detection for technical syst.using lstm networks,” Comput. Ind., vol. 131, p. 103498, 2021.
- P. M. Hanunggul and S. Suyanto, “The impact of local attention in lstm for abstractive text summarization,” 2019 Int. Seminar on Res. of Inf. Technol. and Intell. Syst.(ISRITI), pp. 54–57, 2019.
- Y. Zhang, J. Liao, J. Tang, W. D. Xiao, and Y. Wang, “Extractive document summarization based on hierarchical gru,” 2018 Int. Conf. Robots & Intell. Syst. (ICRIS), pp. 341–346, 2018.
- Q. Grail, J. Perez, and E. Gaussier, “Globalizing bert-based transformer architectures for long document summarization,” in Proc. 16th Conf. European chapter Assoc. Comput. Linguistics: Main volume, 2021, pp. 1792–1810.
- B. Pang, E. Nijkamp, W. Kryscinski, S. Savarese, Y. Zhou, and C. Xiong, “Long document summarization with top-down and bottom-up inference,” in Findings Assoc. Comput. Linguistics: EACL 2023, A. Vlachos and I. Augenstein, Eds. Dubrovnik, Croatia: Assoc. Comput. Linguistics, May 2023, pp. 1267–1284.
- Z. Wang, Z. Duan, H. Zhang, C. Wang, L. Tian, B. Chen, and M. Zhou, “Friendly topic assistant for transformer based abstractive summarization,” in EMNLP, 2020, pp. 485–497.
- A. Pagnoni, A. R. Fabbri, W. Kryściński, and C.-S. Wu, “Socratic pretraining: Question-driven pretraining for controllable summarization,” arXiv preprint arXiv:2212.10449, 2022.
- W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, Y. Du, C. Yang, Y. Chen, Z. Chen, J. Jiang, R. Ren, Y. Li, X. Tang, Z. Liu, P. Liu, J. Nie, and J. rong Wen, “A survey of large language models,” ArXiv, vol. abs/2303.18223, 2023.
- N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” in Int. Conf. Machine Learning. PMLR, 2019, pp. 2790–2799.
- L. Tang, Z. Sun, B. Idnay, J. G. Nestor, A. Soroush, P. A. Elias, Z. Xu, Y. Ding, G. Durrett, J. F. Rousseau, C. Weng, and Y. Peng, “Evaluating large language models on medical evidence summarization,” npj Digital Medicine, vol. 6, no. 1, p. 158, 2023.
- M. T. R. Laskar, M. S. Bari, M. Rahman, M. A. H. Bhuiyan, S. Joty, and J. X. Huang, “A systematic study and comprehensive evaluation of chatgpt on benchmark datasets,” arXiv preprint arXiv:2305.18486, 2023.
- T. Zhang, F. Ladhak, E. Durmus, P. Liang, K. McKeown, and T. B. Hashimoto, “Benchmarking large language models for news summarization,” 2023.
- M. Ravaut, S. Joty, A. Sun, and N. F. Chen, “On context utilization in summarization with large language models,” 2023.
- L. Basyal and M. Sanghvi, “Text summarization using large language models: A comparative study of mpt-7b-instruct, falcon-7b-instruct, and openai chat-gpt models,” 2023.
- T. Goyal, J. J. Li, and G. Durrett, “News summarization and evaluation in the era of gpt-3,” 2023.
- N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,” Advances in Neural Inf. Process. Systems, vol. 33, pp. 3008–3021, 2020.
- J. Wu, L. Ouyang, D. M. Ziegler, N. Stiennon, R. Lowe, J. Leike, and P. Christiano, “Recursively summarizing books with human feedback,” 2021.
- J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” Int. J. Comput. Vision, vol. 129, pp. 1789–1819, 2021.
- G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” stat, vol. 1050, p. 9, 2015.
- M. Sclar, P. West, S. Kumar, Y. Tsvetkov, and Y. Choi, “Referee: Reference-free sentence summarization with sharper controllability through symbolic knowledge distillation,” in EMNLP, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Abu Dhabi, United Arab Emirates: Assoc. Comput. Linguistics, Dec. 2022, pp. 9649–9668.
- Y. Xu, R. Xu, D. Iter, Y. Liu, S. Wang, C. Zhu, and M. Zeng, “Inheritsumm: A general, versatile and compact summarizer by distilling from gpt,” 2023.
- A. Brazinskas, R. Nallapati, M. Bansal, and M. Dreyer, “Efficient few-shot fine-tuning for opinion summarization,” in Findings Assoc. Comput. Linguistics: NAACL 2022, M. Carpuat, M.-C. de Marneffe, and I. V. Meza Ruiz, Eds. Seattle, United States: Assoc. Comput. Linguistics, Jul. 2022, pp. 1509–1523.
- D. F. Navarro, M. Dras, and S. Berkovsky, “Few-shot fine-tuning SOTA summarization models for medical dialogues,” in Proc. 2022 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol.: Student Res. Workshop, D. Ippolito, L. H. Li, M. L. Pacheco, D. Chen, and N. Xue, Eds. Hybrid: Seattle, Washington + Online: Assoc. Comput. Linguistics, Jul. 2022, pp. 254–266.
- Y. Zhang, X. Zhang, X. Wang, S.-q. Chen, and F. Wei, “Latent prompt tuning for text summarization,” arXiv preprint arXiv:2211.01837, 2022.
- Y. Chen, Y. Liu, R. Xu, Z. Yang, C. Zhu, M. Zeng, and Y. Zhang, “Unisumm: Unified few-shot summarization with multi-task pre-training and prefix-tuning,” arXiv preprint arXiv:2211.09783, 2022.
- P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Comput. Surv., vol. 55, no. 9, jan 2023.
- S. Narayan, Y. Zhao, J. Maynez, G. Simões, V. Nikolaev, and R. McDonald, “Planning with learned entity prompts for abstractive summarization,” Trans. Assoc. Comput. Linguistics, vol. 9, pp. 1475–1492, 2021.
- R. Shin, C. Lin, S. Thomson, C. Chen, S. Roy, E. A. Platanios, A. Pauls, D. Klein, J. Eisner, and B. Van Durme, “Constrained language models yield few-shot semantic parsers,” in EMNLP. Assoc. Comput. Linguistics, 2021.
- Z. Jiang, F. F. Xu, J. Araki, and G. Neubig, “How can we know what language models know?” Trans. Assoc. Comput. Linguistics, vol. 8, pp. 423–438, 2020.
- Y. Zhou, K. Shi, W. Zhang, Y. Liu, Y. Zhao, and A. Cohan, “Odsum: New benchmarks for open domain multi-document summarization,” 2023.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Inf. Process. Systems, vol. 35, pp. 24 824–24 837, 2022.
- G. Adams, A. Fabbri, F. Ladhak, E. Lehman, and N. Elhadad, “From sparse to dense: GPT-4 summarization with chain of density prompting,” in Proc. 4th New Frontiers in Summarization Workshop, Y. Dong, W. Xiao, L. Wang, F. Liu, and G. Carenini, Eds. Singap.: Assoc. Comput. Linguistics, Dec. 2023, pp. 68–74.
- Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou, R. Zheng, X. Fan, X. Wang, L. Xiong, Y. Zhou, W. Wang, C. Jiang, Y. Zou, X. Liu, Z. Yin, S. Dou, R. Weng, W. Cheng, Q. Zhang, W. Qin, Y. Zheng, X. Qiu, X. Huang, and T. Gui, “The rise and potential of large language model based agents: A survey,” 2023.
- W. Xiao, Y. Xie, G. Carenini, and P. He, “Chatgpt-steered editing instructor for customization of abstractive summarization,” 2023.
- X. Pu, M. Gao, and X. Wan, “Summarization is (almost) dead,” 2023.
- L. Luo, Y.-F. Li, G. Haffari, and S. Pan, “Reasoning on graphs: Faithful and interpretable large language model reasoning,” arXiv preprint arXiv:2310.01061, 2023.
- L. Ermakova, J. V. Cossu, and J. Mothe, “A survey on evaluation of summarization methods,” Inf. Process. & Manage., vol. 56, no. 5, pp. 1794–1814, 2019.
- S. Gehrmann, Y. Deng, and A. Rush, “Bottom-up abstractive summarization,” in EMNLP, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Brussels, Belgium: Assoc. Comput. Linguistics, Oct.-Nov. 2018, pp. 4098–4109.
- C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out, 2004, pp. 74–81.
- C.-Y. Lin and F. Och, “Looking for a few good metrics: Rouge and its evaluation,” in Ntcir workshop, 2004.
- K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proc. 40th Annu. Meeting on Assoc. Comput. Linguistics - ACL ’02. Assoc. Comput. Linguistics, 2001, p. 311.
- G. Doddington, “Automatic evaluation of machine translation quality using n-gram co-occurrence statistics,” in Proc. 2nd Int. Conf. Human Lang. Technol. Research, 2002, pp. 138–145.
- S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” in Proc. acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72.
- T. Zhang*, V. Kishore*, F. Wu*, K. Q. Weinberger, and Y. Artzi, “Bertscore: Evaluating text generation with bert,” in Int. Conf. Learning Representations, 2020.
- S. Sun and A. Nenkova, “The feasibility of embedding based automatic evaluation for single document summarization,” in EMNLP-IJCNLP, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Hong Kong, China: Assoc. Comput. Linguistics, Nov. 2019, pp. 1216–1221.
- M. Gao, J. Ruan, R. Sun, X. Yin, S. Yang, and X. Wan, “Human-like summarization evaluation with chatgpt,” 2023.
- S. Jain, V. Keshava, S. M. Sathyendra, P. Fernandes, P. Liu, G. Neubig, and C. Zhou, “Multi-dimensional evaluation of text summarization with in-context learning,” 2023.
- N. Wu, M. Gong, L. Shou, S. Liang, and D. Jiang, “Large language models are diverse role-players for summarization evaluation,” 2023.
- Y. Chang, K. Lo, T. Goyal, and M. Iyyer, “Booookscore: A systematic exploration of book-length summarization in the era of llms,” 2023.
- Z. Luo, Q. Xie, and S. Ananiadou, “Chatgpt as a factual inconsistency evaluator for text summarization,” 2023.
- D. Tam, A. Mascarenhas, S. Zhang, S. Kwan, M. Bansal, and C. Raffel, “Evaluating the factual consistency of large language models through news summarization,” in Findings Assoc. Comput. Linguistics: ACL 2023, 2023, pp. 5220–5255.
- Q. Jia, S. Ren, Y. Liu, and K. Q. Zhu, “Zero-shot faithfulness evaluation for text summarization with foundation language model,” in The 2023 Conf. EMNLP, 2023.
- R. Barzilay and K. R. McKeown, “Sentence fusion for multidocument news summarization,” Computational Linguistics, vol. 31, no. 3, pp. 297–328, 2005.
- K. R. McKeown, R. Barzilay, D. Evans, V. Hatzivassiloglou, J. L. Klavans, A. Nenkova, C. Sable, B. Schiffman, and S. Sigelman, “Tracking and summarizing news on a daily basis with columbia’s newsblaster,” in Proc. 2nd Int. Conf. Human Lang. Technol. Res., ser. HLT ’02. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2002, p. 280–285.
- D. Gholipour Ghalandari and G. Ifrim, “Examining the state-of-the-art in news timeline summarization,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 1322–1334.
- F. Ladhak, B. Li, Y. Al-Onaizan, and K. McKeown, “Exploring content selection in summarization of novel chapters,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 5043–5054.
- C. An, M. Zhong, Y. Chen, D. Wang, X. Qiu, and X. Huang, “Enhancing scientific papers summarization with citation graph,” in Proc. AAAI Conf. Artif. Intell., vol. 35, no. 14, 2021, pp. 12 498–12 506.
- P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio, “Graph attention networks,” in Int. Conf. Learning Representations, 2018.
- S. Qi, L. Li, Y. Li, J. Jiang, D. Hu, Y. Li, Y. Zhu, Y. Zhou, M. Litvak, and N. Vanetik, “Sapgraph: Structure-aware extractive summarization for scientific papers with heterogeneous graph,” in Proc. 2nd Conf. Asia-Pacific Chapter Assoc. Comput. Linguistics and the 12th Int. Joint Conf. Natural Lang. Process., 2022, pp. 575–586.
- C. Shen, F. Liu, F. Weng, and T. Li, “A participant-based approach for event summarization using twitter streams,” in Proc. 2013 Conf. North American Chapter Assoc. Comput. Linguistics: Human Lang. Technol., 2013, pp. 1152–1162.
- D. Inouye and J. K. Kalita, “Comparing twitter summarization algorithms for multiple post summaries,” in 2011 IEEE 3rd Int. Conf. privacy, security, risk and trust and 2011 IEEE 3rd Int. Conf. social Comput. IEEE, 2011, pp. 298–306.
- L. P. Kumar and A. Kabiri, “Meeting summarization: A survey of the state of the art,” 2022.
- Y. Mehdad, G. Carenini, and R. T. Ng, “Abstractive summarization of spoken and written conversations based on phrasal queries,” in Proc. 52nd Annu. Meeting Assoc. Comput. Linguistics (Volume 1: Long Papers), K. Toutanova and H. Wu, Eds. Baltimore, Maryland: Assoc. Comput. Linguistics, Jun. 2014, pp. 1220–1230.
- P. Ganesh and S. Dingliwal. Restructuring conversations using discourse relations for zero-shot abstractive dialogue summarization.
- C. E. Kahn, C. P. Langlotz, E. S. Burnside, J. A. Carrino, D. S. Channin, D. M. Hovsepian, and D. L. Rubin, “Toward best practices in radiology reporting,” Radiology, vol. 252, no. 3, pp. 852–856, 2009.
- S. Sotudeh Gharebagh, N. Goharian, and R. Filice, “Attend to medical ontologies: Content selection for clinical abstractive summarization,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 1899–1905.
- M. Adler, J. Berant, and I. Dagan, “Entailment-based text exploration with application to the health-care domain,” in Proc. ACL 2012 System Demonstrations, M. Zhang, Ed. Jeju Island, Korea: Assoc. Comput. Linguistics, Jul. 2012, pp. 79–84.
- Y. Zhang, D. Merck, E. Tsai, C. D. Manning, and C. Langlotz, “Optimizing the factual correctness of a summary: A study of summarizing radiology reports,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Assoc. Comput. Linguistics, Jul. 2020, pp. 5108–5120.
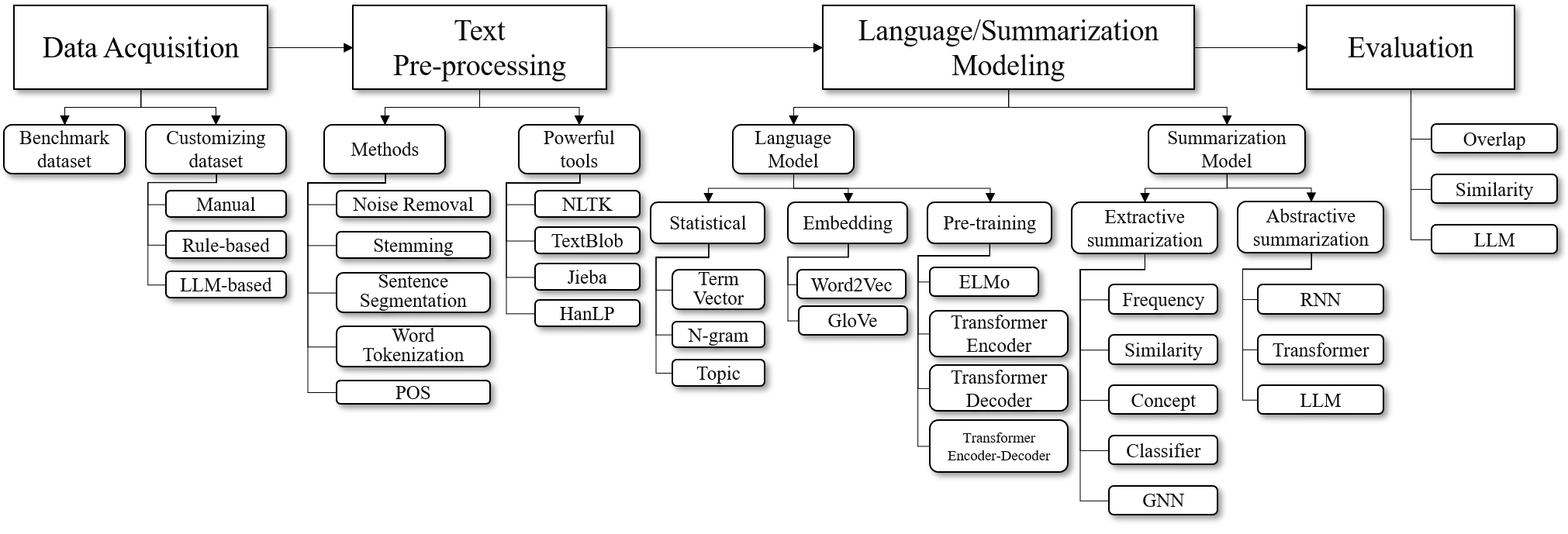
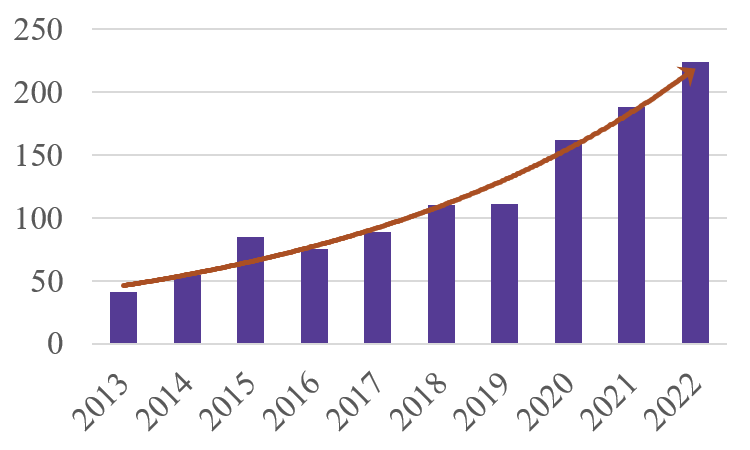
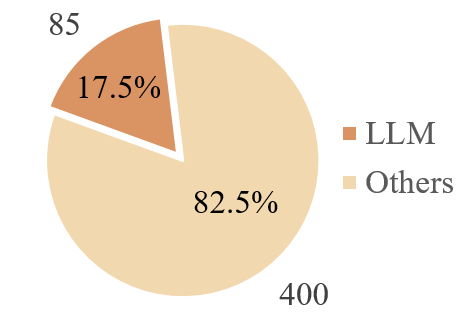
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

