- The paper introduces GraphToken, a method leveraging graph neural networks and soft-prompts to encode structured data for large language models.
- It significantly improves graph reasoning tasks, achieving up to 73% performance enhancement on benchmarks such as GraphQA.
- The approach trains a dedicated graph encoder while freezing LLM parameters, enhancing resource efficiency and factual grounding.
Encoding Structured Data for LLMs: GraphToken
Introduction
The paper "Let Your Graph Do the Talking: Encoding Structured Data for LLMs" (2402.05862) presents a methodological advancement for encoding structured data in a manner suitable for LLMs. With a focus on enhancing graph reasoning tasks, the authors introduce GraphToken, which represents structured data via a novel parameter-efficient encoder that explicitly incorporates graph structure into LLM prompts. This approach diverges from traditional hand-crafted, text-based serialization methods by utilizing a learned graph prompt function that extends LLM capabilities for various reasoning tasks.
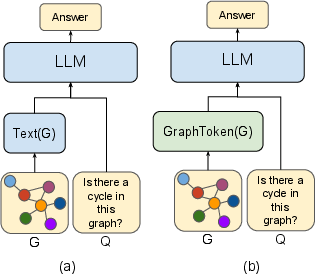
Figure 1: Graph encoding options for a frozen LLM.
Methodology
GraphToken Architecture
GraphToken's architecture leverages both soft-prompt approaches and graph neural networks (GNNs) to encode structured data. The architecture consists of two primary components: a graph encoder and an LLM. The graph encoder transforms the graph structure into graph tokens, which are embedded in the LLM's token space, preserving the model's linguistic capabilities while incorporating structured information.
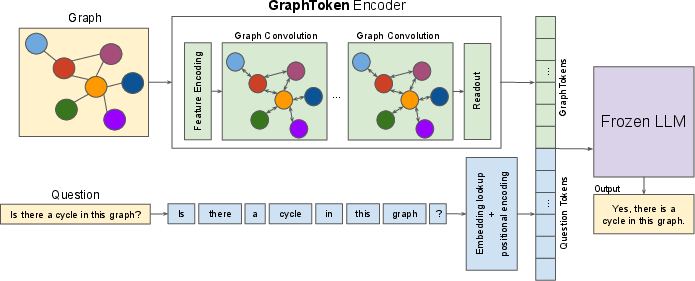
Figure 2: A visual overview of the architecture of GraphToken. The framework takes a graph and a corresponding question as input.
Training Procedure
GraphToken is trained by optimizing the perplexity of the expected answer using the LLM's gradients concerning the graph encoding. This training paradigm capitalizes on the computational efficiency by freezing the LLM parameters while adjusting only the graph encoder, thereby requiring a fraction of the computational resources compared to full LLM training.
Results
GraphToken demonstrates marked improvements in graph reasoning benchmarks, particularly the GraphQA benchmark, showing enhancements of up to 73% points in task performance. The evaluation encompassed various graph-related tasks such as node counting, cycle checks, and edge existence queries, delineating GraphToken's efficacy in handling both graph-level and node-level tasks.
Discussion
Encoder Analysis
The study reveals that the choice of graph convolution architecture significantly impacts performance across tasks. A diverse range of encoders, including GIN, MPNN, and attention-based models like HGT and MHA, were evaluated, highlighting that no single encoder universally excels. However, attention-based architectures generally provided robust encoding across tasks, underscoring the importance of tailored encoder selection for specific graph reasoning challenges.
Feature Utilization
Breaking equivariance via learned positional encodings proved beneficial, particularly in graph reasoning tasks, suggesting that embedding non-equivariant features can enhance task performance in LLMs paired with GNNs.
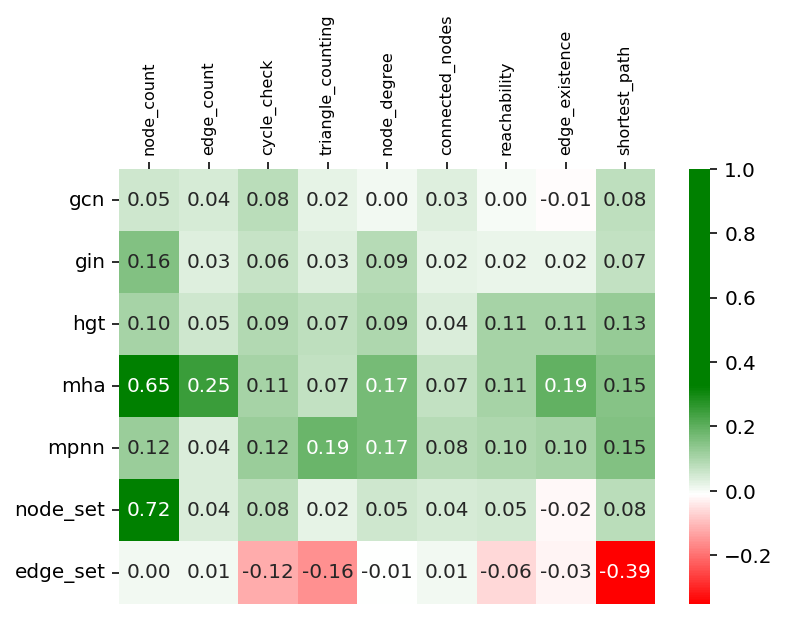

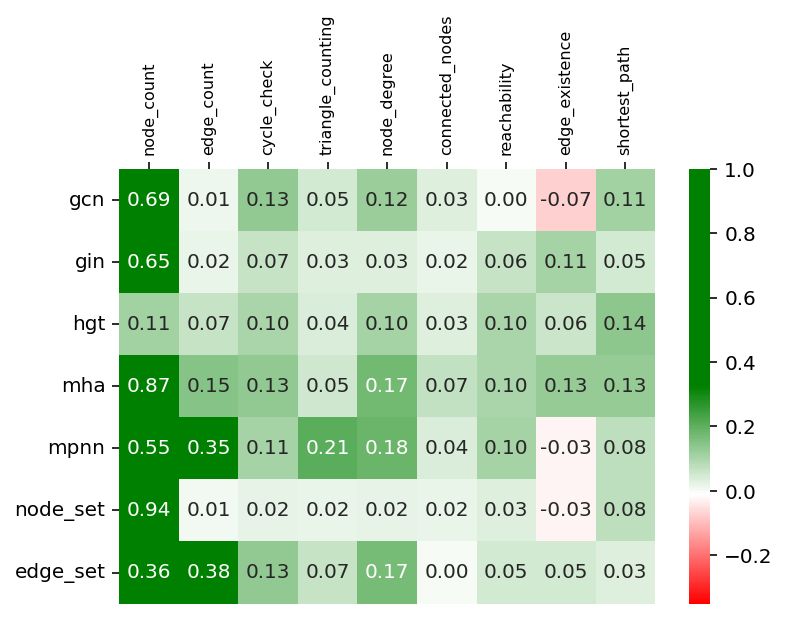
Figure 3: Spectral Features (LPE).
Implications
GraphToken offers a transformative approach to enhancing LLMs with structured encodings, opening pathways for integrating real-world relational data like social networks and molecular structures into AI systems. This method promises to alleviate LLM limitations such as hallucinations and freshness issues by embedding factual and structured data directly into prompt inputs.
Future Work
Several exciting avenues for future exploration include designing graph convolutions optimized for LLMs, using GraphToken for knowledge grounding in various domains, and potentially using LLMs to interrogate GNNs for better explanatory capabilities. Such advancements could significantly broaden the applicability and functionality of LLMs in handling structured data.
Conclusion
GraphToken represents an innovative step forward in encoding structured data for LLMs. Its capability to improve graph reasoning tasks in a parameter-efficient manner signals its potential utility in broader AI domains. As LLMs continue to integrate more diverse data forms, approaches like GraphToken will be crucial in addressing both technical challenges and practical applications in machine learning.