- The paper introduces MOMENT, a modular open time-series foundation model employing masked token prediction and multi-dataset pre-training.
- The paper shows competitive performance in forecasting, imputation, classification, and anomaly detection against leading methods.
- The paper discusses scalable and transparent approaches to time-series analysis, opening avenues for multi-modal applications and further research.
MOMENT: A Family of Open Time-Series Foundation Models
This paper presents "MOMENT: A Family of Open Time-Series Foundation Models," introducing MOMENT as a modular solution for general-purpose time series analysis. Focusing on multi-dataset pre-training, MOMENT aims to provide a robust architecture capable of handling various time-series tasks such as classification, forecasting, anomaly detection, and imputation. The discussion below outlines the model's methodology, features, empirical evaluations, and potential implications.
Methodology and Architecture
MOMENT is designed around transformer models, tailored specifically for time series data by employing patch-based tokenization. The method involves:
- Patch Extraction and Embedding: Time series are segmented into fixed-length patches, which are converted into D-dimensional embeddings. The masking strategy uses special embeddings, promoting a masked token prediction mechanism that effectively learns representations without zero-padding biases.
- Pre-training Objective: MOMENT is trained using a masked time series modeling approach. The main goal is minimizing reconstruction error (MSE) of masked patches, facilitating robust feature learning across extensive datasets.
- Model Variants: MOMENT comes in different sizes analogous to T5 configurations, ranging from small (40M parameters) to large (385M parameters). This diversity ensures applicability in various deployment scenarios, aligning computational demands with available infrastructure.
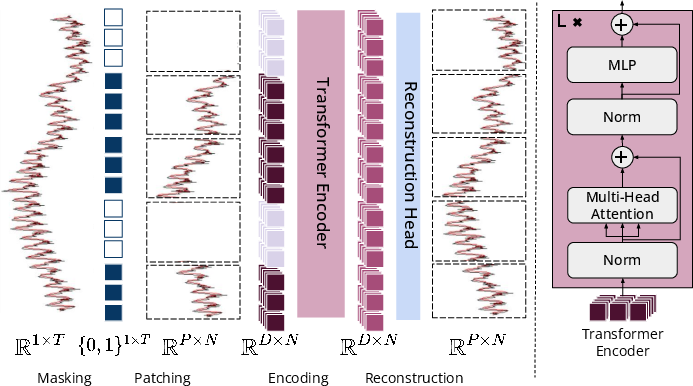
Figure 1: Overview of MOMENT.
Dataset Compilation and Pre-Training
A significant contribution of MOMENT is the compilation of the Time Series Pile, a diverse collection of datasets pooled from public sources across various domains such as healthcare, finance, and nature. This database underpins MOMENT's multi-dataset pre-training strategy, ensuring the model learns generalized representations suitable for different time-series tasks.
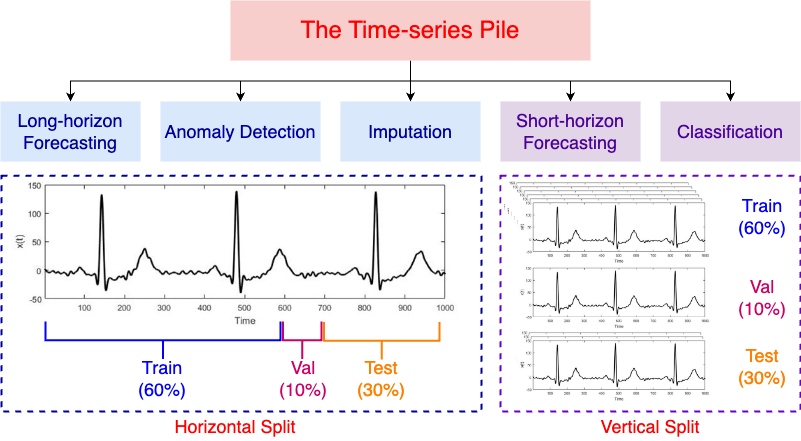
Figure 2: Time Series Pile data splits.
Experimental Evaluation
The paper showcases extensive experiments across several tasks under limited supervision settings, demonstrating MOMENT's high adaptability:
- Forecasting & Imputation: MOMENT achieved competitive results compared to leading methods such as PatchTST and TimesNet, particularly in zero-shot forecasting and few-shot imputation settings.
- Classification & Anomaly Detection: Even in unsupervised settings, MOMENT exhibited strong performance, rivaling supervised approaches and indicating its capacities for generalized representation learning.
- Interpretability and Cross-Modality: Analysis shows that MOMENT captures essential time series characteristics such as trend and frequency modulation. Further exploration reveals its utility in cross-modal tasks, reflecting the versatile applicability akin to LLMs.
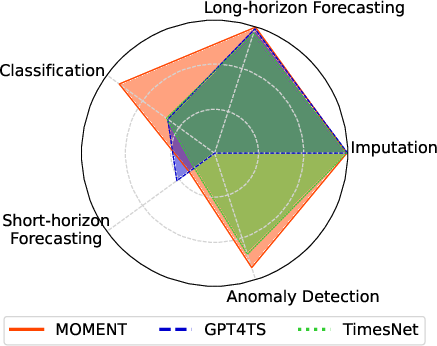
Figure 3: MOMENT can solve multiple time series analysis tasks well.
Practical Implications and Future Directions
MOMENT establishes a promising baseline for open time-series foundation models, promoting an age of adaptability and reuse in AI applications. Key implications include:
- Open Science & Transparency: The endeavors to compile comprehensive datasets and release code promote open science initiatives, setting a precedent for transparent AI methodologies.
- Scalability in Time-Series Modeling: MOMENT's architecture supports scalable solutions, encouraging further research into tokenization and model efficiency improvements.
- Multi-modal Learning: Findings encourage the exploration of learning beyond time series into integrated multi-modal settings, leveraging MOMENT's inherent flexibility.
Given its promising results, future work might explore causal attention mechanisms and further optimization of dataset mixtures to consolidate its utility across more complex domains.
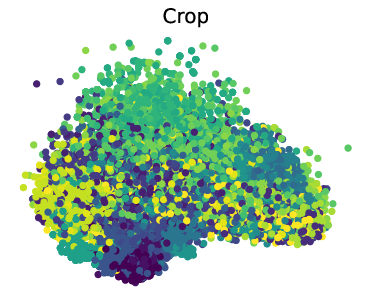

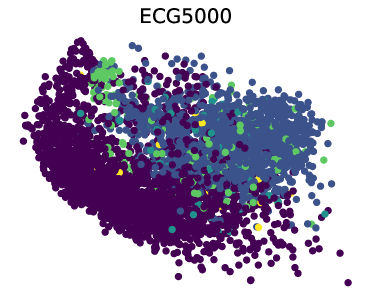
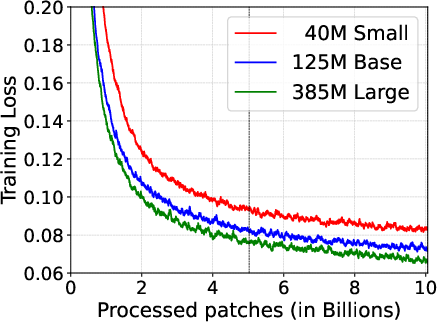
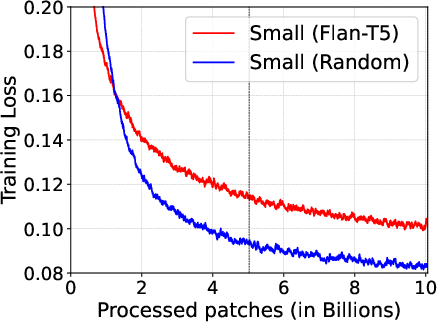
Figure 4: PCA and t-SNE visualizations of representations learned by MOMENT.
Conclusion
MOMENT emerges as a pivotal tool in time-series analytics, with robust architecture and comprehensive data support underscoring its capabilities. Its openness and multidisciplinary approach invite further collaboration and innovation across the AI research community, paving the way for next-generation analytics utilizing foundation models.