Enhancing ID and Text Fusion via Alternative Training in Session-based Recommendation
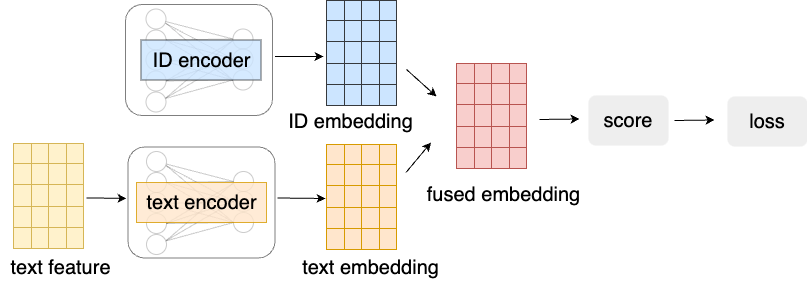
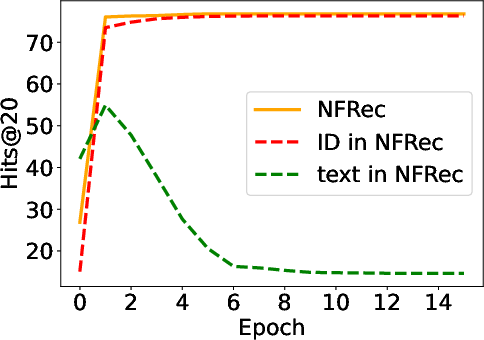
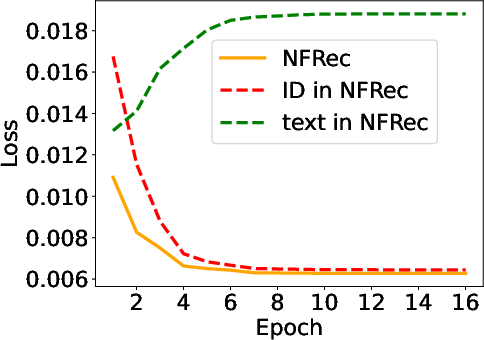
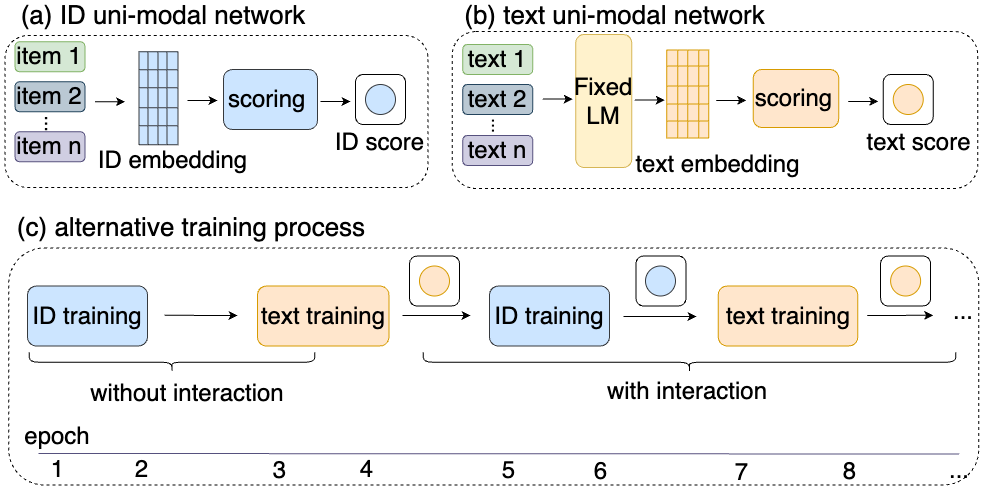
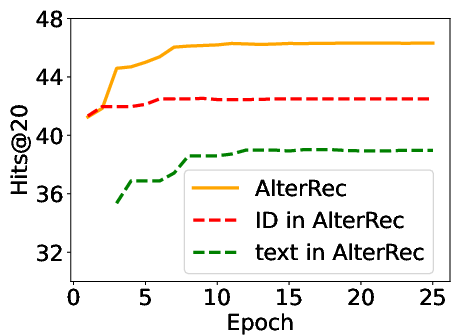
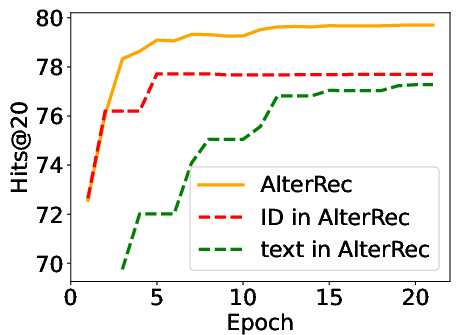
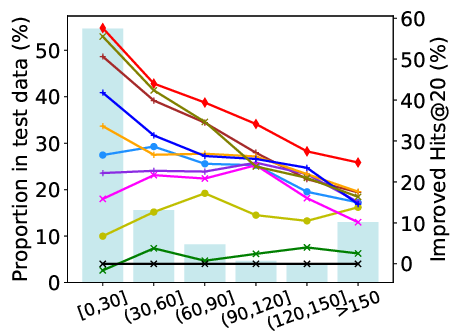
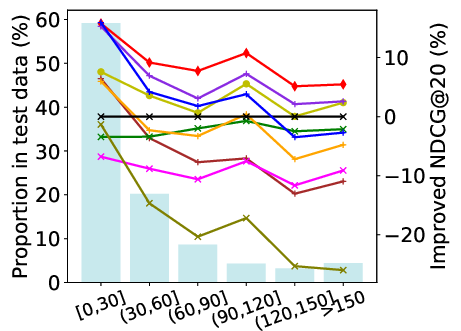
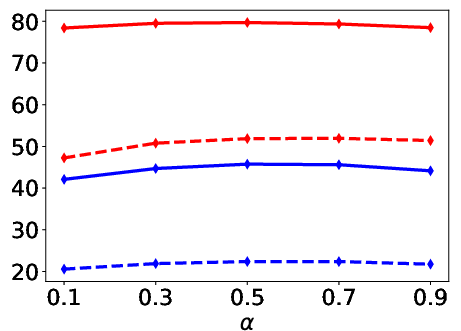
Abstract: Session-based recommendation has gained increasing attention in recent years, with its aim to offer tailored suggestions based on users' historical behaviors within sessions. To advance this field, a variety of methods have been developed, with ID-based approaches typically demonstrating promising performance. However, these methods often face challenges with long-tail items and overlook other rich forms of information, notably valuable textual semantic information. To integrate text information, various methods have been introduced, mostly following a naive fusion framework. Surprisingly, we observe that fusing these two modalities does not consistently outperform the best single modality by following the naive fusion framework. Further investigation reveals an potential imbalance issue in naive fusion, where the ID dominates and text modality is undertrained. This suggests that the unexpected observation may stem from naive fusion's failure to effectively balance the two modalities, often over-relying on the stronger ID modality. This insight suggests that naive fusion might not be as effective in combining ID and text as previously expected. To address this, we propose a novel alternative training strategy AlterRec. It separates the training of ID and text, thereby avoiding the imbalance issue seen in naive fusion. Additionally, AlterRec designs a novel strategy to facilitate the interaction between the two modalities, enabling them to mutually learn from each other and integrate the text more effectively. Comprehensive experiments demonstrate the effectiveness of AlterRec in session-based recommendation. The implementation is available at https://github.com/Juanhui28/AlterRec.
- Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Recent developments in multilayer perceptron neural networks. In Proceedings of the seventh annual memphis area engineering and science conference, MAESC. 1–15.
- On Uni-Modal Feature Learning in Supervised Multi-Modal Learning. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (Eds.). PMLR, 8632–8656.
- On Uni-Modal Feature Learning in Supervised Multi-Modal Learning. arXiv preprint arXiv:2305.01233 (2023).
- Leveraging Large Language Models for Sequential Recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems. 1096–1102.
- Session-based Recommendations with Recurrent Neural Networks. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.).
- Core: simple and effective session-based recommendation within consistent representation space. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1796–1801.
- Towards universal sequence representation learning for recommender systems. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 585–593.
- Modality competition: What makes joint training of multi-modal network fail in deep learning?(provably). In International Conference on Machine Learning. PMLR, 9226–9259.
- Amazon-m2: A multilingual multi-locale shopping session dataset for recommendation and text generation. arXiv preprint arXiv:2307.09688 (2023).
- Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, Vol. 1. 2.
- Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1419–1428.
- MINER: multi-interest matching network for news recommendation. In Findings of the Association for Computational Linguistics: ACL 2022. 343–352.
- Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights. arXiv preprint arXiv:2305.11700 (2023).
- Multibench: Multiscale benchmarks for multimodal representation learning. arXiv preprint arXiv:2107.07502 (2021).
- Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013).
- Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197.
- Heterogeneous global graph neural networks for personalized session-based recommendation. In Proceedings of the fifteenth ACM international conference on web search and data mining. 775–783.
- Yoon-Joo Park and Alexander Tuzhilin. 2008. The long tail of recommender systems and how to leverage it. In Proceedings of the 2008 ACM conference on Recommender systems. 11–18.
- Balanced multimodal learning via on-the-fly gradient modulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8238–8247.
- Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019).
- Representation Learning with Large Language Models for Recommendation. arXiv preprint arXiv:2310.15950 (2023).
- BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Modeling user preference dynamics with coupled tensor factorization for social media recommendation. Journal of Ambient Intelligence and Humanized Computing 12 (2021), 9693–9712.
- Attention is all you need. Advances in neural information processing systems 30 (2017).
- What makes training multi-modal classification networks hard?. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12695–12705.
- LLMRec: Large Language Models with Graph Augmentation for Recommendation. arXiv preprint arXiv:2311.00423 (2023).
- Neural news recommendation with multi-head self-attention. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 6389–6394.
- Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks. In International Conference on Machine Learning. PMLR, 24043–24055.
- Session-based recommendation with graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 346–353.
- Where to go next for recommender systems? id-vs. modality-based recommender models revisited. arXiv preprint arXiv:2303.13835 (2023).
- Feature-level Deeper Self-Attention Network for Sequential Recommendation.. In IJCAI. 4320–4326.
- S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM international conference on information & knowledge management. 1893–1902.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

