Multi-objective Differentiable Neural Architecture Search
Abstract: Pareto front profiling in multi-objective optimization (MOO), i.e., finding a diverse set of Pareto optimal solutions, is challenging, especially with expensive objectives that require training a neural network. Typically, in MOO for neural architecture search (NAS), we aim to balance performance and hardware metrics across devices. Prior NAS approaches simplify this task by incorporating hardware constraints into the objective function, but profiling the Pareto front necessitates a computationally expensive search for each constraint. In this work, we propose a novel NAS algorithm that encodes user preferences to trade-off performance and hardware metrics, yielding representative and diverse architectures across multiple devices in just a single search run. To this end, we parameterize the joint architectural distribution across devices and multiple objectives via a hypernetwork that can be conditioned on hardware features and preference vectors, enabling zero-shot transferability to new devices. Extensive experiments involving up to 19 hardware devices and 3 different objectives demonstrate the effectiveness and scalability of our method. Finally, we show that, without any additional costs, our method outperforms existing MOO NAS methods across a broad range of qualitatively different search spaces and datasets, including MobileNetV3 on ImageNet-1k, an encoder-decoder transformer space for machine translation and a decoder-only space for language modelling.
- Getting vit in shape: Scaling laws for compute-optimal model design. Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Understanding and simplifying one-shot architecture search. In Proceedings of the 35th International Conference on Machine Learning (ICML'18), volume 80. Proceedings of Machine Learning Research, 2018.
- Hardware-aware neural architecture search: Survey and taxonomy. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pp. 4322–4329, 8 2021. Survey Track.
- SMASH: One-shot model architecture search through hypernetworks. In International Conference on Learning Representations, 2018.
- Proxylessnas: Direct neural architecture search on target task and hardware. In International Conference on Learning Representations, 2018.
- Once-for-All: Train one network and specialize it for efficient deployment. In International Conference on Learning Representations (ICLR), 2020.
- Autoformer: Searching transformers for visual recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 12270–12280, 2021a.
- DrNAS: Dirichlet neural architecture search. In International Conference on Learning Representations, 2021b.
- Fairer and more accurate tabular models through nas. Algorithmic Fairness through the Lens of Time Workshop at NeurIPS, 2023.
- Multi-objective bayesian optimization over high-dimensional search spaces. In Uncertainty in Artificial Intelligence, pp. 507–517. PMLR, 2022.
- A fast elitist non-dominated sorting genetic algorithm for multi-objective optimization: Nsga-ii. In Parallel Problem Solving from Nature PPSN VI: 6th International Conference Paris, France, September 18–20, 2000 Proceedings 6, pp. 849–858. Springer, 2000.
- A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE transactions on evolutionary computation, 6(2):182–197, 2002.
- Désidéri, J.-A. Multiple-gradient descent algorithm (mgda) for multiobjective optimization. Comptes Rendus Mathematique, 350:313–318, 2012.
- Searching for a robust neural architecture in four gpu hours. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- NAS-Bench-201: Extending the scope of reproducible neural architecture search. In Proceedings of the International Conference on Learning Representations (ICLR'20), 2020. Published online: iclr.cc.
- Rethinking bias mitigation: Fairer architectures make for fairer face recognition. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Brp-nas: Prediction-based nas using gcns. Advances in Neural Information Processing Systems, 33:10480–10490, 2020.
- Efficient multi-objective neural architecture search via lamarckian evolution. In International Conference on Learning Representations, 2019a.
- Efficient multi-objective neural architecture search via lamarckian evolution. In International Conference on Learning Representations, 2019b.
- AutoGAN-distiller: Searching to compress generative adversarial networks. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 3292–3303. PMLR, 13–18 Jul 2020.
- Gunantara, N. A review of multi-objective optimization: Methods and its applications. Cogent Engineering, 5(1):1502242, 2018.
- Single path one-shot neural architecture search with uniform sampling. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVI 16, pp. 544–560. Springer, 2020.
- Hypernetworks. In Proceedings of the International Conference on Learning Representations (ICLR'17), 2017.
- Improving pareto front learning via multi-sample hypernetworks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp. 7875–7883, 2023.
- An empirical analysis of compute-optimal large language model training. In Advances in Neural Information Processing Systems, volume 35, pp. 30016–30030. Curran Associates, Inc., 2022.
- Monas: Multi-objective neural architecture search using reinforcement learning. arXiv preprint arXiv:1806.10332, 2018.
- Ofa 22{}^{2}start_FLOATSUPERSCRIPT 2 end_FLOATSUPERSCRIPT: A multi-objective perspective for the once-for-all neural architecture search. arXiv preprint arXiv:2303.13683, 2023.
- Jaggi, M. Revisiting frank-wolfe: Projection-free sparse convex optimization. In International Conference on Machine Learning, 2013.
- Categorical reparameterization with gumbel-softmax. In Proceedings of the International Conference on Learning Representations (ICLR'17), 2017. Published online: iclr.cc.
- Montreal neural machine translation systems for wmt’15. In Proceedings of the tenth workshop on statistical machine translation, pp. 134–140, 2015.
- Eh-dnas: End-to-end hardware-aware differentiable neural architecture search. arXiv preprint arXiv:2111.12299, 2021.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Mdarts: Multi-objective differentiable neural architecture search. In 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 1344–1349. IEEE, 2021.
- Rapid neural architecture search by learning to generate graphs from datasets. In International Conference on Learning Representations, 2021a.
- Hardware-adaptive efficient latency prediction for nas via meta-learning. In Advances in Neural Information Processing Systems, volume 34, pp. 27016–27028. Curran Associates, Inc., 2021b.
- S3nas: Fast npu-aware neural architecture search methodology. arXiv preprint arXiv:2009.02009, 2020.
- Hw-nas-bench: Hardware-aware neural architecture search benchmark. In International Conference on Learning Representations, 2021.
- Random search and reproducibility for neural architecture search. In Peters, J. and Sontag, D. (eds.), Proceedings of The 36th Uncertainty in Artificial Intelligence Conference (UAI'20), pp. 367–377. PMLR, 2020.
- Pareto multi-task learning. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- Controllable pareto multi-task learning. ArXiv, abs/2010.06313, 2020.
- DARTS: Differentiable architecture search. In International Conference on Learning Representations, 2019.
- Bridging discrete and backpropagation: Straight-through and beyond. Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- The stochastic multi-gradient algorithm for multi-objective optimization and its application to supervised machine learning. Annals of Operations Research, pp. 1572–9338, 2021.
- Nsganetv2: Evolutionary multi-objective surrogate-assisted neural architecture search. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, pp. 35–51. Springer, 2020.
- Results of the WMT14 metrics shared task. In Proceedings of the Ninth Workshop on Statistical Machine Translation, pp. 293–301, Baltimore, Maryland, USA, June 2014. Association for Computational Linguistics. doi: 10.3115/v1/W14-3336.
- Multi-task learning with user preferences: Gradient descent with controlled ascent in pareto optimization. In Proceedings of the 36th International Conference on Machine Learning (ICML'20), pp. 6597–6607. Proceedings of Machine Learning Research, 2020.
- Minimax pareto fairness: A multi objective perspective. In International Conference on Machine Learning, pp. 6755–6764. PMLR, 2020.
- A multi-objective/multi-task learning framework induced by pareto stationarity. In International Conference on Machine Learning, pp. 15895–15907. PMLR, 2022.
- λ𝜆\lambdaitalic_λ-darts: Mitigating performance collapse by harmonizing operation selection among cells. The Eleventh International Conference on Learning Representations, 2022.
- Learning the pareto front with hypernetworks. International Conference on Learning Representations, 2021.
- Efficient neural architecture search via parameter sharing. In International Conference on Machine Learning, 2018.
- Stochastic multiple target sampling gradient descent. Advances in neural information processing systems, 35:22643–22655, 2022.
- Speedy performance estimation for neural architecture search. In Advances in Neural Information Processing Systems, 2021.
- Scalable pareto front approximation for deep multi-objective learning. In 2021 IEEE international conference on data mining (ICDM), pp. 1306–1311. IEEE, 2021.
- Convolutional neural fabrics. Advances in neural information processing systems, 29, 2016.
- Multi-task learning as multi-objective optimization. In Neural Information Processing Systems, 2018.
- Squeezenas: Fast neural architecture search for faster semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp. 0–0, 2019.
- Weight-entanglement meets gradient-based neural architecture search. arXiv preprint arXiv:2312.10440, 2023.
- Mnasnet: Platform-aware neural architecture search for mobile. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12965–12974, 2020.
- Attentivenas: Improving neural architecture search via attentive sampling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6418–6427, 2021.
- Hat: Hardware-aware transformers for efficient natural language processing. arXiv:2005.14187[cs.CL], 2020a.
- HAT: Hardware-aware transformers for efficient natural language processing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7675–7688, Online, July 2020b. Association for Computational Linguistics.
- Learning to prompt for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 139–149, 2022.
- Neural architecture search: Insights from 1000 papers. ArXiv, abs/2301.08727, 2023.
- Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10734–10742, 2019.
- Trilevel neural architecture search for efficient single image super-resolution. arXiv preprint arXiv:2101.06658, 2021.
- SNAS: stochastic neural architecture search. In International Conference on Learning Representations, 2019.
- Pc-darts: Partial channel connections for memory-efficient architecture search. In International Conference on Learning Representations, 2020a.
- Latency-aware differentiable neural architecture search. arXiv preprint arXiv:2001.06392, 2020b.
- Pareto navigation gradient descent: a first-order algorithm for optimization in pareto set. In Uncertainty in Artificial Intelligence, pp. 2246–2255. PMLR, 2022.
- Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12104–12113, 2022.
- Fast hardware-aware neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 692–693, 2020.
- idarts: Differentiable architecture search with stochastic implicit gradients. In International Conference on Machine Learning, 2021.
- Neural architecture search with reinforcement learning. In Proceedings of the International Conference on Learning Representations (ICLR'17), 2017.
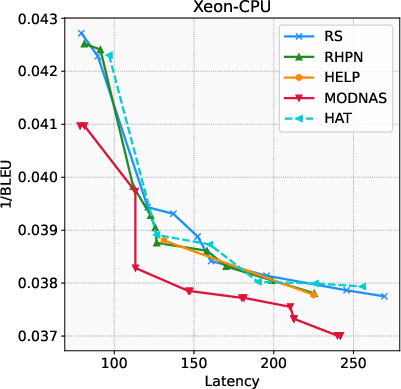
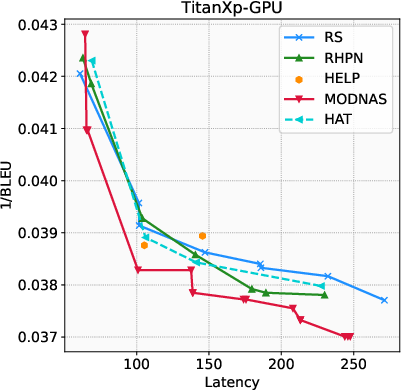
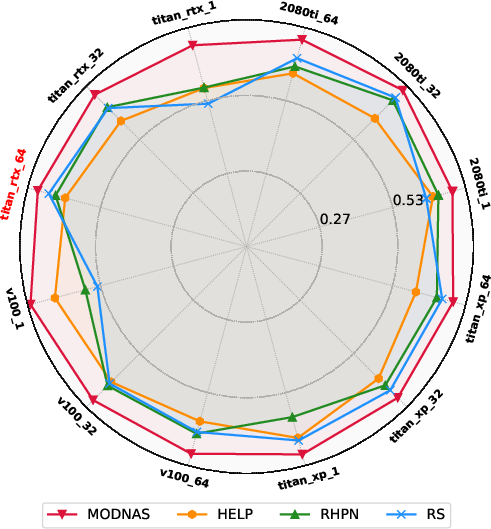
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

