Augmenting Replay in World Models for Continual Reinforcement Learning
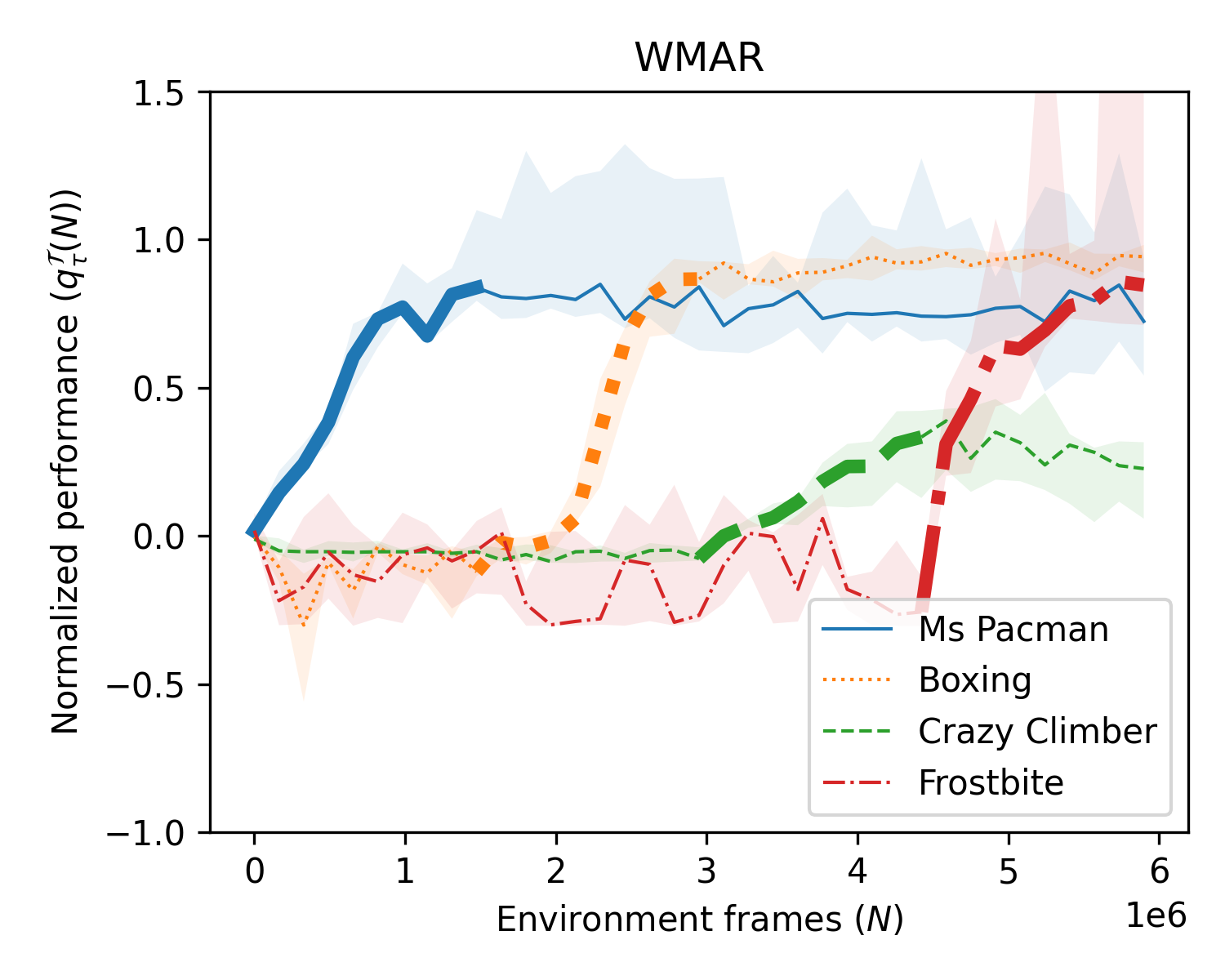
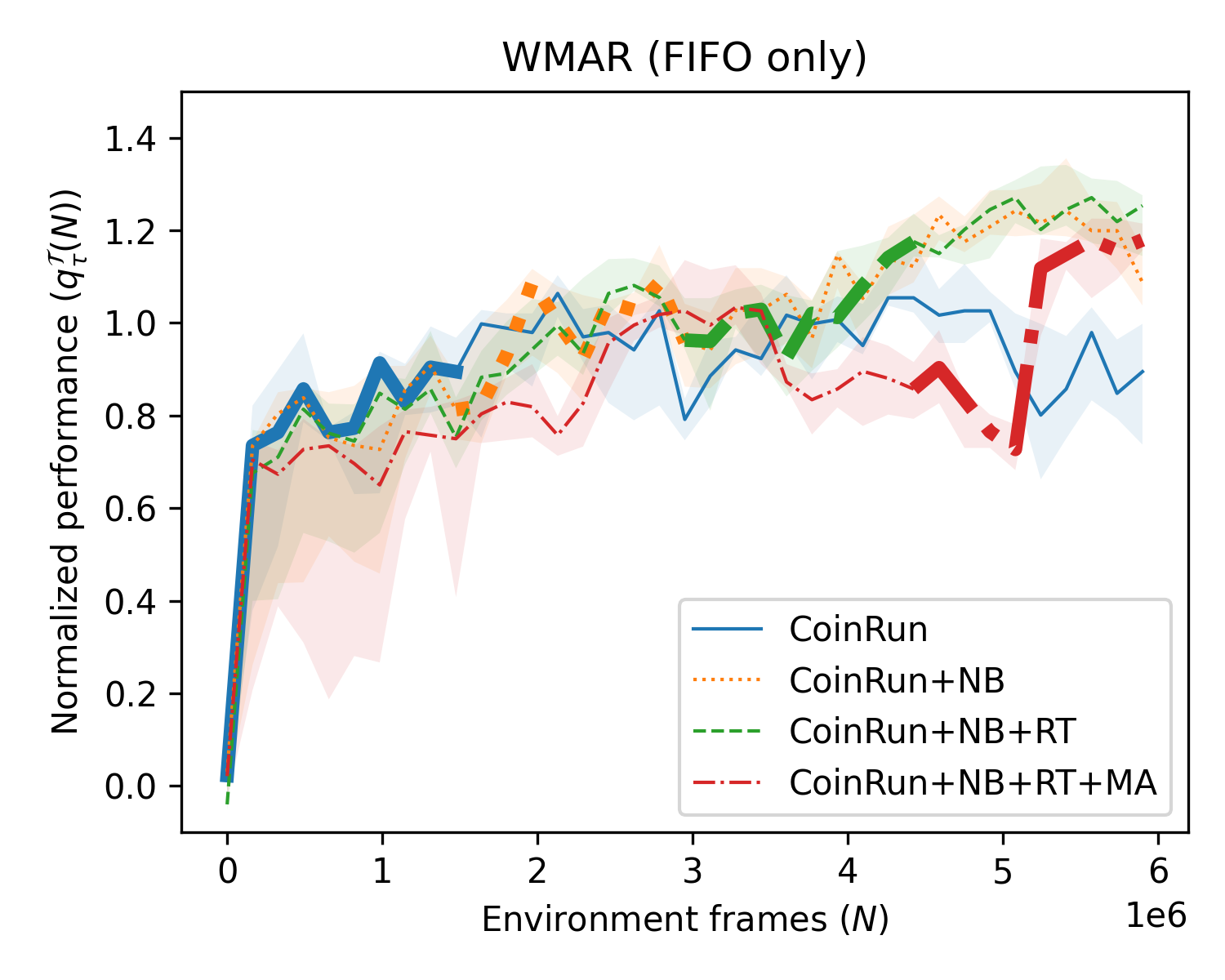
Abstract: Continual RL requires an agent to learn new tasks without forgetting previous ones, while improving on both past and future tasks. The most common approaches use model-free algorithms and replay buffers can help to mitigate catastrophic forgetting, but often struggle with scalability due to large memory requirements. Biologically inspired replay suggests replay to a world model, aligning with model-based RL; as opposed to the common setting of replay in model-free algorithms. Model-based RL offers benefits for continual RL by leveraging knowledge of the environment, independent of policy. We introduce WMAR (World Models with Augmented Replay), a model-based RL algorithm with a memory-efficient distribution-matching replay buffer. WMAR extends the well known DreamerV3 algorithm, which employs a simple FIFO buffer and was not tested in continual RL. We evaluated WMAR and DreamerV3, with the same-size replay buffers. They were tested on two scenarios: tasks with shared structure using OpenAI Procgen and tasks without shared structure using the Atari benchmark. WMAR demonstrated favourable properties for continual RL considering metrics for forgetting as well as skill transfer on past and future tasks. Compared to DreamerV3, WMAR showed slight benefits in tasks with shared structure and substantially better forgetting characteristics on tasks without shared structure. Our results suggest that model-based RL with a memory-efficient replay buffer can be an effective approach to continual RL, justifying further research.
- Learning dexterous in-hand manipulation. The International Journal of Robotics Research, 39(1):3–20, 2020. _eprint: https://doi.org/10.1177/0278364919887447.
- DeepMind Lab, December 2016. arXiv:1612.03801 [cs].
- The Arcade Learning Environment: An Evaluation Platform for General Agents. Journal of Artificial Intelligence Research, 47:253–279, June 2013.
- Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
- A massively parallel architecture for a self-organizing neural pattern recognition machine. Computer Vision, Graphics, and Image Processing, 37(1):54–115, 1987.
- Leveraging Procedural Generation to Benchmark Reinforcement Learning. In Proceedings of the 37th International Conference on Machine Learning, pages 2048–2056. PMLR, November 2020. ISSN: 2640-3498.
- Robert M French. Catastrophic forgetting in connectionist networks. Trends in cognitive sciences, 3(4):128–135, 1999. Publisher: Elsevier.
- World Models. arXiv preprint arXiv:1803.10122, March 2018. arXiv:1803.10122 [cs, stat].
- Learning Latent Dynamics for Planning from Pixels. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2555–2565. PMLR, June 2019.
- Dream to Control: Learning Behaviors by Latent Imagination, March 2020. arXiv:1912.01603 [cs].
- Mastering Atari with Discrete World Models, February 2022. arXiv:2010.02193 [cs, stat].
- Mastering Diverse Domains through World Models, January 2023. arXiv:2301.04104 [cs, stat].
- Neuroscience-Inspired Artificial Intelligence. Neuron, 95(2):245–258, July 2017. Publisher: Elsevier.
- Selective Experience Replay for Lifelong Learning. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), April 2018. Number: 1.
- The Surprising Effectiveness of Latent World Models for Continual Reinforcement Learning, November 2022. arXiv:2211.15944 [cs].
- Towards Continual Reinforcement Learning: A Review and Perspectives. Journal of Artificial Intelligence Research, 75:1401–1476, December 2022.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526, March 2017. Publisher: Proceedings of the National Academy of Sciences.
- Combating Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear, March 2018. arXiv:1611.01211 [cs, stat].
- Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents. Journal of Artificial Intelligence Research, 61:523–562, March 2018.
- Mackenzie Weygandt Mathis. The neocortical column as a universal template for perception and world-model learning. Nature Reviews Neuroscience, 24(1):3–3, January 2023. Number: 1 Publisher: Nature Publishing Group.
- Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In Gordon H. Bower, editor, Psychology of Learning and Motivation, volume 24, pages 109–165. Academic Press, January 1989.
- Dota 2 with Large Scale Deep Reinforcement Learning, December 2019.
- Stable-Baselines3: Reliable Reinforcement Learning Implementations. Journal of Machine Learning Research, 22(268):1–8, 2021.
- Mark Bishop Ring. Continual learning in reinforcement environments. PhD thesis, University of Texas at Austin, Texas 78712, 1994.
- Experience Replay for Continual Learning. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’ Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- Proximal Policy Optimization Algorithms, August 2017. arXiv:1707.06347 [cs].
- Progress & Compress: A scalable framework for continual learning. In Proceedings of the 35th International Conference on Machine Learning, pages 4528–4537. PMLR, July 2018. ISSN: 2640-3498.
- Continual Learning with Deep Generative Replay. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782):350–354, November 2019. Number: 7782 Publisher: Nature Publishing Group.
- Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992. Publisher: Springer.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

