- The paper introduces ABC-RL, a retrieval-guided RL framework that dynamically adjusts pre-trained policies using similarity scores to improve quality-of-result.
- It employs graph neural networks for feature extraction and adaptive modulation, achieving up to 24.8% area-delay product reduction and 9x faster runtime.
- Empirical evaluations on diverse benchmarks demonstrate ABC-RL’s robustness and scalability for optimizing Boolean circuit minimization in chip design.
Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization
Introduction
The optimization of chip design specifications within the hardware description languages fundamentally rests upon the logic synthesis process, which involves converting these specifications into efficient Boolean logic gate implementations. This synthesis, encapsulated within a "synthesis recipe," comprises sequential applications of logic minimization heuristics whose arrangement directly influences key performance metrics such as area and delay. The research paper "Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization" (2401.12205) explores the challenges faced by pre-trained reinforcement learning agents when exposed to entirely novel designs, resulting in detrimental shifts in the search trajectory. To address this, the authors introduce ABC-RL, a method that adapts recommendations from pre-trained agents through a finely tuned α parameter, computed based on similarity scores from nearest neighbor retrievals. Their results demonstrate notable enhancements in Quality-of-Result (QoR) with improvements up to 24.8% over existing techniques.
Methodology
The paper proposes ABC-RL, a retrieval-guided reinforcement learning (RL) framework for logic synthesis that leverages historical data and dynamically adjusts the contribution of pre-trained policy agents during the synthesis process. The key components of ABC-RL include:
- Similarity Score-Based Tuning: The process of modulating the influence of pre-trained agents through similarity scores obtained by comparing test designs with nearest neighbors in the training set. Depending on the novelty of the design, α is adjusted to either fully utilize or partially disregard pre-trained recommendations, creating a balance between learned policies and pure search strategies.
- Neural Architectures: ABC-RL employs graph neural networks (GNNs) to extract meaningful features from the input netlists, aiding in both retrieval and synthesis optimization phases. The policy network encodes the netlist as well as the sequence of synthesis actions taken, facilitating the decision-making process for action selection during synthesis.
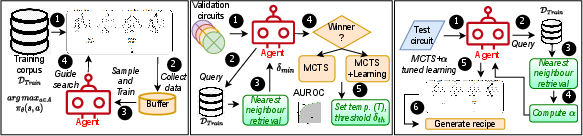
Figure 1: ABC-RL flow: Training the agent (left), setting temperature T and threshold δth.
- Adaptive Modulation During Search: The weighted recommendations from pre-trained RL agents are fine-tuned based on the similarity scores, ensuring that search strategies remain effective even when faced with out-of-distribution designs that potentially divert the search towards suboptimal recipes.
Experimental Results
The paper's experimental evaluation spans three widely used logic synthesis benchmark suites: MCNC, EPFL arithmetic, and EPFL random control benchmarks. Results highlighted include:
- Superior QoR Improvement: ABC-RL achieves 24.8% average improvement in area-delay product (ADP) reduction compared to state-of-the-art methods such as MCTS and SA+Pred, with consistently better results across diverse hardware designs.
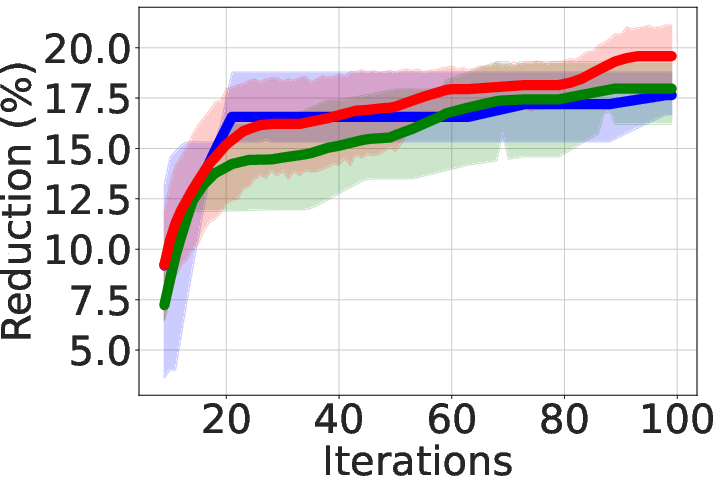
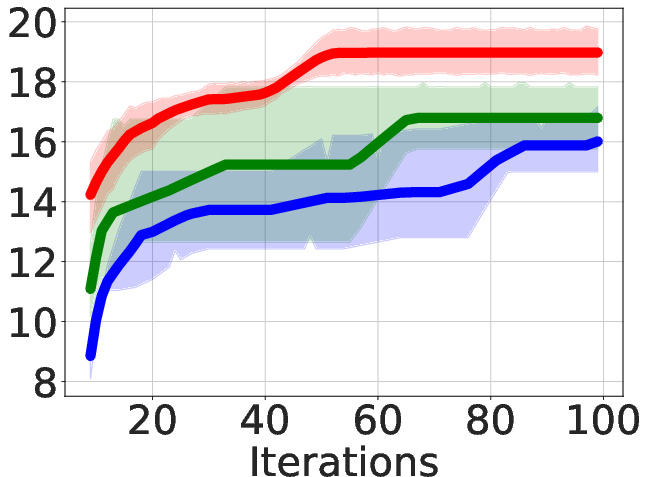
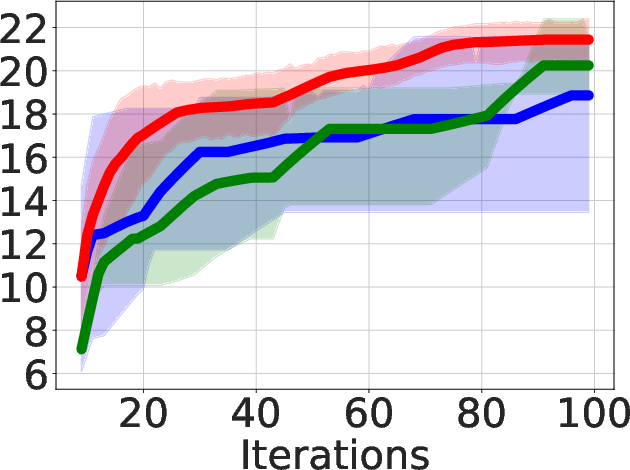
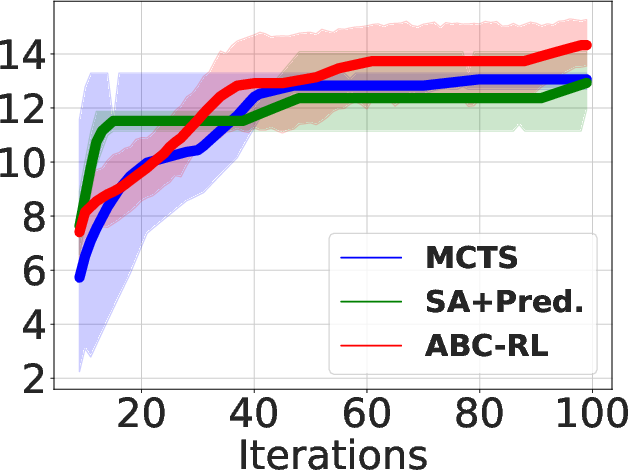
Figure 2: Area-delay product reduction (in \%) compared to resyn2 on MCNC circuits.
- Runtime Efficiency: The framework achieves substantial runtime reductions, up to 9 times faster compared to existing solutions, facilitating quicker synthesis while maintaining the quality of results.
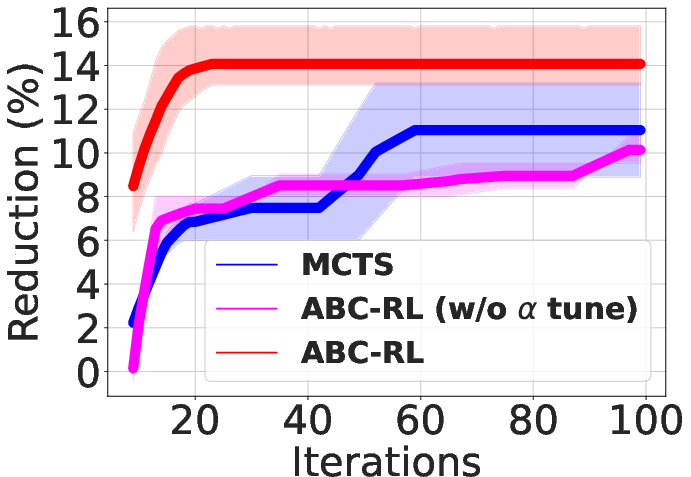
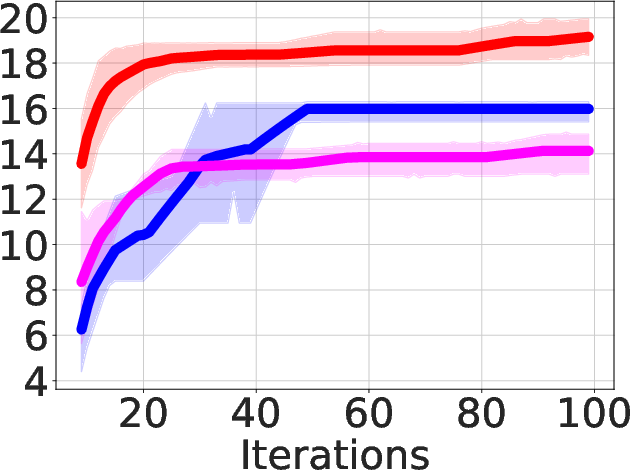
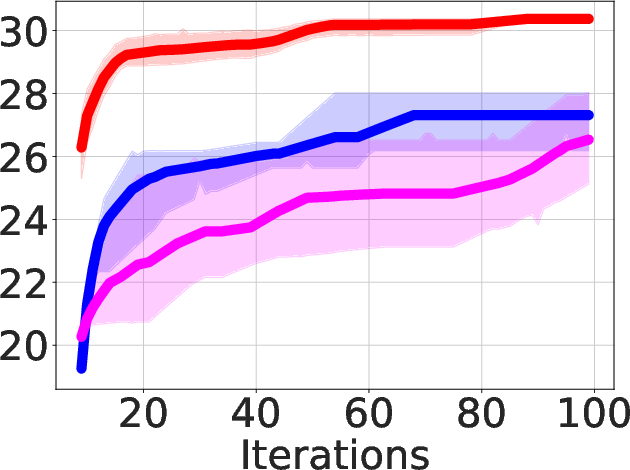
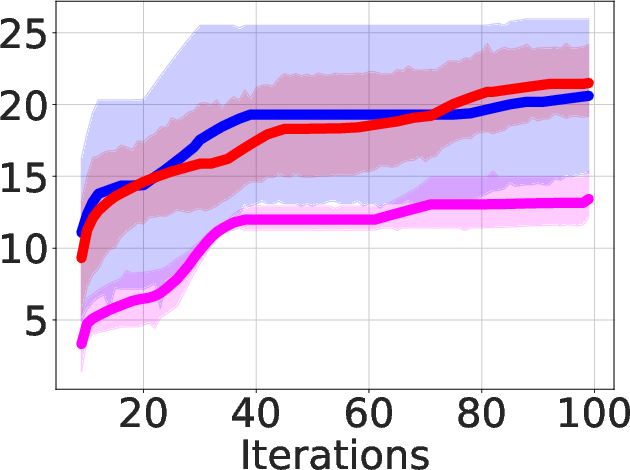
Figure 3: Area-delay product reduction (in \%) using ABC-RL compared to MCTS+Learning.
- Benchmark-Specific Performance: ABC-RL demonstrates robustness across different benchmarks, outperforming the benchmark-specific agents trained separately on individual suites, highlighting its adaptability to diverse input characteristics.
Implications and Future Work
The implications of ABC-RL are profound for electronic design automation (EDA), especially in the field of logic synthesis, where the ability to efficiently optimize diverse designs can lead to enhanced chip performance and reduced manufacturing costs. The retrieval-guided approach not only provides flexibility and robustness in handling distribution shifts in design inputs but also offers a scalable solution that could be extended to other reinforcement learning (RL) domains where similar challenges exist. Future research avenues may include exploring extended retrieval strategies to refine similarity computation or integrating functionality-aware embeddings to further enhance synthesis outcomes.
Conclusion
The study showcases ABC-RL as a powerful tool in the pursuit of optimizing Boolean circuit minimization, leveraging past design experiences while dynamically adjusting search contributions based on similarity scoring. Through empirical evaluations, ABC-RL consistently outperforms traditional methods in terms of QoR and runtime, proving its value in the rigorous field of chip design optimization. The strategic adaptation to unseen designs exemplifies its potential for broad applicability in not only logic synthesis but other complex RL-driven optimization tasks.