AdaMergeX: Cross-Lingual Transfer with Large Language Models via Adaptive Adapter Merging
Abstract: As an effective alternative to the direct fine-tuning on target tasks in specific languages, cross-lingual transfer addresses the challenges of limited training data by decoupling ''task ability'' and ''language ability'' by fine-tuning on the target task in the source language and another selected task in the target language, respectively. However, they fail to fully separate the task ability from the source language or the language ability from the chosen task. In this paper, we acknowledge the mutual reliance between task ability and language ability and direct our attention toward the gap between the target language and the source language on tasks. As the gap removes the impact of tasks, we assume that it remains consistent across tasks. Based on this assumption, we propose a new cross-lingual transfer method called $\texttt{AdaMergeX}$ that utilizes adaptive adapter merging. By introducing a reference task, we can determine that the divergence of adapters fine-tuned on the reference task in both languages follows the same distribution as the divergence of adapters fine-tuned on the target task in both languages. Hence, we can obtain target adapters by combining the other three adapters. Furthermore, we propose a structure-adaptive adapter merging method. Our empirical results demonstrate that our approach yields new and effective cross-lingual transfer, outperforming existing methods across all settings.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Composable sparse fine-tuning for cross-lingual transfer. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1778–1796.
- On the cross-lingual transferability of monolingual representations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4623–4637.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Towards making the most of cross-lingual transfer for zero-shot neural machine translation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 142–157.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Adaptersoup: Weight averaging to improve generalization of pretrained language models. In Findings of the Association for Computational Linguistics: EACL 2023, pages 2009–2018.
- Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451.
- Alexis Conneau and Guillaume Lample. 2019. Cross-lingual language model pretraining. Advances in neural information processing systems, 32.
- Xnli: Evaluating cross-lingual sentence representations. arXiv preprint arXiv:1809.05053.
- Zero-shot cross-lingual transfer with learned projections using unlabeled target-language data. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 449–457.
- Improving zero-shot multilingual neural machine translation by leveraging cross-lingual consistency regularization. arXiv preprint arXiv:2305.07310.
- Exploring the relationship between alignment and cross-lingual transfer in multilingual transformers. arXiv preprint arXiv:2306.02790.
- Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Xl-sum: Large-scale multilingual abstractive summarization for 44 languages. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4693–4703.
- Towards a unified view of parameter-efficient transfer learning. In International Conference on Learning Representations.
- Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Lorahub: Efficient cross-task generalization via dynamic lora composition. arXiv preprint arXiv:2307.13269.
- Not all languages are created equal in llms: Improving multilingual capability by cross-lingual-thought prompting. arXiv preprint arXiv:2305.07004.
- Editing models with task arithmetic. In The Eleventh International Conference on Learning Representations.
- Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, volume 1, page 2.
- Cross-lingual transfer learning for pos tagging without cross-lingual resources. In Proceedings of the 2017 conference on empirical methods in natural language processing, pages 2832–2838.
- Enhancing cross-lingual natural language inference by soft prompting with multilingual verbalizer. arXiv preprint arXiv:2305.12761.
- Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Machine-created universal language for cross-lingual transfer. arXiv preprint arXiv:2305.13071.
- Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81.
- Choosing transfer languages for cross-lingual learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, volume 57.
- Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 35:1950–1965.
- Is prompt-based finetuning always better than vanilla finetuning? insights from cross-lingual language understanding. arXiv preprint arXiv:2307.07880.
- Michael S Matena and Colin A Raffel. 2022. Merging models with fisher-weighted averaging. Advances in Neural Information Processing Systems, 35:17703–17716.
- Mass-editing memory in a transformer. In The Eleventh International Conference on Learning Representations.
- Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- Memory-based model editing at scale. In International Conference on Machine Learning, pages 15817–15831. PMLR.
- Enhancing cross-lingual transfer via phonemic transcription integration. arXiv preprint arXiv:2307.04361.
- OpenAI. 2022. Chatgpt: Optimizing language models for dialogue. OpenAI Blog.
- OpenAI. 2023. Gpt-4 technical report.
- Contrastive learning for many-to-many multilingual neural machine translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 244–258.
- Mad-x: An adapter-based framework for multi-task cross-lingual transfer. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7654–7673.
- Xcopa: A multilingual dataset for causal commonsense reasoning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2362–2376.
- Combining parameter-efficient modules for task-level generalisation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 687–702.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- Pixel representations for multilingual translation and data-efficient cross-lingual transfer. arXiv preprint arXiv:2305.14280.
- Cross-lingual transfer learning for multilingual task oriented dialog. In Proceedings of NAACL-HLT, pages 3795–3805.
- Language models are multilingual chain-of-thought reasoners. In The Eleventh International Conference on Learning Representations.
- Multilingual llms are better cross-lingual in-context learners with alignment. arXiv preprint arXiv:2305.05940.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Attention is all you need. Advances in neural information processing systems, 30.
- Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International Conference on Machine Learning, pages 23965–23998. PMLR.
- mt5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498.
- Resolving interference when merging models. arXiv preprint arXiv:2306.01708.
- Composing parameter-efficient modules with arithmetic operations. arXiv preprint arXiv:2306.14870.
- Contrastive data and learning for natural language processing. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Tutorial Abstracts, pages 39–47.
- M3Exam: A multilingual, multimodal, multilevel benchmark for examining large language models. arXiv preprint arXiv:2306.05179.
- Extrapolating large language models to non-english by aligning languages. arXiv preprint arXiv:2308.04948.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to help LLMs do well on tasks in many different languages, especially when some languages don’t have much training data. The method is called AdaMergeX. Instead of trying to completely separate “task skills” (like answering questions) from “language skills” (like understanding French), AdaMergeX accepts that these skills influence each other and cleverly combines them to transfer knowledge from a language with lots of data (like English) to a language with less data (like Swahili).
Key Questions
The paper asks:
- How can we get an LLM to perform a task in a target language when we don’t have much labeled data in that language?
- Can we use what the model learns in a source language (like English) and adapt it to a target language (like Thai), without retraining the whole model?
- Is there a reliable way to measure and apply the “language gap” (how different two languages behave inside the model) across different tasks?
How They Did It (Methods)
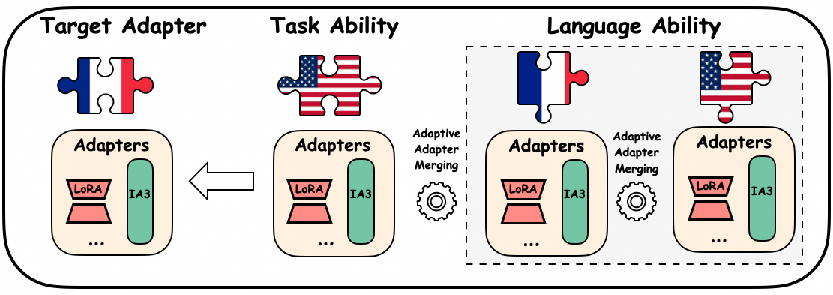
The authors use a practical approach based on “adapters,” which are small add-on modules you attach to a big model so you can update just the adapter instead of the entire model. Think of adapters like detachable tool pieces: instead of rebuilding the whole machine, you swap or tweak a small part to make it good at a new task or language.
What is an adapter?
- An adapter is a small set of extra parameters added to the model. During fine-tuning, you only adjust this small add-on, not the whole model. This saves time and data.
- Adapters can be different types. Two popular ones are:
- LoRA: acts like adding small “notes” to the model’s weights (it uses addition).
- IA3: acts like turning “volume knobs” up or down on certain parts of the model (it uses multiplication).
The main idea: a “reference task” and merging adapters
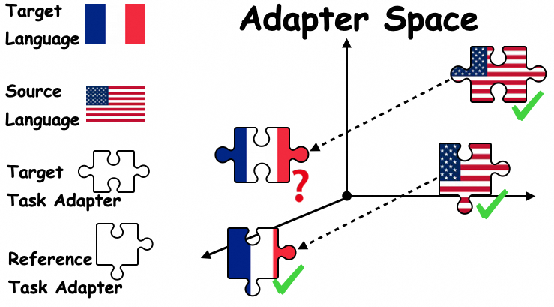
- The authors noticed something important: the difference between how the model behaves in two languages (say English vs. French) is similar no matter what task you look at. It’s like a consistent “language gap.”
- Picture this like a puzzle with four adapter pieces: 1) Adapter for the target task in the source language (for example, question answering in English). 2) Adapter for a reference task in the source language (for example, predicting the next word in English). 3) Adapter for the same reference task in the target language (predicting the next word in French). 4) Adapter we want: the target task in the target language (question answering in French).
If you have the first three, you can combine them to get the fourth. It’s like knowing three corners of a rectangle lets you figure out the fourth.
- The “reference task” is chosen to be easy to build in any language using unlabeled text (for example, causal language modeling: predicting the next word). Because it’s easy, you can get adapters for the source and target languages without labels.
Structure-adaptive merging
- Because different adapters work differently, the way you merge them should match their design:
- For LoRA (which is additive), you merge using addition/subtraction.
- For IA3 (which is multiplicative), you merge using multiplication/division.
- For other adapters like Prefix-Tuning (which uses extra “prefix” tokens), you use a math operation that fits their structure.
- This “structure-adaptive” idea means the merging method isn’t one-size-fits-all; it’s tailored to how each adapter plugs into the model.
In everyday terms
- Task ability: the model’s skill at doing something (like summarizing or answering questions).
- Language ability: how comfortable the model is with a specific language.
- Language gap: the consistent “difference” between two languages inside the model.
- AdaMergeX uses a reference task to measure the language gap, then combines that with the task skill learned in the source language to create the target-language adapter.
Main Findings
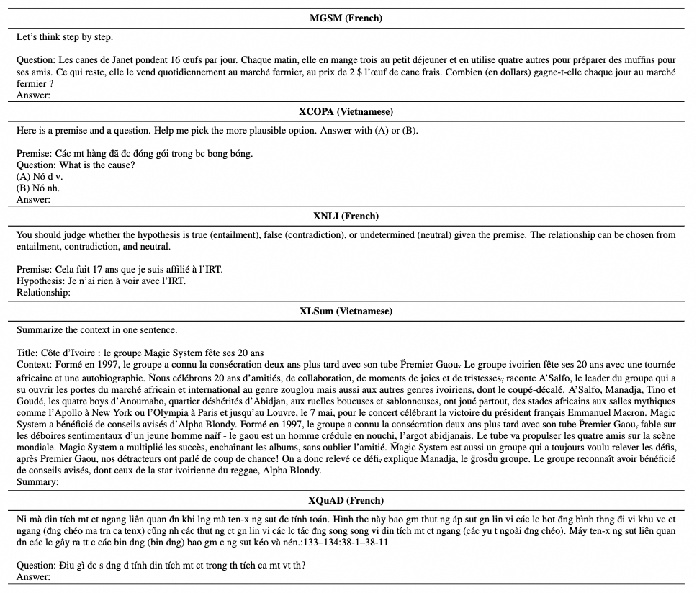
The authors tested AdaMergeX across 12 languages and several tasks:
- Reasoning: math word problems (MGSM), commonsense (XCOPA)
- Understanding: natural language inference (XNLI), question answering (XQuAD)
- Generation: summarization (XLSum)
They compared AdaMergeX to:
- Using the model “as-is” (zero-shot),
- Fine-tuning on English and directly transferring to other languages,
- Fancy prompting methods that translate back and forth (XLT),
- Other adapter merging methods (like simple arithmetic merging),
- Methods that try to separately fine-tune “task” and “language” parts (MAD-X, LF-SFT).
Key results:
- AdaMergeX consistently beat direct transfer and prompting methods across tasks.
- Against MAD-X, AdaMergeX had big gains (for example, about +8% on XCOPA and +15.9% on XQuAD).
- Compared to a strong adapter-merging baseline (AriMerge), AdaMergeX showed substantial improvements (for LLaMA2, about 31% relative improvement across all languages and tasks in their tests).
- It worked well across different backbone models (like LLaMA2 and XLM-R) and adapter types (LoRA, IA3), and across different source languages and reference tasks.
- A special note: matching the merging method to the adapter type made a big difference. Using the “wrong” merge (like multiplying for an additive adapter) hurt performance a lot.
Why This Matters
- Many languages don’t have much labeled data. AdaMergeX reduces the need for expensive, language-specific training by:
- Learning the task in a language with lots of data (like English),
- Measuring the language gap using an easy reference task in both languages (no labels needed),
- Merging the pieces to get a strong adapter for the target language and target task.
- This helps make AI more inclusive, improving performance for low-resource languages without heavy data collection.
Takeaways and Future Impact
- AdaMergeX offers a practical, efficient way to do cross-lingual transfer in LLMs by embracing the connection between task skills and language skills.
- It’s flexible: it works with different models, different adapters, and different languages.
- It’s powerful: it outperforms several state-of-the-art methods.
- Limitations: the experiments mainly used medium-sized models (around 7B parameters). Running this on much larger models could provide more insights. Also, fine-tuning the reference task still takes some time, though it’s much cheaper than collecting labeled data in many languages.
- Overall, AdaMergeX could help future multilingual systems handle more tasks in more languages, fairly and efficiently.
Glossary
- AdaMergeX: A proposed method for cross-lingual transfer that merges task and language abilities via adaptive adapter merging. "we propose a new cross-lingual transfer method called AdaMergeX that utilizes adaptive adapter merging."
- Adapter: A small trainable module inserted into a pre-trained model to enable parameter-efficient fine-tuning. "Adapter & Prefix-Tuning By inserting layers and prefix tokens into the model, combination methods of Adapter and Prefix-Tuning can be for- mulated as"
- Adapter merging: The process of combining adapters (or their effects) to integrate capabilities learned separately. "we propose to accomplish the cross- lingual transfer through Adaptive Adapter Merging (AdaMergeX)"
- Adapter space: The parameter space formed by adapter parameters, in which relationships like language gaps are analyzed. "in the adapter space, the diver- gence between the target language and source lan- guage on the target task follows the same distribu- tion as the divergence on the reference task."
- AriMerge: An arithmetic adapter-merging baseline that combines adapters via simple addition. "Arithmetic Merging ('AriMerge') (Zhang et al., 2023a), which is the state-of-the-art adapter merg- ing method by arithmetic addition."
- Backbone model: The underlying pre-trained model to which adapters are attached and on which methods are evaluated. "The backbone model that we use to test AdaMergeX is Llama2-7b (Touvron et al., 2023) for LoRA and (IA)3"
- Causal language modeling: A reference task where the model predicts the next token from previous tokens, used to estimate language ability. "we employ conventional causal language modeling as the ref- erence task, where the prediction of the subsequent token is based on preceding inputs."
- Cross-Lingual-Thought Prompting (XLT): A prompting strategy that translates to a source language for reasoning and back to the target language. "Cross-Lingual-Thought Prompting ('XLT (Vanilla)') (Huang et al., 2023b) achieves state-of-the-art results on cross-lingual transfer with LLMs through carefully designed prompt tem- plate"
- Cross-lingual transfer: Transferring task-solving capability from a source language to a target language, often to address low-resource settings. "cross-lingual transfer is intro- duced to extend the task-solving ability in a source language to a wide range of target languages"
- Decoder-only model: A generative architecture that uses only the decoder stack (e.g., Llama2) and is referenced as a backbone type. "Not limited to Decode-only Models such as Llama2, we do further analy- sis on Encoder-Decoder model T5-base"
- Divergence (between adapters): A measure of difference between adapters fine-tuned for different languages or tasks, used to estimate language gaps. "we can determine that the divergence of adapters fine-tuned on the reference task in both lan- guages follows the same distribution as the di- vergence of adapters fine-tuned on the target task in both languages."
- Encoder-Decoder model: A sequence-to-sequence architecture with separate encoder and decoder stacks (e.g., T5). "we do further analy- sis on Encoder-Decoder model T5-base (Raffel"
- Encoder-only model: An architecture that uses only the encoder stack (e.g., XLM-R), typically for classification tasks. "we only test XCOPA and XQuAD because encoder-only models can only be applied to classification tasks."
- Hyper-parameter (t): A scaling parameter used in the merging equations to align distributions across tasks/languages. "t is the hyper-parameter that adapts the scale of two distributions in the same family of distributions."
- (IA)3: A parameter-efficient fine-tuning method that applies element-wise multiplicative scaling to selected Transformer components. "(IA)3 specializes the combination method to element-wise multiplication 'O':"
- In-context learning: A paradigm where models perform tasks by conditioning on prompts/examples without updating weights, referenced in related work. "in the era of in-context learning (Brown et al., 2020; Chowdhery et al., 2022; Touvron et al., 2023; Ope- nAI, 2023)"
- Invertible adapters: Adapters designed so that their transformations are invertible, enabling certain forms of decomposition. "MAD- X (Pfeiffer et al., 2020) decomposes language and task via independent invertible adapters."
- Language ability: The model’s general proficiency in a language or the capacity gap between target and source languages. "language ability refers to the ca- pacity gap between the target language and the source language."
- LF-SFT: A baseline that performs sparse fine-tuning separately for language and task, merging the results by addition. "LF- SFT (Ansell et al., 2022) adopts sparse fine-tuning on language and task respectively and directly merging via addition."
- LoRA: A parameter-efficient fine-tuning method that injects low-rank additive updates into model weights. "LoRA employs low-rank decomposition to reduce training complexity."
- Low-rank decomposition: Factorizing a weight update into low-rank matrices to reduce training cost in PEFT methods like LoRA. "LoRA employs low-rank decomposition to reduce training complexity."
- MAD-X: An adapter-based framework that decouples language and task components for cross-lingual transfer. "MAD- X (Pfeiffer et al., 2020) decomposes language and task via independent invertible adapters."
- Mixture of Experts (MoE): An architecture with multiple expert modules where a gating mechanism selects experts; suggested to reduce training cost. "language-specific Mixture of Experts (MoE) techniques"
- Model merging: Combining parameters or modules from multiple models/adapters to integrate capabilities. "we conduct comparisons between our proposed method, which utilizes model merging for achieving cross-lingual transfer"
- Moore–Penrose pseudo-inverse: A generalized matrix inverse used in the proposed merging for certain adapter structures. "A71 represents Moore-Penrose pseudo-inverse of the matrix."
- Parameter-efficient fine-tuning (PEFT): Techniques that adapt large models by training small additional modules rather than full parameters. "During such parameter-efficient fine- tuning, pre-trained parameters W0 are fixed and only adapter parameters WA are updated."
- Prefix-Tuning: A PEFT method that prepends trainable continuous tokens to each layer’s input to steer model behavior. "Prefix-Tuning (Li and Liang, 2021)"
- Reference task: An auxiliary task available in both source and target languages used to estimate and transfer language ability. "we introduce a reference task from which we obtain the divergence between the target language and source lan- guage."
- Representation alignment: Methods aiming to align latent representations across languages to aid transfer. "representation alignment (Nguyen et al., 2023; Salesky et al., 2023; Gao et al., 2023)"
- ROUGE-L: An evaluation metric for summarization based on longest common subsequence overlap. "we evaluate the performance by ROUGE-L score (Lin, 2004)."
- Task ability: The model’s competence at performing a specific task independent of language. "the ability to solve a certain task ('task-ability') from a source language"
- Transformer: A neural architecture based on self-attention, forming the basis of models discussed. "the Transformer (Vaswani et al., 2017) architecture, including the attention layer and the feed-forward layer."
- Word embedding space: The vector space where words are represented as embeddings, used to draw analogies. "In line with the famous equation 'king - queen = man - woman' in the word em- bedding space"
- Zero-shot prompting: Evaluating a model on tasks in new languages without fine-tuning, using only prompts. "Vanilla zero-shot prompt- ing ('Vanilla'), which directly assesses target lan- guages using the pre-trained LLM."
Collections
Sign up for free to add this paper to one or more collections.

