GenCode: A Generic Data Augmentation Framework for Boosting Deep Learning-Based Code Understanding
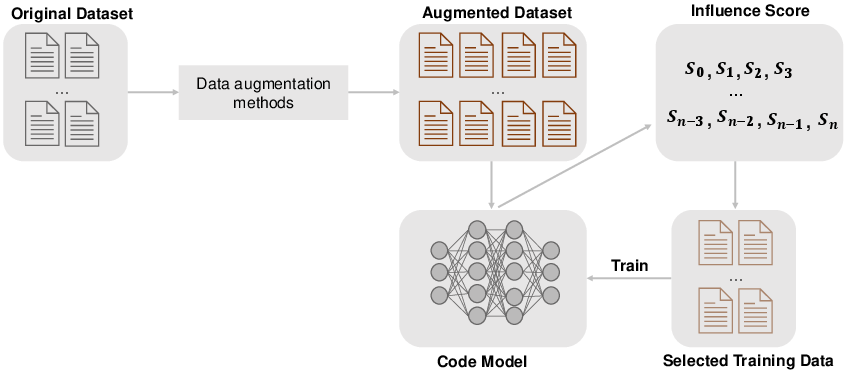
Abstract: Pre-trained code models lead the era of code intelligence, with multiple models designed with impressive performance. However, one important problem, data augmentation for code data that automatically helps developers prepare training data lacks study in this field. In this paper, we introduce a generic data augmentation framework, GenCode, to enhance the training of code understanding models. Simply speaking, GenCode follows a generation-and-selection paradigm to prepare useful training code data. Specifically, it employs code augmentation techniques to generate new code candidates first and then identifies important ones as the training data by influence scores. To evaluate the effectiveness of GenCode, we conduct experiments on four code understanding tasks (e.g., code clone detection) and three pre-trained code models (e.g., CodeT5) and two recent released code-specific LLMs (e.g., Qwen2.5-Coder). Compared to the state-of-the-art (SOTA) code augmentation method MixCode, GenCode produces pre-trained code models with 2.92% higher accuracy and 4.90% adversarial robustness on average. For code-specific LLMs, GenCode achieves an average improvement of 0.93% in accuracy and 0.98% in natural robustness.
- A survey of machine learning for big code and naturalness. ACM Computing Surveys (CSUR), 51(4):1–37.
- Self-supervised bug detection and repair. In Advances in Neural Information Processing Systems.
- Pavol Bielik and Martin Vechev. 2020. Adversarial robustness for code. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 896–907. PMLR.
- Self-supervised contrastive learning for code retrieval and summarization via semantic-preserving transformations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’21, pages 511–521, New York, NY, USA. Association for Computing Machinery.
- Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703.
- Detecting cryptography misuses with machine learning: Graph embeddings, transfer learning and data augmentation in source code related tasks. IEEE Transactions on Reliability.
- Bert: Pre-training of deep bidirectional transformers for language understanding.
- Hoppity: Learning graph transformations to detect and fix bugs in programs. In International Conference on Learning Representations.
- Mixcode: Enhancing code classification by mixup-based data augmentation. In SANER, pages 379–390.
- Boosting source code learning with data augmentation: An empirical study. arXiv preprint arXiv:2303.06808.
- On the effectiveness of graph data augmentation for source code learning. Knowledge-Based Systems, 285:111328.
- A survey of data augmentation approaches for NLP. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 968–988, Online. Association for Computational Linguistics.
- Codebert: a pre-trained model for programming and natural languages. pages 1536–1547.
- Fuzz testing based data augmentation to improve robustness of deep neural networks. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, ICSE ’20, page 1147–1158, New York, NY, USA. Association for Computing Machinery.
- Graphcodebert: Pre-training code representations with data flow. arXiv preprint arXiv:2009.08366.
- Re-factoring based program repair applied to programming assignments. In 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 388–398. IEEE.
- Diederik P Kingma and Jimmy Ba. 2014. Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Code smells and refactoring: A tertiary systematic review of challenges and observations. Journal of Systems and Software, 167:110610.
- Codexglue: a machine learning benchmark dataset for code understanding and generation. In Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS).
- Andrzej Maćkiewicz and Waldemar Ratajczak. 1993. Principal components analysis (pca). Computers & Geosciences, 19(3):303–342.
- Contrastive learning with keyword-based data augmentation for code search and code question answering. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3609–3619, Dubrovnik, Croatia. Association for Computational Linguistics.
- A search-based testing framework for deep neural networks of source code embedding. In 14th IEEE Conference on Software Testing, Verification and Validation (ICST), pages 36–46, Los Alamitos, CA, USA. IEEE Computer Society.
- Codenet: a large-scale ai for code dataset for learning a diversity of coding tasks.
- Correlation coefficients: appropriate use and interpretation. Anesthesia & analgesia, 126(5):1763–1768.
- On the importance of building high-quality training datasets for neural code search. In Proceedings of the 44th International Conference on Software Engineering, ICSE ’22, page 1609–1620, New York, NY, USA. Association for Computing Machinery.
- Towards a big data curated benchmark of inter-project code clones. In 2014 IEEE International Conference on Software Maintenance and Evolution, pages 476–480. IEEE.
- Bridging pre-trained models and downstream tasks for source code understanding. In Proceedings of the 44th International Conference on Software Engineering, pages 287–298, New York, NY, USA. Association for Computing Machinery.
- Detecting code clones with graph neural network and flow-augmented abstract syntax tree. In 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), pages 261–271. IEEE.
- CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8696–8708, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Reinforcing adversarial robustness using model confidence induced by adversarial training. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 5334–5342. PMLR.
- Unsupervised data augmentation for consistency training. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA. Curran Associates Inc.
- Exploitgen: Template-augmented exploit code generation based on codebert. Journal of Systems and Software, 197:111577.
- Natural attack for pre-trained models of code. In Proceedings of the 44th International Conference on Software Engineering, ICSE ’22, page 1482–1493, New York, NY, USA. Association for Computing Machinery.
- A survey of automated data augmentation algorithms for deep learning-based image classification tasks. Knowledge and Information Systems, 65(7):2805–2861.
- Michihiro Yasunaga and Percy Liang. 2020. Graph-based, self-supervised program repair from diagnostic feedback. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org.
- Adversarial examples for models of code. Proceedings of the ACM on Programming Languages, 4(OOPSLA):1–30.
- Data augmentation by program transformation. Journal of Systems and Software, 190:111304.
- mixup: beyond empirical risk minimization. In International Conference on Learning Representations (ICLR).
- Generating adversarial examples for holding robustness of source code processing models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 1169–1176.
- Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA. Association for Computing Machinery.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.