Look Before You Leap: Problem Elaboration Prompting Improves Mathematical Reasoning in Large Language Models
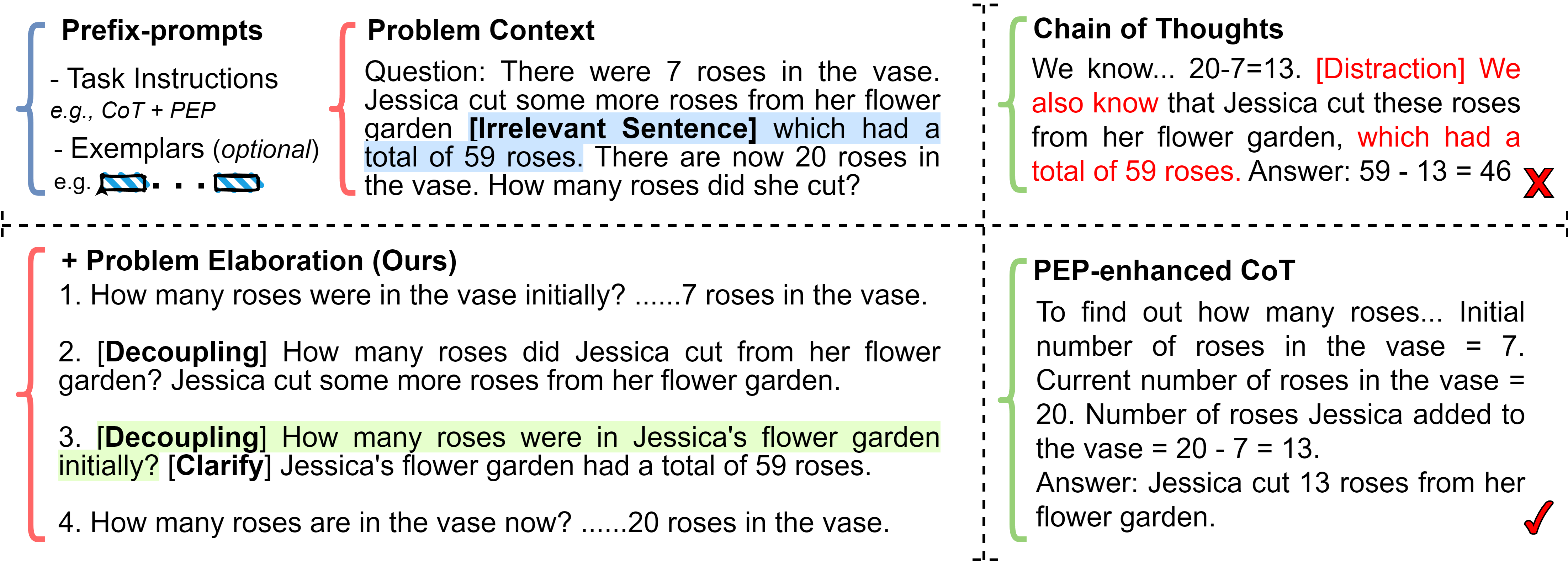
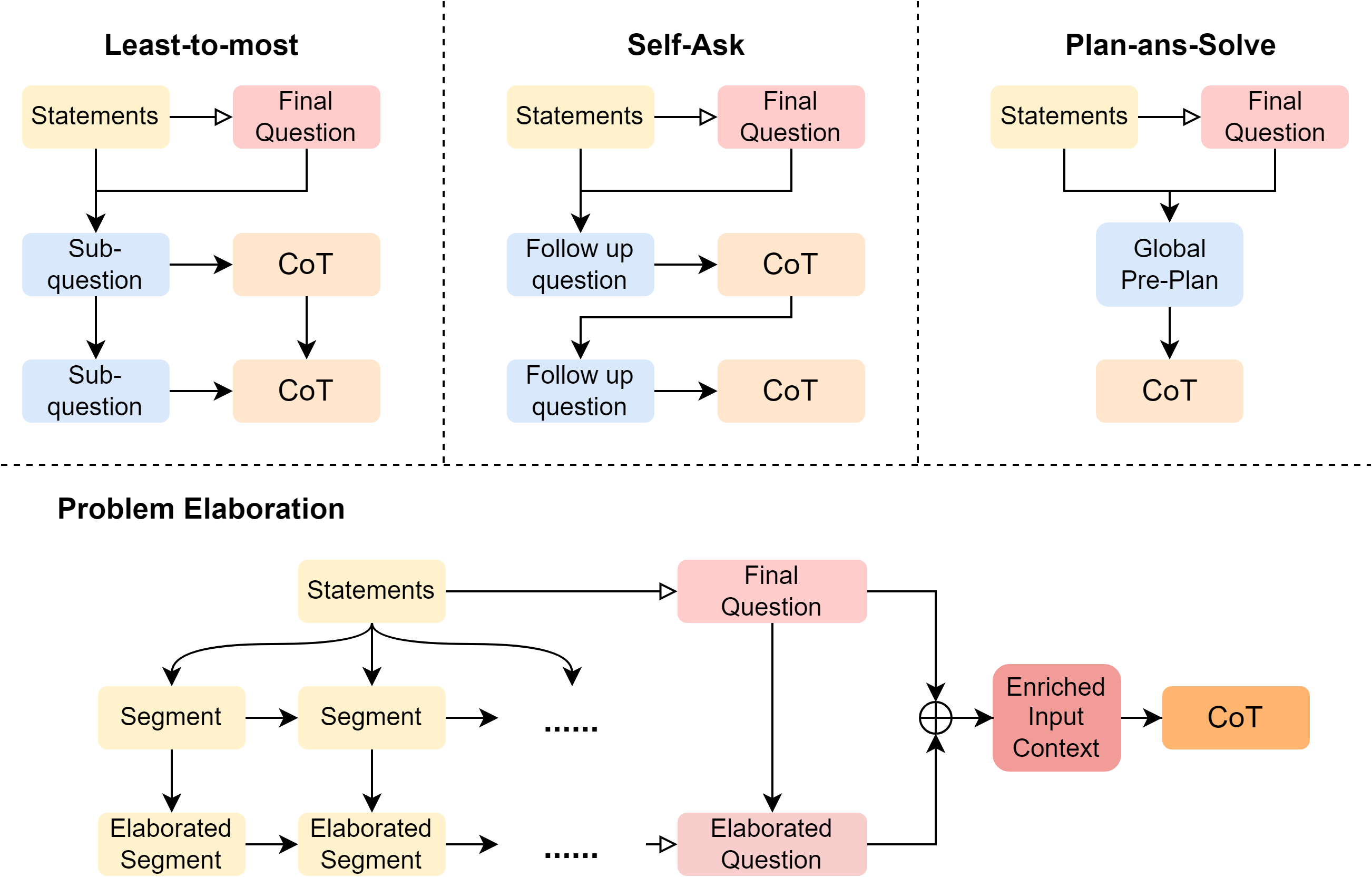
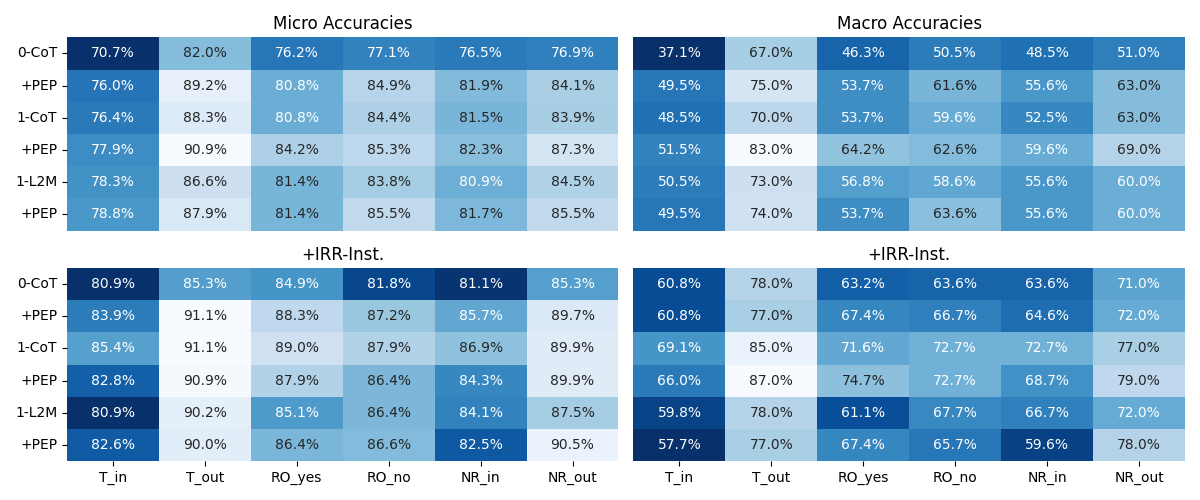
Abstract: LLMs still grapple with complex tasks like mathematical reasoning. Despite significant efforts invested in improving prefix prompts or reasoning process, the crucial role of problem context might have been neglected. Accurate recognition of inputs is fundamental for solving mathematical tasks, as ill-formed problems could potentially mislead LLM's reasoning. In this study, we propose a new approach named Problem Elaboration Prompting (PEP) to enhance the mathematical capacities of LLMs. Specifically, PEP decomposes and elucidates the problem context before reasoning, therefore enhancing the context modeling and parsing efficiency. Experiments across datasets and models demonstrate promising performances: (1) PEP demonstrates an overall enhancement in various mathematical tasks. For instance, with the GPT-3.5 model, PEP exhibits improvements of 9.93% and 8.80% on GSM8k through greedy decoding and self-consistency, respectively. (2) PEP can be easily implemented and integrated with other prompting methods. (3) PEP shows particular strength in handling distraction problems.
- Chatgpt is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models. ArXiv, abs/2303.16421.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Lang Cao. 2023. Enhancing reasoning capabilities of large language models: A graph-based verification approach. ArXiv.
- Chatgpt evaluation on sentence level relations: A focus on temporal, causal, and discourse relations. ArXiv, abs/2304.14827.
- Data distributional properties drive emergent in-context learning in transformers. Advances in Neural Information Processing Systems, 35:18878–18891.
- Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. ArXiv, abs/2211.12588.
- Palm: Scaling language modeling with pathways. ArXiv, abs/2204.02311.
- Scaling instruction-finetuned language models. ArXiv, abs/2210.11416.
- Training verifiers to solve math word problems. ArXiv, abs/2110.14168.
- Selection-inference: Exploiting large language models for interpretable logical reasoning. ArXiv, abs/2205.09712.
- Complexity-based prompting for multi-step reasoning. ArXiv, abs/2210.00720.
- Pal: Program-aided language models. ArXiv, abs/2211.10435.
- Measuring massive multitask language understanding. In International Conference on Learning Representations.
- Measuring mathematical problem solving with the math dataset. ArXiv, abs/2103.03874.
- Chain-of-symbol prompting elicits planning in large langauge models. ArXiv, abs/2305.10276.
- Maieutic prompting: Logically consistent reasoning with recursive explanations. In Conference on Empirical Methods in Natural Language Processing.
- Decomposed prompting: A modular approach for solving complex tasks. ArXiv, abs/2210.02406.
- Language models can solve computer tasks. ArXiv, abs/2303.17491.
- Large language models are zero-shot reasoners. Advances in Neural Information Processing Systems.
- Parsing algebraic word problems into equations. Transactions of the Association for Computational Linguistics, 3:585–597.
- Philipp E. Koralus and Vincent Wang-Ma’scianica. 2023. Humans in humans out: On gpt converging toward common sense in both success and failure. ArXiv, abs/2303.17276.
- Can language models learn from explanations in context? In Conference on Empirical Methods in Natural Language Processing.
- Solving quantitative reasoning problems with language models. In Advances in Neural Information Processing Systems.
- Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Annual Meeting of the Association for Computational Linguistics.
- Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. ArXiv, abs/2209.14610.
- Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098.
- Exploring automated distractor and feedback generation for math multiple-choice questions via in-context learning. ArXiv.
- Selfcheck: Using llms to zero-shot check their own step-by-step reasoning. ArXiv.
- Rethinking the role of demonstrations: What makes in-context learning work? In Conference on Empirical Methods in Natural Language Processing.
- OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- What in-context learning "learns" in-context: Disentangling task recognition and task learning. ArXiv, abs/2305.09731.
- Generative agents: Interactive simulacra of human behavior. ArXiv.
- Are nlp models really able to solve simple math word problems? In North American Chapter of the Association for Computational Linguistics.
- Unsupervised question decomposition for question answering. In Conference on Empirical Methods in Natural Language Processing.
- Measuring and narrowing the compositionality gap in language models. ArXiv, abs/2210.03350.
- Ben Prystawski and Noah D. Goodman. 2023. Why think step-by-step? reasoning emerges from the locality of experience. ArXiv, abs/2304.03843.
- Creator: Disentangling abstract and concrete reasonings of large language models through tool creation. ArXiv.
- Large language models are not zero-shot communicators. ArXiv, abs/2210.14986.
- Self-critiquing models for assisting human evaluators. ArXiv, abs/2206.05802.
- Synthetic prompting: Generating chain-of-thought demonstrations for large language models. ArXiv, abs/2302.00618.
- Large language models can be easily distracted by irrelevant context. ArXiv, abs/2302.00093.
- Reflexion: Language agents with verbal reinforcement learning.
- Follow the wisdom of the crowd: Effective text generation via minimum bayes risk decoding. ArXiv, abs/2211.07634.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Towards understanding chain-of-thought prompting: An empirical study of what matters. ArXiv, abs/2212.10001.
- Voyager: An open-ended embodied agent with large language models. ArXiv.
- Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. ArXiv, abs/2305.04091.
- Rationale-augmented ensembles in language models. ArXiv, abs/2207.00747.
- Self-consistency improves chain of thought reasoning in language models. ArXiv, abs/2203.11171.
- Albert Webson and Ellie Pavlick. 2022. Do prompt-based models really understand the meaning of their prompts? In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2300–2344.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
- Emergent abilities of large language models. Trans. Mach. Learn. Res., 2022.
- Chain-of-thought prompting elicits reasoning in large language models.
- An empirical study on challenging math problem solving with gpt-4. ArXiv.
- The rise and potential of large language model based agents: A survey.
- Tree of thoughts: Deliberate problem solving with large language models. ArXiv, abs/2305.10601.
- Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488.
- Opt: Open pre-trained transformer language models. ArXiv, abs/2205.01068.
- Automatic chain of thought prompting in large language models. ArXiv, abs/2210.03493.
- Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923.
- Progressive-hint prompting improves reasoning in large language models. ArXiv, abs/2304.09797.
- Analytical reasoning of text. In NAACL-HLT.
- Least-to-most prompting enables complex reasoning in large language models. ArXiv, abs/2205.10625.
- Large language models are human-level prompt engineers. ArXiv, abs/2211.01910.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

