2000 character limit reached
Breeze-7B Technical Report
Published 5 Mar 2024 in cs.CL | (2403.02712v2)
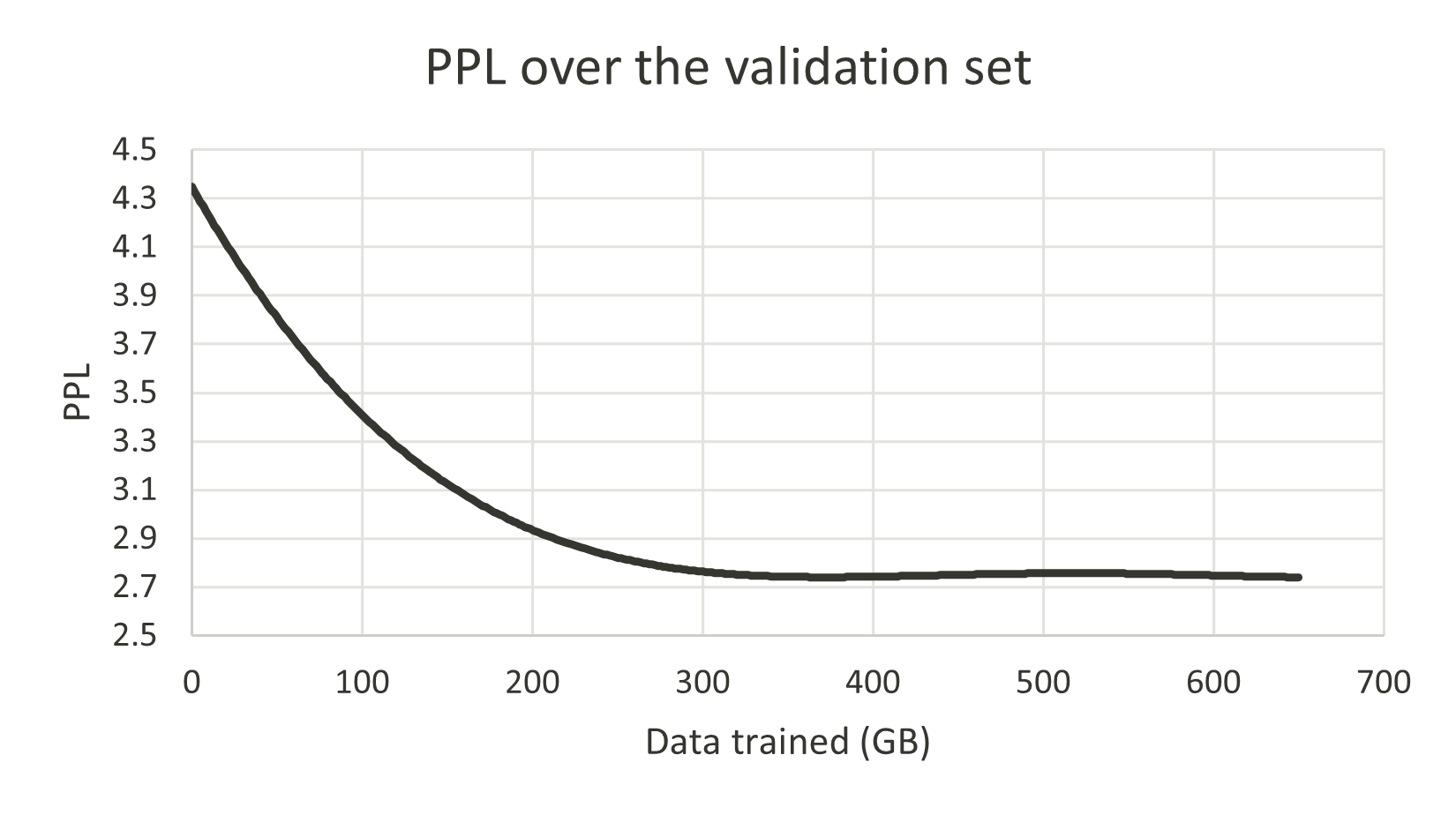
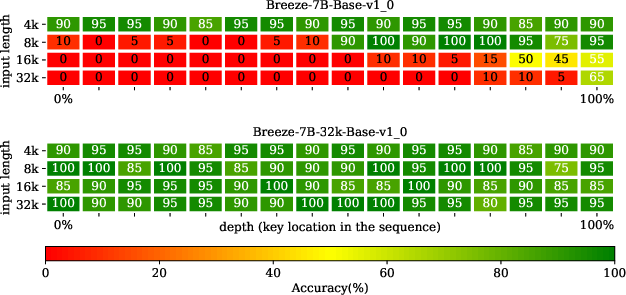
Abstract: Breeze-7B is an open-source LLM based on Mistral-7B, designed to address the need for improved language comprehension and chatbot-oriented capabilities in Traditional Chinese. This technical report provides an overview of the additional pretraining, finetuning, and evaluation stages for the Breeze-7B model. The Breeze-7B family of base and chat models exhibits good performance on language comprehension and chatbot-oriented tasks, reaching the top in several benchmarks among models comparable in its complexity class.
- The Falcon series of open language models, 2023.
- epfLLM Megatron-LLM, 2023. URL https://github.com/epfLLM/Megatron-LLM.
- Extending the pre-training of bloom for improved support of traditional chinese: Models, methods and results, 2023.
- Google Gemini-Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. 2024.
- Textbooks are all you need, June 2023. URL https://www.microsoft.com/en-us/research/publication/textbooks-are-all-you-need/.
- Advancing the evaluation of traditional chinese language models: Towards a comprehensive benchmark suite, 2023.
- Mistral 7B, 2023.
- Textbooks are all you need ii: phi-1.5 technical report. September 2023. URL https://www.microsoft.com/en-us/research/publication/textbooks-are-all-you-need-ii-phi-1-5-technical-report/.
- Chipnemo: Domain-adapted llms for chip design. arXiv preprint arXiv:2311.00176, 2023.
- Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- OpenAI. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Neural machine translation of rare words with subword units. In Katrin Erk and Noah A. Smith, editors, Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany, August 2016. Association for Computational Linguistics. doi: 10.18653/v1/P16-1162. URL https://aclanthology.org/P16-1162.
- Drcd: a chinese machine reading comprehension dataset. ArXiv, abs/1806.00920, 2018. URL https://api.semanticscholar.org/CorpusID:46932369.
- An improved traditional chinese evaluation suite for foundation model. arXiv, 2023.
- Llama 2: Open foundation and fine-tuned chat models, 2023.
- Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

