Adversarial Math Word Problem Generation
Abstract: LLMs have significantly transformed the educational landscape. As current plagiarism detection tools struggle to keep pace with LLMs' rapid advancements, the educational community faces the challenge of assessing students' true problem-solving abilities in the presence of LLMs. In this work, we explore a new paradigm for ensuring fair evaluation -- generating adversarial examples which preserve the structure and difficulty of the original questions aimed for assessment, but are unsolvable by LLMs. Focusing on the domain of math word problems, we leverage abstract syntax trees to structurally generate adversarial examples that cause LLMs to produce incorrect answers by simply editing the numeric values in the problems. We conduct experiments on various open- and closed-source LLMs, quantitatively and qualitatively demonstrating that our method significantly degrades their math problem-solving ability. We identify shared vulnerabilities among LLMs and propose a cost-effective approach to attack high-cost models. Additionally, we conduct automatic analysis to investigate the cause of failure, providing further insights into the limitations of LLMs.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712.
- Can gpt models be financial analysts? an evaluation of chatgpt and gpt-4 on mock cfa exams. arXiv preprint arXiv:2310.08678.
- Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447.
- Chaka Chaka. 2023. Detecting ai content in responses generated by chatgpt, youchat, and chatsonic: The case of five ai content detection tools. Journal of Applied Learning and Teaching, 6(2).
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023).
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR.
- Solving math word problems by combining language models with symbolic solvers. arXiv preprint arXiv:2304.09102.
- Adversarial examples are not bugs, they are features. Advances in neural information processing systems, 32.
- Mathprompter: Mathematical reasoning using large language models. In Proceedings of the The 61st Annual Meeting of the Association for Computational Linguistics: Industry Track, ACL 2023, Toronto, Canada, July 9-14, 2023, pages 37–42. Association for Computational Linguistics.
- Mistral 7b. arXiv preprint arXiv:2310.06825.
- A watermark for large language models. arXiv preprint arXiv:2301.10226.
- Performance of chatgpt on usmle: Potential for ai-assisted medical education using large language models. PLoS digital health, 2(2):e0000198.
- Chain of code: Reasoning with a language model-augmented code emulator. arXiv preprint arXiv:2312.04474.
- Gpt detectors are biased against non-native english writers. arXiv preprint arXiv:2304.02819.
- Detectgpt: Zero-shot machine-generated text detection using probability curvature. arXiv preprint arXiv:2301.11305.
- OpenAI. 2022. Chatgpt: Optimizing language models for dialogue. Accessed: 2023-01-10.
- OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
- Subhro Roy and Dan Roth. 2015. Solving general arithmetic word problems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1743–1752, Lisbon, Portugal. Association for Computational Linguistics.
- Reasoning about quantities in natural language. Transactions of the Association for Computational Linguistics, 3:1–13.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Can ai-generated text be reliably detected? arXiv preprint arXiv:2303.11156.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Adversarial glue: A multi-task benchmark for robustness evaluation of language models. arXiv preprint arXiv:2111.02840.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244.
- Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284.
- Adversarial attacks on deep-learning models in natural language processing: A survey. ACM Transactions on Intelligent Systems and Technology (TIST), 11(3):1–41.
- Mathattack: Attacking large language models towards math solving ability. arXiv preprint arXiv:2309.01686.
- Promptbench: Towards evaluating the robustness of large language models on adversarial prompts. arXiv preprint arXiv:2306.04528.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.
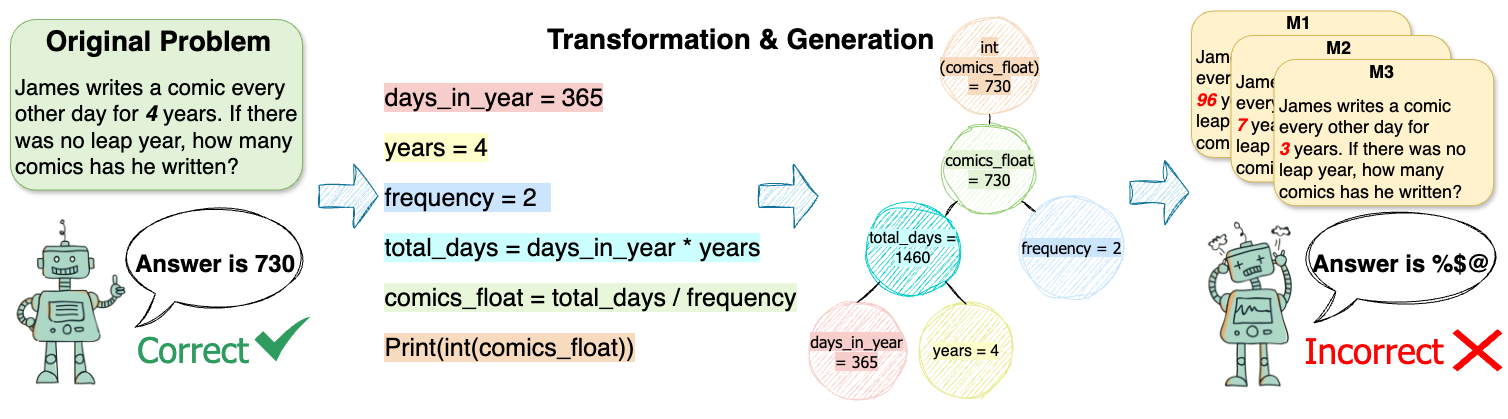
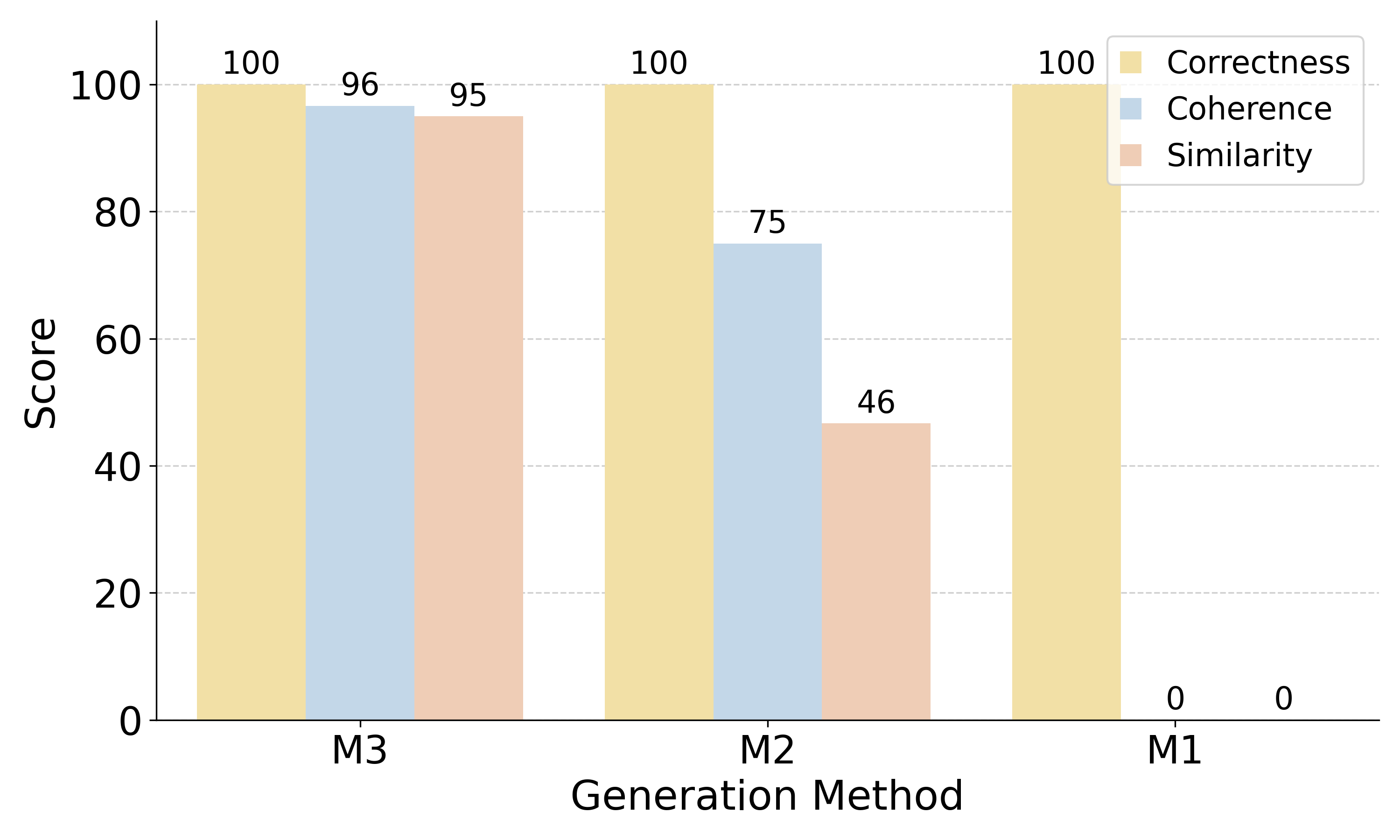
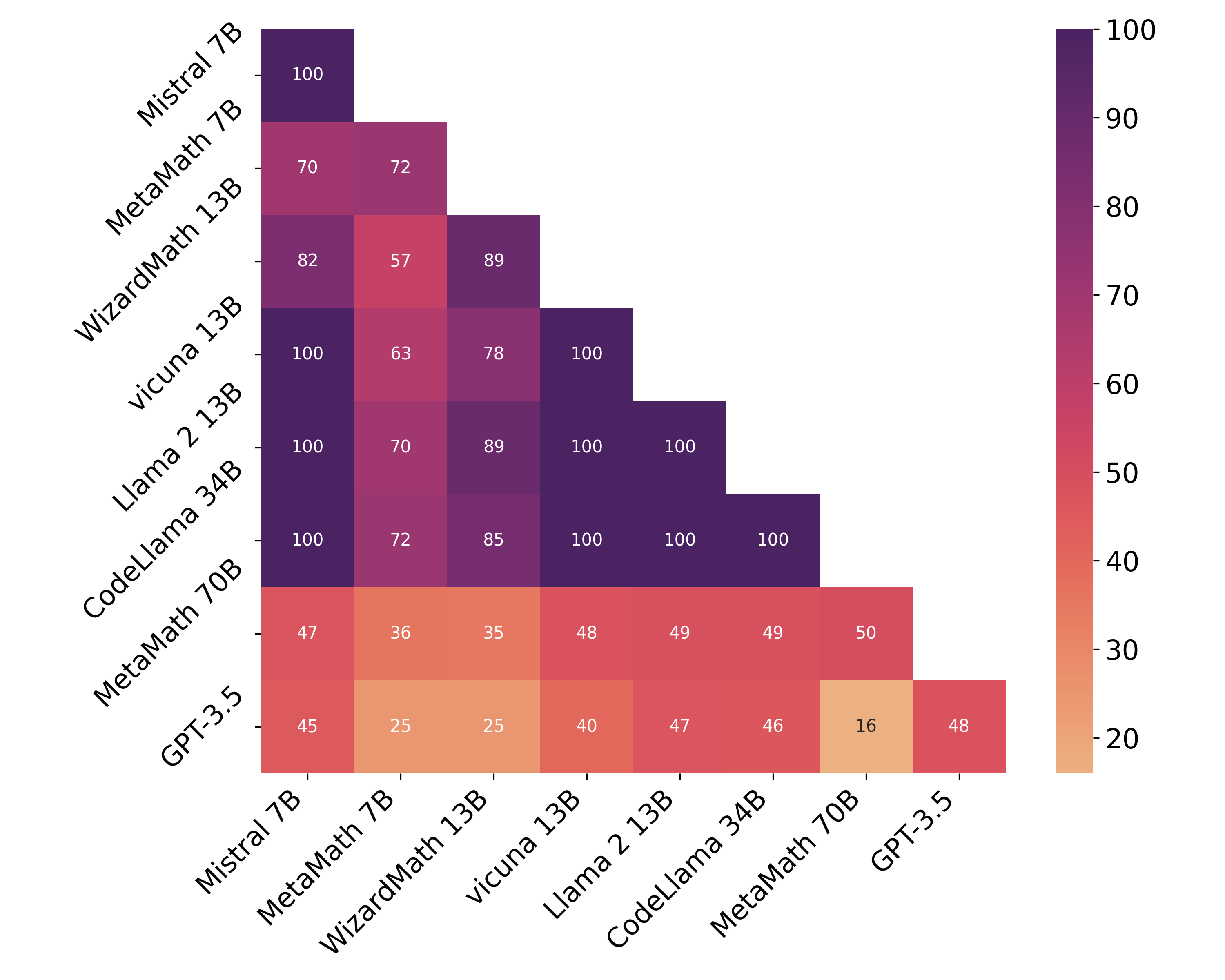
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.