Toward a Team of AI-made Scientists for Scientific Discovery from Gene Expression Data
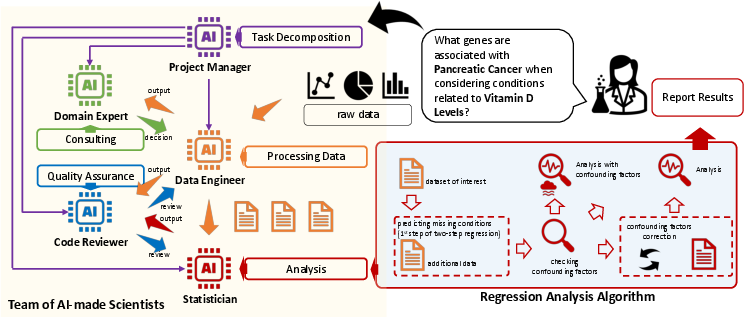
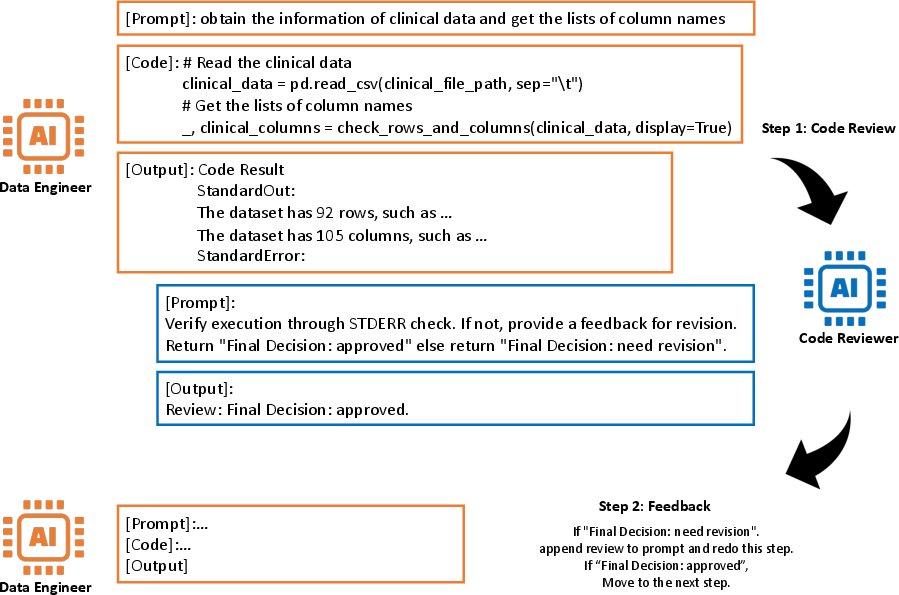
Abstract: Machine learning has emerged as a powerful tool for scientific discovery, enabling researchers to extract meaningful insights from complex datasets. For instance, it has facilitated the identification of disease-predictive genes from gene expression data, significantly advancing healthcare. However, the traditional process for analyzing such datasets demands substantial human effort and expertise for the data selection, processing, and analysis. To address this challenge, we introduce a novel framework, a Team of AI-made Scientists (TAIS), designed to streamline the scientific discovery pipeline. TAIS comprises simulated roles, including a project manager, data engineer, and domain expert, each represented by a LLM. These roles collaborate to replicate the tasks typically performed by data scientists, with a specific focus on identifying disease-predictive genes. Furthermore, we have curated a benchmark dataset to assess TAIS's effectiveness in gene identification, demonstrating our system's potential to significantly enhance the efficiency and scope of scientific exploration. Our findings represent a solid step towards automating scientific discovery through LLMs.
- H. Abusamra. A comparative study of feature selection and classification methods for gene expression data of glioma. Procedia Computer Science, 23:5–14, 2013.
- A. A. Awomoyi. The human solute carrier family 11 member 1 protein (slc11a1): linking infections, autoimmunity and cancer? FEMS Immunology & Medical Microbiology, 49(3):324–329, 2007.
- Vitamin d: modulator of the immune system. Current opinion in pharmacology, 10(4):482–496, 2010.
- Chemcrow: Augmenting large-language models with chemistry tools. arXiv preprint arXiv: 2304.05376, 2023.
- Mammaprint™: a comprehensive review. Future oncology, 15(2):207–224, 2019.
- Gene: a gene-centered information resource at ncbi. Nucleic acids research, 43(D1):D36–D42, 2015.
- Confounding factors in the transcriptome analysis of an in-vivo exposure experiment. PLoS One, 11(1):e0145252, 2016.
- Personalized medicine: progress and promise. Annual review of genomics and human genetics, 12:217–244, 2011.
- E. Clough and T. Barrett. The gene expression omnibus database. Methods in Molecular Biology, 1418:93–110, 2016. doi: 10.1007/978-1-4939-3578-9˙5.
- Modulation of inflammatory and immune responses by vitamin d. Journal of autoimmunity, 85:78–97, 2017.
- Self-collaboration code generation via chatgpt. arXiv preprint arXiv: 2304.07590, 2023.
- Improving factuality and reasoning in language models through multiagent debate. arXiv preprint arXiv: 2305.14325, 2023.
- Towards revealing the mystery behind chain of thought: A theoretical perspective. NEURIPS, 2023.
- D. Ghosh and A. M. Chinnaiyan. Classification and selection of biomarkers in genomic data using lasso. Journal of Biomedicine and Biotechnology, 2005(2):147, 2005.
- Visualizing and interpreting cancer genomics data via the xena platform. Nature biotechnology, 38(6):675–678, 2020.
- What can large language models do in chemistry? a comprehensive benchmark on eight tasks. arXiv preprint arXiv:2305.18365, 2023.
- The path to personalized medicine. New England Journal of Medicine, 363(4):301–304, 2010.
- Reasoning with language model is planning with world model. Conference on Empirical Methods in Natural Language Processing, 2023. doi: 10.48550/arXiv.2305.14992.
- Metagpt: Meta programming for a multi-agent collaborative framework. arXiv preprint arXiv: 2308.00352, 2023.
- From big data to better patient outcomes. Clinical Chemistry and Laboratory Medicine (CCLM), 61(4):580–586, 2023. doi: 10.1515/cclm-2022-1096. URL https://doi.org/10.1515/cclm-2022-1096.
- I. M. Johnstone. On the distribution of the largest eigenvalue in principal components analysis. The Annals of statistics, 29(2):295–327, 2001.
- M. M. R. Khondoker. Statistical methods for pre-processing microarray gene expression data. PhD thesis, University of Edinburgh, 2006.
- Race, gene expression signatures, and clinical outcomes of patients with high-risk early breast cancer. JAMA Network Open, 6(12):e2349646–e2349646, 2023.
- Tackling the widespread and critical impact of batch effects in high-throughput data. Nature Reviews Genetics, 11(10):733–739, 2010.
- Theory of mind for multi-agent collaboration via large language models. arXiv preprint arXiv:2310.10701, 2023.
- Fast linear mixed models for genome-wide association studies. Nature methods, 8(10):833–835, 2011.
- Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation, 2023.
- Large language models generate functional protein sequences across diverse families. Nature Biotechnology, pages 1–8, 2023.
- Individualization of therapy using mammaprint® ì: from development to the mindact trial. Cancer genomics & proteomics, 4(3):147–155, 2007.
- Skeleton-of-thought: Large language models can do parallel decoding. arXiv preprint arXiv:2307.15337, 2023.
- OpenAI. Gpt-4 technical report. PREPRINT, 2023.
- Communicative agents for software development. arXiv preprint arXiv: 2307.07924, 2023.
- Novel precision medicine approaches and treatment strategies in hematological malignancies. Journal of Internal Medicine, 294(4):413–436, 2023.
- Conceptual framework for autonomous cognitive entities. arXiv preprint arXiv: 2310.06775, 2023.
- Large language models encode clinical knowledge. Nature, 620(7972):172–180, 2023.
- Cognitive architectures for language agents. arXiv preprint arXiv: 2309.02427, 2023.
- Y. Talebirad and A. Nadiri. Multi-agent collaboration: Harnessing the power of intelligent llm agents. arXiv preprint arXiv: 2306.03314, 2023.
- R. Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology, 58(1):267–288, 1996.
- The cancer genome atlas (tcga): an immeasurable source of knowledge. Contemporary Oncology (Poznan), 19(1A):A68–77, 2015. doi: 10.5114/wo.2014.47136.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv: 2307.09288, 2023b.
- Gene expression profiling predicts clinical outcome of breast cancer. nature, 415(6871):530–536, 2002.
- Towards understanding chain-of-thought prompting: An empirical study of what matters. arXiv preprint arXiv:2212.10001, 2022a.
- Variable selection in heterogeneous datasets: A truncated-rank sparse linear mixed model with applications to genome-wide association studies. In 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 431–438. IEEE, 2017.
- Trade-offs of linear mixed models in genome-wide association studies. Journal of Computational Biology, 29(3):233–242, 2022b.
- Adapting llm agents through communication. arXiv preprint arXiv: 2310.01444, 2023a.
- A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432, 2023b.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022c.
- Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration. arXiv preprint arXiv:2307.05300, 2023c.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Genome-wide association analysis by lasso penalized logistic regression. Bioinformatics, 25(6):714–721, 2009.
- Auto-gpt for online decision making: Benchmarks and additional opinions. arXiv preprint arXiv: 2306.02224, 2023a.
- An overview of the use of precision population medicine in cancer care: First of a series. Cureus, 15(4), 2023b.
- Large language models in health care: Development, applications, and challenges. Health Care Science, 2(4):255–263, 2023c.
- React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Socs1 and its potential clinical role in tumor. Pathology & Oncology Research, 25(4):1295–1301, 2019.
- A unified mixed-model method for association mapping that accounts for multiple levels of relatedness. Nature genetics, 38(2):203–208, 2006.
- Synapse: Leveraging few-shot exemplars for human-level computer control. arXiv preprint arXiv:2306.07863, 2023.
- How far are large language models from agents with theory-of-mind? arXiv preprint arXiv: 2310.03051, 2023a.
- Agents: An open-source framework for autonomous language agents. arXiv preprint arXiv:2309.07870, 2023b.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.