Exploring Data-Efficient Adaptation of Large Language Models for Code Generation
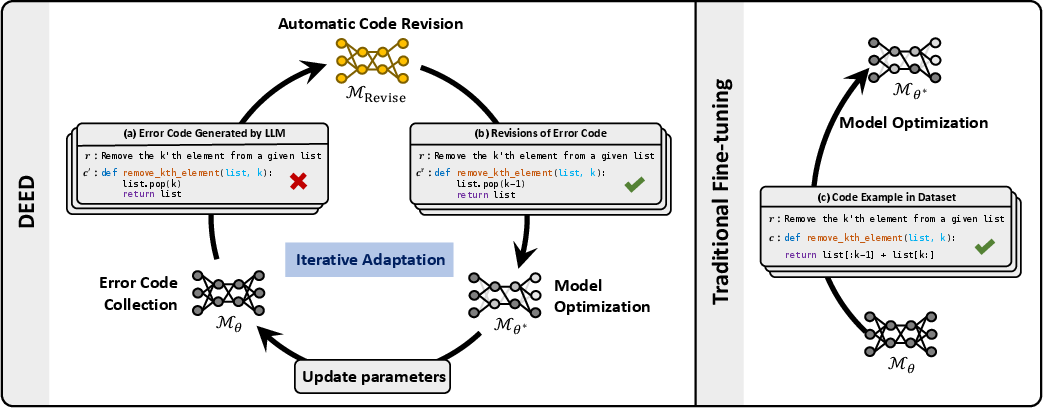
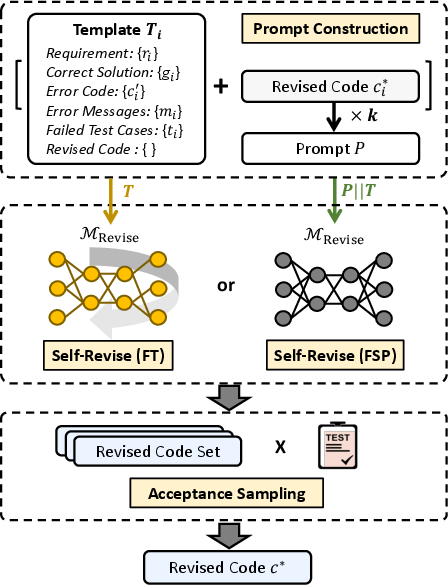
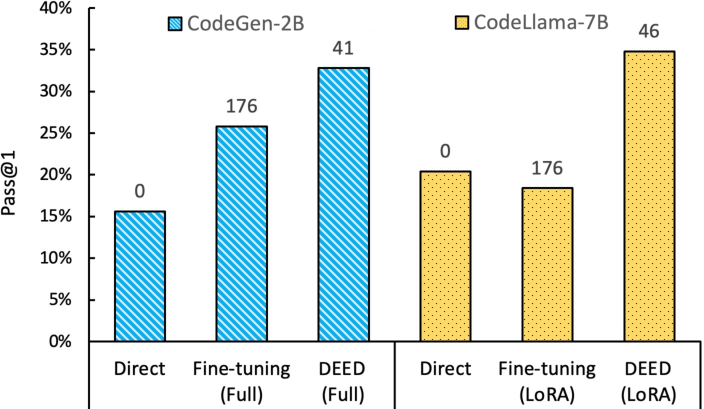
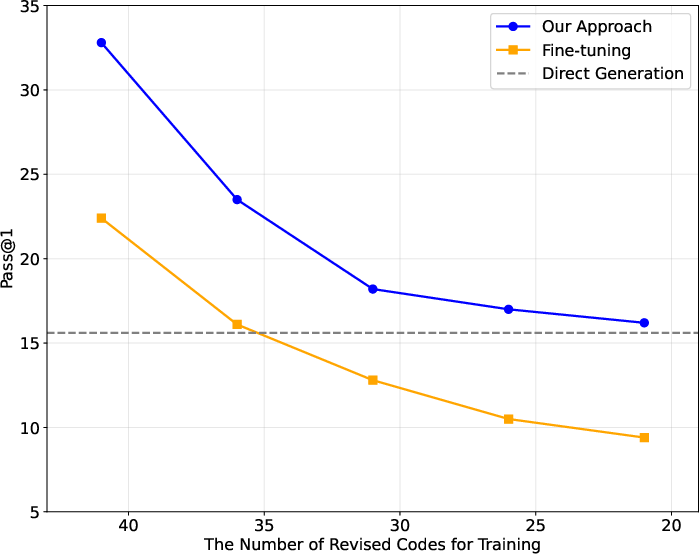
Abstract: Although LLMs have made significant progress in code generation, they still struggle with code generation tasks in specific scenarios. These scenarios usually necessitate the adaptation of LLMs to fulfill specific needs, but the limited training data available in practice leads to poor code generation performance. Therefore, how to effectively adapt LLMs to new scenarios with few training data is a major challenge for current code generation. In this paper, we propose a novel adaptation approach named DEED, which stands for Data-Efficient adaptation with Error-Driven learning for code generation. DEED leverages the errors made by LLMs as learning opportunities, using error revision to overcome their own shortcomings, thus achieving efficient learning. Specifically, DEED involves identifying error code generated by LLMs, employing Self-Revise for code revision, optimizing the model with revised code, and iteratively adapting the process for continuous improvement. Experimental results show that, compared to other mainstream fine-tuning approaches, DEED achieves superior performance with few training data, showing an average relative improvement of 46.2% in Pass@1 on multiple code generation benchmarks. We also validate the effectiveness of Self-Revise, which generates revised code that optimizes the model more efficiently compared to the code samples from datasets. Moreover, DEED consistently demonstrates strong performance across various LLMs, underscoring its applicability.
- A learning algorithm for boltzmann machines. Cogn. Sci., 9(1):147–169.
- Program synthesis with large language models. CoRR, abs/2108.07732.
- Language models are few-shot learners. In NeurIPS.
- Generalized accept-reject sampling schemes. Lecture Notes-Monograph Series, pages 342–347.
- Improving code generation by training with natural language feedback. CoRR, abs/2303.16749.
- Personalised distillation: Empowering open-sourced llms with adaptive learning for code generation. CoRR, abs/2310.18628.
- Evaluating large language models trained on code. CoRR.
- Teaching large language models to self-debug. CoRR, abs/2304.05128.
- Jeffrey Dean and Sanjay Ghemawat. 2008. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113.
- Parameter-efficient fine-tuning of large-scale pre-trained language models. Nat. Mac. Intell., 5(3):220–235.
- A survey for in-context learning. CoRR, abs/2301.00234.
- Codescore: Evaluating code generation by learning code execution. CoRR, abs/2301.09043.
- Self-collaboration code generation via chatgpt. CoRR, abs/2304.07590.
- Generalization or memorization: Data contamination and trustworthy evaluation for large language models. CoRR, abs/2402.15938.
- CODEP: grammatical seq2seq model for general-purpose code generation. In ISSTA, pages 188–198. ACM.
- Incoder: A generative model for code infilling and synthesis. CoRR, abs/2204.05999.
- The curious case of neural text degeneration. In ICLR. OpenReview.net.
- Parameter-efficient transfer learning for NLP. In ICML, volume 97 of Proceedings of Machine Learning Research, pages 2790–2799. PMLR.
- Lora: Low-rank adaptation of large language models. In ICLR. OpenReview.net.
- Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. In EMNLP, pages 5254–5276. Association for Computational Linguistics.
- Fine-tuning can distort pretrained features and underperform out-of-distribution. In ICLR. OpenReview.net.
- DS-1000: A natural and reliable benchmark for data science code generation. In ICML, volume 202 of Proceedings of Machine Learning Research, pages 18319–18345. PMLR.
- The power of scale for parameter-efficient prompt tuning. In EMNLP (1), pages 3045–3059. Association for Computational Linguistics.
- Starcoder: may the source be with you! CoRR, abs/2305.06161.
- Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In ACL/IJCNLP (1), pages 4582–4597. Association for Computational Linguistics.
- Competition-level code generation with alphacode. Science, 378(6624):1092–1097.
- Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv., 55(9):195:1–195:35.
- P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. CoRR, abs/2110.07602.
- GPT understands, too. CoRR, abs/2103.10385.
- Ilya Loshchilov and Frank Hutter. 2017. Fixing weight decay regularization in adam. CoRR, abs/1711.05101.
- Wizardcoder: Empowering code large language models with evol-instruct. CoRR, abs/2306.08568.
- Codegen: An open large language model for code with multi-turn program synthesis. In ICLR. OpenReview.net.
- OpenAI. 2022. ChatGPT.
- Improving language understanding by generative pre-training.
- Code llama: Open foundation models for code. CoRR, abs/2308.12950.
- Incorporating domain knowledge through task augmentation for front-end javascript code generation. In ESEC/SIGSOFT FSE, pages 1533–1543. ACM.
- Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
- Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Fine-tuning pre-trained language models effectively by optimizing subnetworks adaptively. In NeurIPS.
- Self-edit: Fault-aware code editor for code generation. In ACL (1), pages 769–787. Association for Computational Linguistics.
- Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x. CoRR, abs/2303.17568.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.