Thompson Sampling in Partially Observable Contextual Bandits
Abstract: Contextual bandits constitute a classical framework for decision-making under uncertainty. In this setting, the goal is to learn the arms of highest reward subject to contextual information, while the unknown reward parameters of each arm need to be learned by experimenting that specific arm. Accordingly, a fundamental problem is that of balancing exploration (i.e., pulling different arms to learn their parameters), versus exploitation (i.e., pulling the best arms to gain reward). To study this problem, the existing literature mostly considers perfectly observed contexts. However, the setting of partial context observations remains unexplored to date, despite being theoretically more general and practically more versatile. We study bandit policies for learning to select optimal arms based on the data of observations, which are noisy linear functions of the unobserved context vectors. Our theoretical analysis shows that the Thompson sampling policy successfully balances exploration and exploitation. Specifically, we establish the followings: (i) regret bounds that grow poly-logarithmically with time, (ii) square-root consistency of parameter estimation, and (iii) scaling of the regret with other quantities including dimensions and number of arms. Extensive numerical experiments with both real and synthetic data are presented as well, corroborating the efficacy of Thompson sampling. To establish the results, we introduce novel martingale techniques and concentration inequalities to address partially observed dependent random variables generated from unspecified distributions, and also leverage problem-dependent information to sharpen probabilistic bounds for time-varying suboptimality gaps. These techniques pave the road towards studying other decision-making problems with contextual information as well as partial observations.
- Improved algorithms for linear stochastic bandits. Advances in neural information processing systems, 24:2312–2320, 2011.
- M. Abeille and A. Lazaric. Linear thompson sampling revisited. In Artificial Intelligence and Statistics, pages 176–184. PMLR, 2017.
- M. Abramowitz and I. A. Stegun. Handbook of mathematical functions with formulas, graphs, and mathematical tables, volume 55. US Government printing office, 1964.
- Taming the monster: A fast and simple algorithm for contextual bandits. In International Conference on Machine Learning, pages 1638–1646. PMLR, 2014.
- S. Agrawal and N. Goyal. Thompson sampling for contextual bandits with linear payoffs. In International Conference on Machine Learning, pages 127–135. PMLR, 2013.
- K. J. Åström. Optimal control of markov processes with incomplete state information. Journal of mathematical analysis and applications, 10(1):174–205, 1965.
- P. Auer. Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3(Nov):397–422, 2002.
- K. Azuma. Weighted sums of certain dependent random variables. Tohoku Mathematical Journal, Second Series, 19(3):357–367, 1967.
- H. Bastani and M. Bayati. Online decision making with high-dimensional covariates. Operations Research, 68(1):276–294, 2020.
- Mostly exploration-free algorithms for contextual bandits. Management Science, 67(3):1329–1349, 2021.
- A. Bensoussan. Stochastic control of partially observable systems. Cambridge University Press, 2004.
- A contextual bandit bake-off. The Journal of Machine Learning Research, 22(1):5928–5976, 2021.
- Thompson sampling for high-dimensional sparse linear contextual bandits. In International Conference on Machine Learning, pages 3979–4008. PMLR, 2023.
- O. Chapelle and L. Li. An empirical evaluation of thompson sampling. Advances in neural information processing systems, 24:2249–2257, 2011.
- Stochastic linear optimization under bandit feedback. 2008.
- J. L. Doob. Stochastic processes, volume 10. New York Wiley, 1953.
- E. R. Dougherty. Digital image processing methods. CRC Press, 2020.
- Pg-ts: Improved thompson sampling for logistic contextual bandits. Advances in neural information processing systems, 31, 2018.
- Finite time identification in unstable linear systems. Automatica, 96:342–353, 2018.
- Adapting to misspecification in contextual bandits. Advances in Neural Information Processing Systems, 33:11478–11489, 2020.
- A. Ghosh and A. Sankararaman. Breaking the T𝑇\sqrt{T}square-root start_ARG italic_T end_ARG barrier: Instance-independent logarithmic regret in stochastic contextual linear bandits. In International Conference on Machine Learning, pages 7531–7549. PMLR, 2022.
- A. Goldenshluger and A. Zeevi. A linear response bandit problem. Stochastic Systems, 3(1):230–261, 2013.
- Guidelines for reinforcement learning in healthcare. Nature medicine, 25(1):16–18, 2019.
- M. Guan and H. Jiang. Nonparametric stochastic contextual bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- N. Hamidi and M. Bayati. On worst-case regret of linear thompson sampling. arXiv preprint arXiv:2006.06790, 2020.
- D. Harville. Extension of the gauss-markov theorem to include the estimation of random effects. The Annals of Statistics, 4(2):384–395, 1976.
- S. T. Jose and S. Moothedath. Thompson sampling for stochastic bandits with noisy contexts: An information-theoretic regret analysis. arXiv preprint arXiv:2401.11565, 2024.
- Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1-2):99–134, 1998.
- A lidar-based decision-making method for road boundary detection using multiple kalman filters. IEEE Transactions on Industrial Electronics, 59(11):4360–4368, 2012.
- Thompson sampling for partially observable linear-quadratic control. In 2023 American Control Conference (ACC), pages 4561–4568. IEEE, 2023.
- Contextual linear bandits under noisy features: Towards bayesian oracles. In International Conference on Artificial Intelligence and Statistics, pages 1624–1645. PMLR, 2023.
- Information directed sampling for linear partial monitoring. In Conference on Learning Theory, pages 2328–2369. PMLR, 2020.
- V. Krishnamurthy and B. Wahlberg. Partially observed markov decision process multiarmed bandits—structural results. Mathematics of Operations Research, 34(2):287–302, 2009.
- T. Lattimore. Minimax regret for partial monitoring: Infinite outcomes and rustichini’s regret. In Conference on Learning Theory, pages 1547–1575. PMLR, 2022.
- T. Lattimore and C. Szepesvári. Bandit algorithms. Cambridge University Press, 2020.
- Kalman filter decision systems for debris flow hazard assessment. Natural hazards, 60(3):1255–1266, 2012.
- I. Nagrath. Control systems engineering. New Age International, 2006.
- H. Park and M. K. S. Faradonbeh. Analysis of thompson sampling for partially observable contextual multi-armed bandits. IEEE Control Systems Letters, 6:2150–2155, 2021.
- H. Park and M. K. S. Faradonbeh. Efficient algorithms for learning to control bandits with unobserved contexts. IFAC-PapersOnLine, 55(12):383–388, 2022a.
- H. Park and M. K. S. Faradonbeh. Worst-case performance of greedy policies in bandits with imperfect context observations. In 2022 IEEE 61st Conference on Decision and Control (CDC), pages 1374–1379. IEEE, 2022b.
- Greedy algorithm almost dominates in smoothed contextual bandits. SIAM Journal on Computing, 52(2):487–524, 2023.
- G. K. Robinson. That blup is a good thing: the estimation of random effects. Statistical science, pages 15–32, 1991.
- W. Rudin et al. Principles of mathematical analysis, volume 3. McGraw-hill New York, 1976.
- D. Russo and B. Van Roy. Learning to optimize via posterior sampling. Mathematics of Operations Research, 39(4):1221–1243, 2014.
- Best-of-both-worlds algorithms for partial monitoring. In International Conference on Algorithmic Learning Theory, pages 1484–1515. PMLR, 2023.
- N. Wanigasekara and C. Yu. Nonparametric contextual bandits in metric spaces with unknown metric. Advances in Neural Information Processing Systems, 32, 2019.
- Lasso guarantees for β𝛽\betaitalic_β-mixing heavy-tailed time series. Annals of statistics, 48(2), 2020.
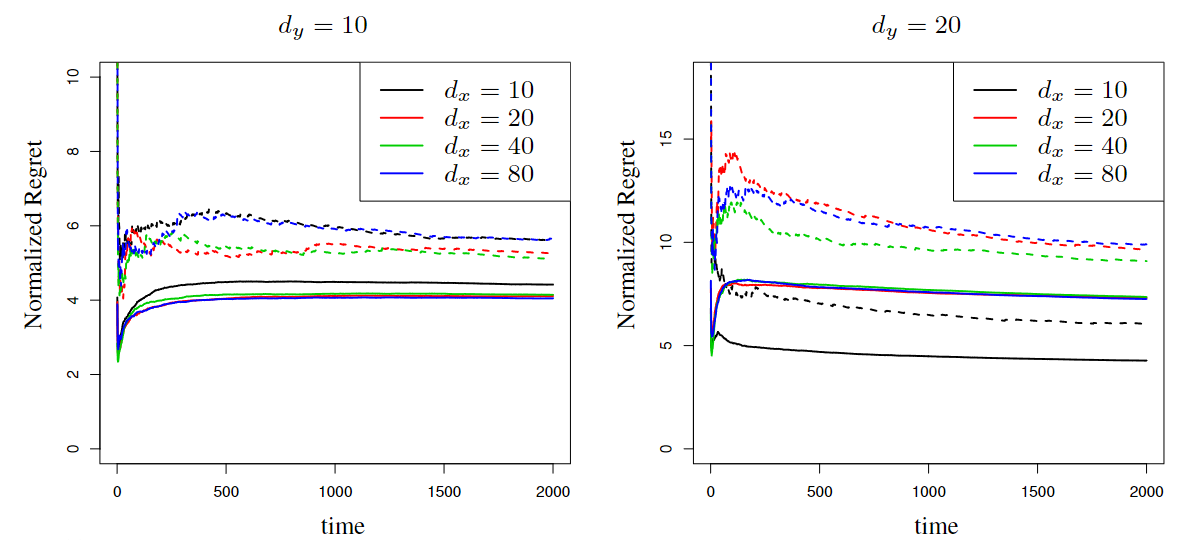
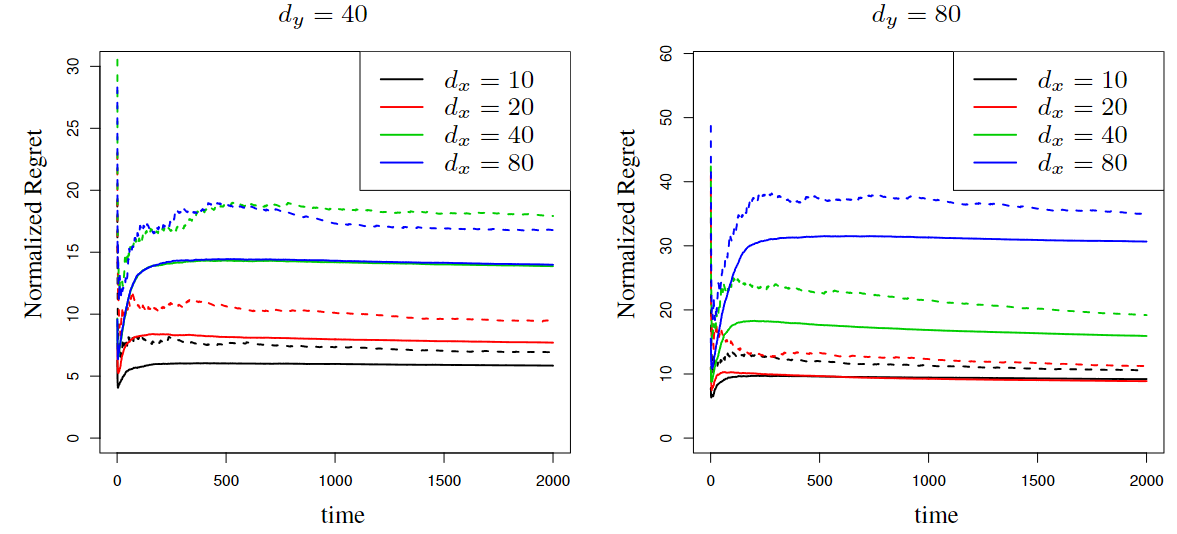
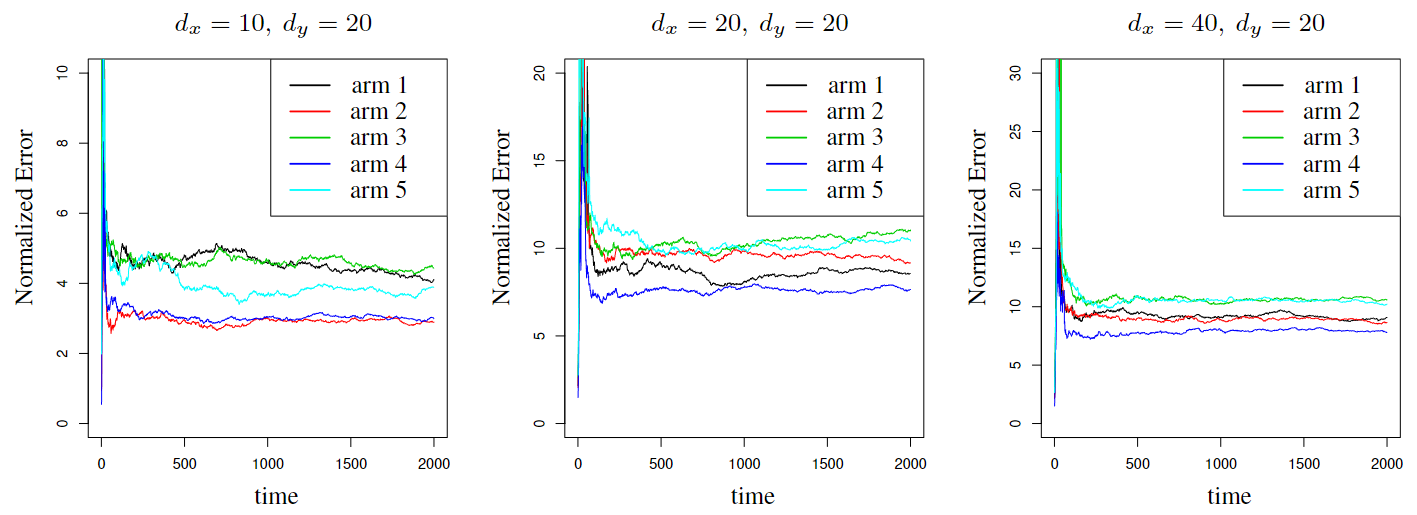
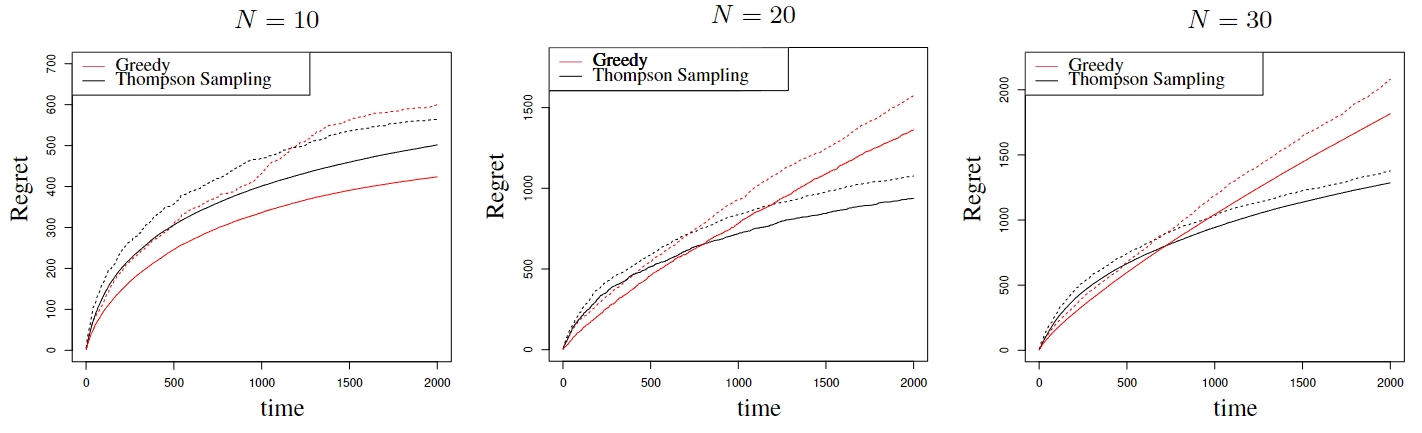
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.