Genie: Generative Interactive Environments
Abstract: We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
- The deepmind jax ecosystem, 2020. URL http://github. com/deepmind, 2010.
- Frozen in time: A joint video and image encoder for end-to-end retrieval. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 1708–1718, Los Alamitos, CA, USA, oct 2021. IEEE Computer Society. 10.1109/ICCV48922.2021.00175.
- Video pretraining (vpt): Learning to act by watching unlabeled online videos. Advances in Neural Information Processing Systems, 35:24639–24654, 2022.
- C. Bamford and S. M. Lucas. Neural game engine: Accurate learning ofgeneralizable forward models from pixels. In Conference on Games, 2020.
- Human-timescale adaptation in an open-ended task space. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 1887–1935. PMLR, 23–29 Jul 2023.
- Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023a.
- Align your latents: High-resolution video synthesis with latent diffusion models. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22563–22575, 2023b.
- Rt-1: Robotics transformer for real-world control at scale. In Robotics: Science and Systems, 2023.
- Video generation models as world simulators. 2024. URL https://openai.com/research/video-generation-models-as-world-simulators.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11315–11325, June 2022.
- Recurrent environment simulators. In International Conference on Learning Representations, 2017.
- Efficient video generation on complex datasets. CoRR, abs/1907.06571, 2019. URL http://arxiv.org/abs/1907.06571.
- J. Clune. Ai-gas: Ai-generating algorithms, an alternate paradigm for producing general artificial intelligence. arXiv preprint arXiv:1905.10985, 2019.
- Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, pages 2048–2056, 2020.
- Scaling vision transformers to 22 billion parameters. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 7480–7512. PMLR, 23–29 Jul 2023.
- An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=YicbFdNTTy.
- Imitating latent policies from observation. In International conference on machine learning, pages 1755–1763. PMLR, 2019.
- Neural scene representation and rendering. Science, 360(6394):1204–1210, 2018. 10.1126/science.aar6170.
- Structure and content-guided video synthesis with diffusion models. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
- Unsupervised learning for physical interaction through video prediction. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 64–72, Red Hook, NY, USA, 2016. Curran Associates Inc. ISBN 9781510838819.
- Maskvit: Masked visual pre-training for video prediction. In The Eleventh International Conference on Learning Representations, 2023.
- D. Ha and J. Schmidhuber. Recurrent world models facilitate policy evolution. In Proceedings of the 32Nd International Conference on Neural Information Processing Systems, NeurIPS’18, pages 2455–2467, 2018.
- Dream to control: Learning behaviors by latent imagination. In International Conference on Learning Representations, 2020.
- Mastering atari with discrete world models. In International Conference on Learning Representations, 2021.
- Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 10.1109/CVPR.2016.90.
- Query-key normalization for transformers. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4246–4253, Online, Nov. 2020. Association for Computational Linguistics. 10.18653/v1/2020.findings-emnlp.379.
- Imagen video: High definition video generation with diffusion models, 2022a.
- Video diffusion models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 8633–8646. Curran Associates, Inc., 2022b.
- Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
- Cogvideo: Large-scale pretraining for text-to-video generation via transformers. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=rB6TpjAuSRy.
- Diffusion models for video prediction and infilling. Transactions on Machine Learning Research, 2022. ISSN 2835-8856.
- Gaia-1: A generative world model for autonomous driving, 2023.
- Layered controllable video generation. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVI, page 546–564, Berlin, Heidelberg, 2022. Springer-Verlag. ISBN 978-3-031-19786-4.
- A domain-specific supercomputer for training deep neural networks. Communications of the ACM, 63(7):67–78, 2020.
- Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. arXiv preprint arXiv:1806.10293, 2018.
- Video pixel networks. In D. Precup and Y. W. Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1771–1779. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/kalchbrenner17a.html.
- Recurrent experience replay in distributed reinforcement learning. In International conference on learning representations, 2018.
- Learning to simulate dynamic environments with gamegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Drivegan: Towards a controllable high-quality neural simulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5820–5829, June 2021.
- Ccvs: Context-aware controllable video synthesis. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 14042–14055. Curran Associates, Inc., 2021.
- Deep predictive coding networks for video prediction and unsupervised learning. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=B1ewdt9xe.
- Transformation-based adversarial video prediction on large-scale data. CoRR, abs/2003.04035, 2020.
- Playable video generation. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 10061–10070. Computer Vision Foundation / IEEE, 2021.
- Playable environments: Video manipulation in space and time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- Transformers are sample-efficient world models. In The Eleventh International Conference on Learning Representations, 2023.
- Action-conditioned benchmarking of robotic video prediction models: a comparative study. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 8316–8322, 2020. 10.1109/ICRA40945.2020.9196839.
- Action-conditional video prediction using deep networks in atari games. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, NIPS’15, page 2863–2871, Cambridge, MA, USA, 2015. MIT Press.
- Open-ended learning leads to generally capable agents. CoRR, abs/2107.12808, 2021.
- Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Iso-dream: Isolating and leveraging noncontrollable visual dynamics in world models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 23178–23191. Curran Associates, Inc., 2022.
- Improving language understanding by generative pre-training. 2018.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
- Zero-shot text-to-image generation. In M. Meila and T. Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8821–8831. PMLR, 18–24 Jul 2021.
- Hierarchical text-conditional image generation with clip latents, 2022.
- A generalist agent. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. Featured Certification, Outstanding Certification.
- S. Risi and J. Togelius. Increasing generality in machine learning through procedural content generation. Nature Machine Intelligence, 2, 08 2020a. 10.1038/s42256-020-0208-z.
- S. Risi and J. Togelius. Procedural content generation: From automatically generating game levels to increasing generality in machine learning. Nature, 2020b.
- Transformer-based world models are happy with 100k interactions. In The Eleventh International Conference on Learning Representations, 2023.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022.
- Learning what you can do before doing anything. In International Conference on Learning Representations, 2019.
- Photorealistic text-to-image diffusion models with deep language understanding. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors, Advances in Neural Information Processing Systems, 2022.
- D. Schmidt and M. Jiang. Learning to act without actions. In The Twelfth International Conference on Learning Representations, 2024.
- Megatron-lm: Training multi-billion parameter language models using model parallelism. CoRR, abs/1909.08053, 2019. URL http://arxiv.org/abs/1909.08053.
- Make-a-video: Text-to-video generation without text-video data. In The Eleventh International Conference on Learning Representations, 2023.
- Prompt-guided level generation. In Proceedings of the Companion Conference on Genetic and Evolutionary Computation, pages 179–182, 2023.
- Procedural content generation via machine learning (PCGML). IEEE Trans. Games, 10(3):257–270, 2018.
- Level generation through large language models. In Proceedings of the 18th International Conference on the Foundations of Digital Games, pages 1–8, 2023.
- Behavioral cloning from observation. arXiv preprint arXiv:1805.01954, 2018.
- FVD: A new metric for video generation, 2019.
- Imagen 2. URL https://deepmind.google/technologies/imagen-2/.
- Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6309–6318, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008, 2017.
- Phenaki: Variable length video generation from open domain textual descriptions. In International Conference on Learning Representations, 2023.
- Predicting video with VQVAE, 2021.
- Internvid: A large-scale video-text dataset for multimodal understanding and generation, 2023.
- From word models to world models: Translating from natural language to the probabilistic language of thought, 2023.
- Nüwa: Visual synthesis pre-training for neural visual world creation. In European conference on computer vision, pages 720–736. Springer, 2022.
- Spatial-temporal transformer networks for traffic flow forecasting. arXiv preprint arXiv:2001.02908, 2020.
- Videogpt: Video generation using vq-vae and transformers, 2021.
- Temporally consistent transformers for video generation. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 39062–39098. PMLR, 23–29 Jul 2023.
- Learning interactive real-world simulators. arXiv preprint arXiv:2310.06114, 2023.
- Become a proficient player with limited data through watching pure videos. In The Eleventh International Conference on Learning Representations, 2022.
- Magvit: Masked generative video transformer. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10459–10469, Los Alamitos, CA, USA, jun 2023. IEEE Computer Society. 10.1109/CVPR52729.2023.01008.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Genie, a powerful AI that can turn a single prompt—like a sentence, a picture, a photo, or even a quick sketch—into a playable, interactive world. Think of it like drawing a scene and then being able to jump into it and control what happens, frame by frame. Genie learns how to do this by watching lots of videos from the internet, without needing any labels or instructions about what actions people took in those videos.
Goals and Questions
The researchers wanted to answer three simple questions:
- Can we build an AI that creates playable worlds from just videos, without knowing the actual controller inputs used in those videos?
- Can users control these worlds with a small set of simple “buttons” (actions) that the AI learns on its own?
- Can the same learned actions help train future game-playing robots or agents by imitating what they see in new videos?
How Genie Works
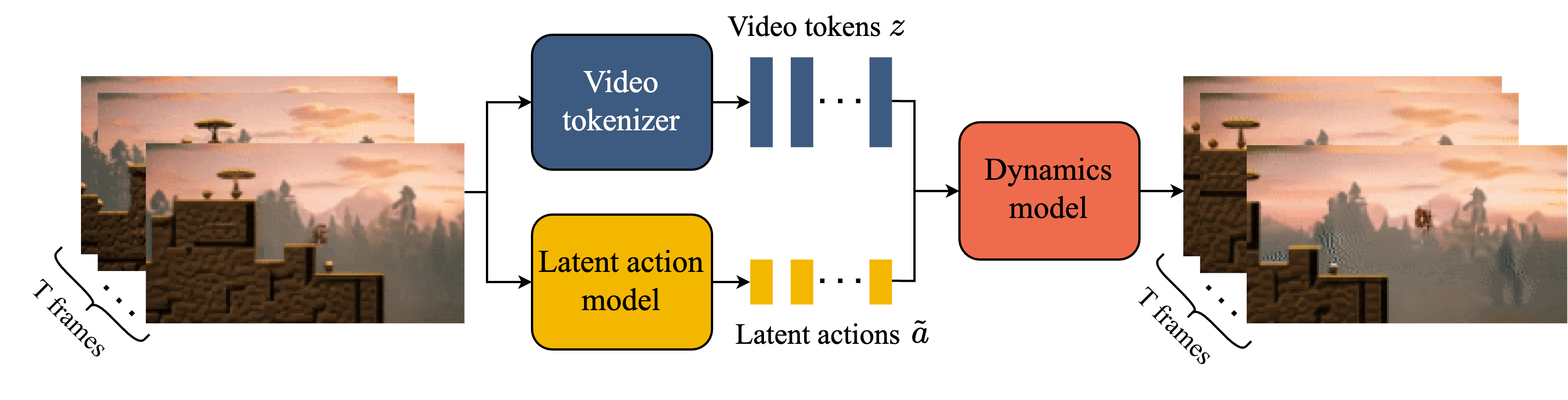
At a high level, Genie has three main parts that work together. You can imagine a video as a flipbook: each page is a frame. Genie looks at frames and predicts the next one based on what “button” you press.
Here’s the setup, explained with everyday analogies:
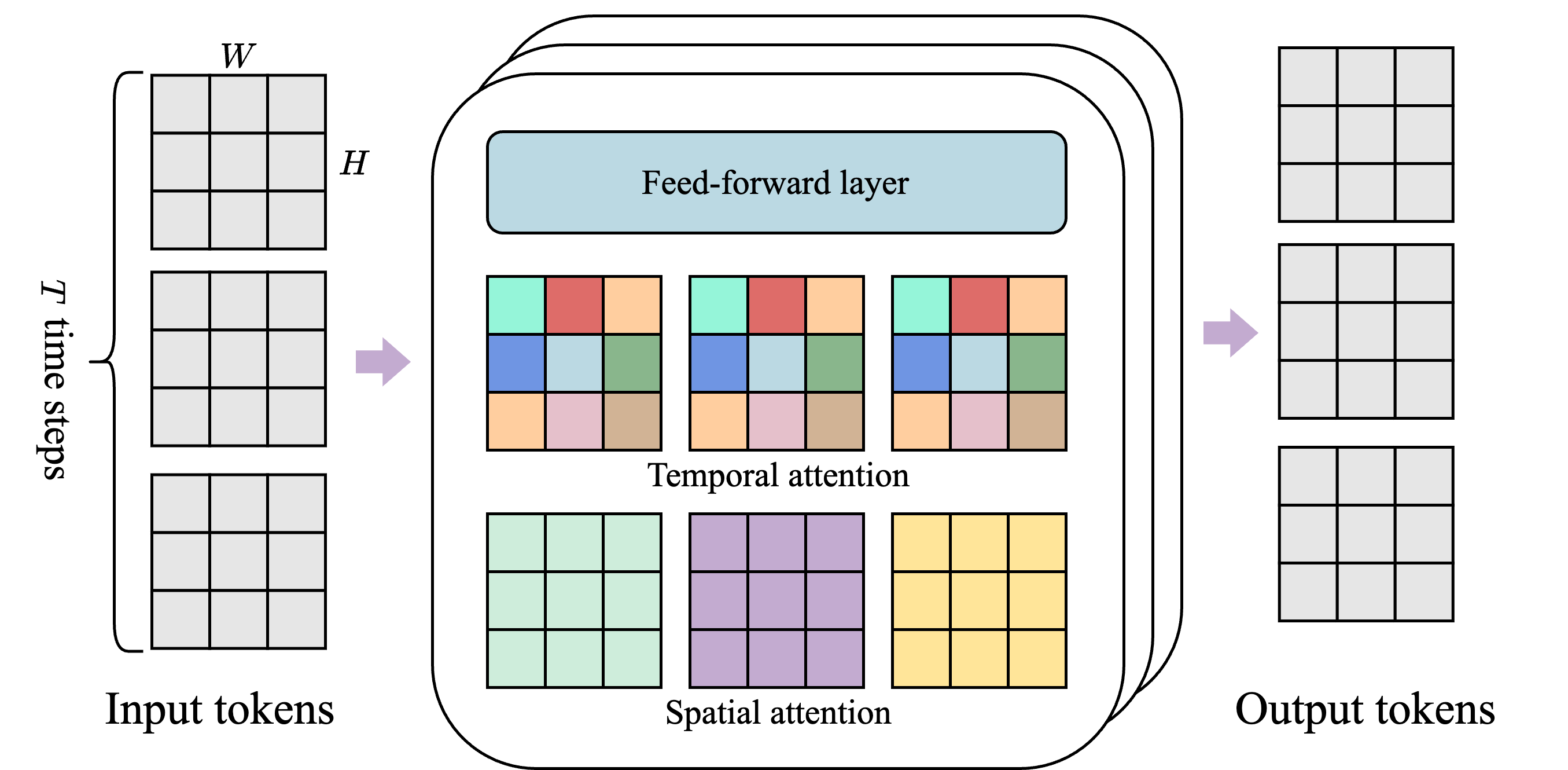
- Video Tokenizer: This turns each video frame into compact “tokens,” a bit like breaking a picture into LEGO pieces so it’s easier to handle. Genie uses a special transformer (a type of AI model) that looks both within a single frame (spatial) and across time (temporal). That’s like paying attention to what’s happening in one picture and how it changes across the flipbook.
- Latent Action Model (LAM): Genie learns a small set of actions—like controller buttons—only from watching videos. No one tells it “this was a jump” or “this was move right.” Instead, it figures out the most useful changes between frames and organizes them into a tiny action dictionary (in the paper, there are 8 actions). This is like learning what each button does by watching gameplay and noticing how the screen changes when certain movements happen.
- Dynamics Model: This predicts the next frame given the previous frames and the chosen action. Imagine a smart storyteller who looks at what’s already happened and what button you pressed, then draws the next picture in the flipbook. Genie uses a method called MaskGIT, which is like filling in a puzzle piece by piece until the frame looks right.
Technically, all three parts use a “spatiotemporal transformer,” which keeps memory use low by focusing attention inside each frame (space) and across frames (time) separately. This makes it faster and more scalable for long videos.
Training data and scale:
- Genie was trained on about 30,000 hours of 2D platformer game videos from the internet.
- The team also trained a smaller version on robot videos (no action labels used).
- The final Genie model has around 11 billion parameters, which makes it a “foundation world model”—a big, general system that can be adapted to many situations.
Main Findings
The researchers highlight several exciting results. Here is a short list to make them easy to follow:
- Playable worlds from diverse prompts: Genie can take text-generated images, hand-drawn sketches, or even real photos, and turn them into controllable, game-like scenes. Users can press one of the learned action buttons to move characters or objects, frame by frame.
- Consistent actions: Even though the actions were learned without labels, each action tends to mean something similar across different inputs—for example, “move right” or “jump” shows up consistently.
- Generalization: Genie works even when the input images look very different from the training videos (this is called “out-of-distribution”). It still produces believable gameplay-like motions.
- Understanding scenes: Genie can mimic parallax—the effect where foreground moves faster than background when you pan across a scene—showing it learned some 3D-like understanding from 2D videos.
- Robotics: The robot-trained Genie version learns consistent manipulator actions and even simulates object properties (like a bag of chips deforming when moved). This is impressive because it learned only from video, not from action labels.
- Scaling helps: As the model gets bigger and the training batches get larger, the results improve smoothly. This is a sign that Genie benefits from more data and compute.
- Training agents: Genie’s learned actions can be used to imitate behaviors from new, unlabeled videos in unseen environments. With a small amount of extra data to map Genie’s “buttons” to real controls, an agent can reach performance close to an expert that had full labeled data.
Why It Matters
Genie shows a new way to create interactive experiences:
- Creativity: Kids, artists, and game designers can sketch or imagine worlds and instantly make them playable.
- Data efficiency: It learns actions from unlabeled videos, which are everywhere online, making it easier and cheaper than collecting special action-labeled datasets.
- Building smarter agents: It opens a path to train general-purpose game-playing agents or robots by “watching” videos and learning what to do, rather than needing detailed instructions.
- Foundation for future systems: Because Genie is large and general, it can be a base for many applications in simulation, training, and entertainment.
Limitations and Future Impact
The paper is honest about current limits:
- Speed: Genie currently runs around 1 frame per second, which is too slow for smooth, real-time play.
- Memory for long stories: It keeps a short history (about 16 frames), so it can sometimes lose consistency over long sequences.
- Realism: Like other generative models, it can sometimes “hallucinate” odd or unrealistic frames.
Despite these limits, Genie could:
- Help democratize game creation—more people can make interactive worlds quickly.
- Provide vast, varied training environments for AI agents, potentially leading to more capable, general AI.
- Inspire new research combining video learning, control, and simulation to bridge the gap between watching and doing.
In short, Genie is a big step toward AI that can watch videos, learn how actions change the world, and then let us play inside the worlds it imagines.
Collections
Sign up for free to add this paper to one or more collections.

