Vlogger: Make Your Dream A Vlog
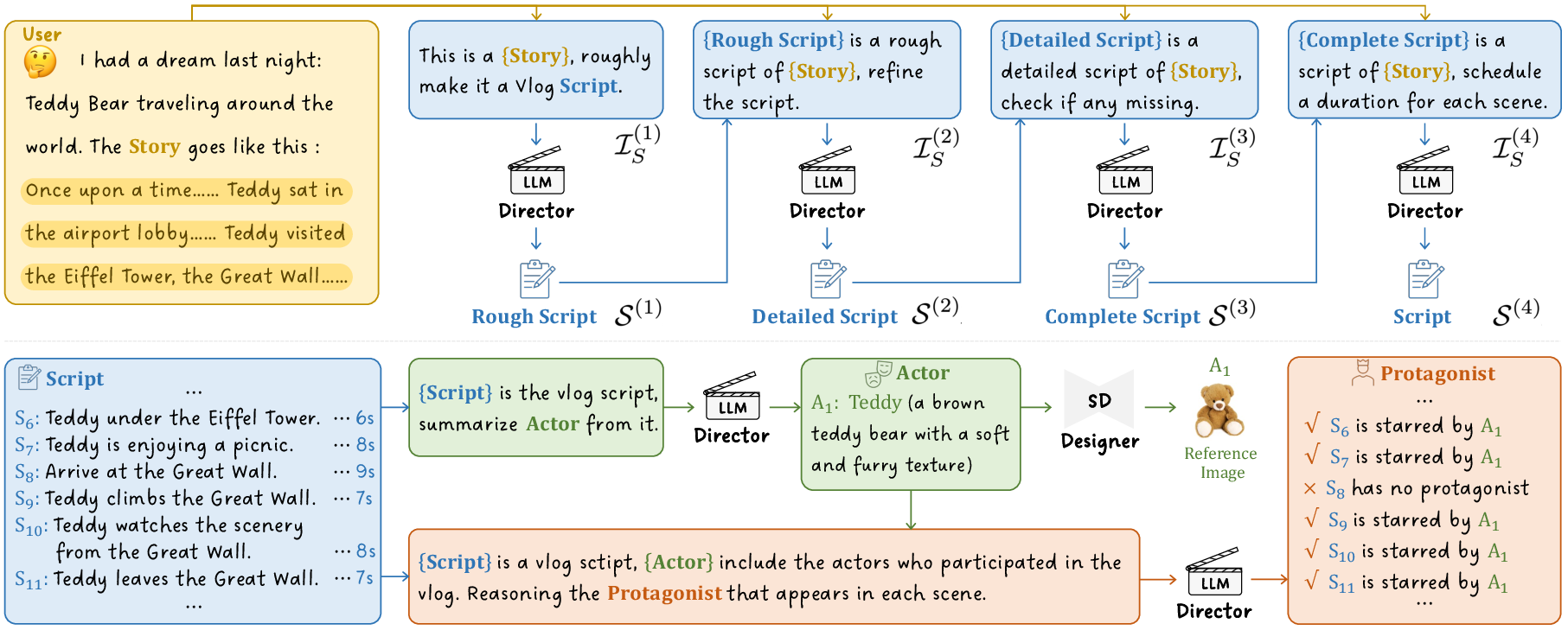
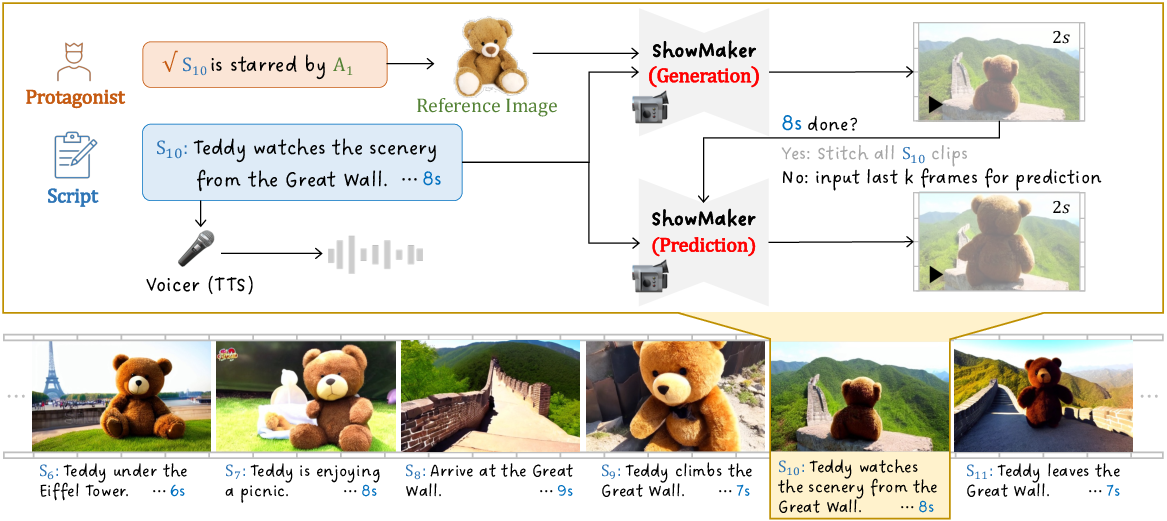
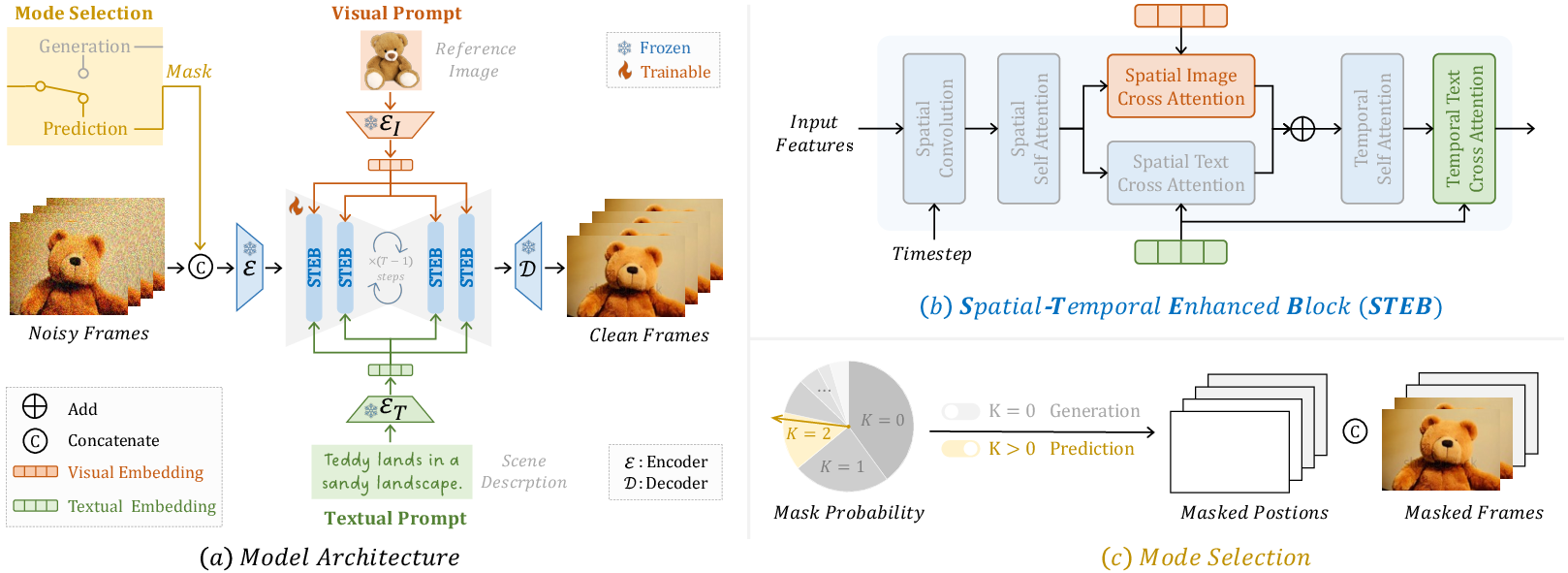
Abstract: In this work, we present Vlogger, a generic AI system for generating a minute-level video blog (i.e., vlog) of user descriptions. Different from short videos with a few seconds, vlog often contains a complex storyline with diversified scenes, which is challenging for most existing video generation approaches. To break through this bottleneck, our Vlogger smartly leverages LLM as Director and decomposes a long video generation task of vlog into four key stages, where we invoke various foundation models to play the critical roles of vlog professionals, including (1) Script, (2) Actor, (3) ShowMaker, and (4) Voicer. With such a design of mimicking human beings, our Vlogger can generate vlogs through explainable cooperation of top-down planning and bottom-up shooting. Moreover, we introduce a novel video diffusion model, ShowMaker, which serves as a videographer in our Vlogger for generating the video snippet of each shooting scene. By incorporating Script and Actor attentively as textual and visual prompts, it can effectively enhance spatial-temporal coherence in the snippet. Besides, we design a concise mixed training paradigm for ShowMaker, boosting its capacity for both T2V generation and prediction. Finally, the extensive experiments show that our method achieves state-of-the-art performance on zero-shot T2V generation and prediction tasks. More importantly, Vlogger can generate over 5-minute vlogs from open-world descriptions, without loss of video coherence on script and actor. The code and model is all available at https://github.com/zhuangshaobin/Vlogger.
- Suno AI. bark. https://github.com/suno-ai/bark#-usage-in-python, 2023.
- Qwen technical report. ArXiv, abs/2309.16609, 2023.
- Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, 2021.
- ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. ArXiv, abs/2211.01324, 2022.
- Conditional gan with discriminative filter generation for text-to-video synthesis. In IJCAI, 2019.
- Improving image generation with better captions. 2023.
- Disentangling multiple features in video sequences using gaussian processes in variational autoencoders. In ECCV, 2020.
- Align your latents: High-resolution video synthesis with latent diffusion models. In CVPR, 2023.
- Generating long videos of dynamic scenes. In NeurIPS, 2022.
- Language models are few-shot learners. In NeurIPS, 2020.
- Maskgit: Masked generative image transformer. In CVPR, 2022.
- The msr-video to text dataset with clean annotations. Comput. Vis. Image Underst., 225:103581, 2021.
- Long-term video prediction via criticization and retrospection. IEEE TIP, 29:7090–7103, 2020.
- Seine: Short-to-long video diffusion model for generative transition and prediction. ArXiv, abs/2310.20700, 2023.
- François Chollet. On the measure of intelligence. ArXiv, abs/1911.01547, 2019.
- Palm: Scaling language modeling with pathways. JMLR, 24:240:1–240:113, 2022.
- Adversarial video generation on complex datasets. arXiv: Computer Vision and Pattern Recognition, 2019.
- Emu: Enhancing image generation models using photogenic needles in a haystack. ArXiv, abs/2309.15807, 2023.
- Jointly trained image and video generation using residual vectors. WACV, pages 3017–3031, 2019.
- Taming transformers for high-resolution image synthesis. In CVPR, 2020.
- Tell me what happened: Unifying text-guided video completion via multimodal masked video generation. In CVPR, 2023.
- Vlogging: A survey of videoblogging technology on the web. ACM Computing Surveys, 2010.
- Long video generation with time-agnostic vqgan and time-sensitive transformer. In ECCV, 2022a.
- Long video generation with time-agnostic vqgan and time-sensitive transformer. In ECCV, 2022b.
- Preserve your own correlation: A noise prior for video diffusion models. ArXiv, abs/2305.10474, 2023.
- Visual programming: Compositional visual reasoning without training. In CVPR, 2023.
- Latent video diffusion models for high-fidelity long video generation. ArXiv, abs/2211.13221, 2023.
- Deep learning scaling is predictable, empirically. ArXiv, abs/1712.00409, 2017.
- Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017.
- Classifier-free diffusion guidance. In NeurIPS Workshops, 2021.
- Denoising diffusion probabilistic models. In NeurIPS, 2020.
- Imagen video: High definition video generation with diffusion models. ArXiv, abs/2210.02303, 2022a.
- Video diffusion models. ArXiv, abs/2204.03458, 2022b.
- Cogvideo: Large-scale pretraining for text-to-video generation via transformers. In ICLR, 2023.
- Diffusion models for video prediction and infilling. TMLR, 2022, 2022.
- Free-bloom: Zero-shot text-to-video generator with llm director and ldm animator. ArXiv, abs/2309.14494, 2023.
- Openclip. https://github.com/mlfoundations/open_clip, 2021.
- The kinetics human action video dataset. ArXiv, abs/1705.06950, 2017.
- Matryoshka representation learning. In NeurIPS, 2022.
- Videochat: Chat-centric video understanding. ArXiv, abs/2305.06355, 2023.
- Video generation from text. In AAAI, 2017.
- Microsoft coco: Common objects in context. In ECCV, 2014.
- Visual instruction tuning. In NeurIPS, 2022.
- Decoupled weight decay regularization. In ICLR, 2017.
- Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In ICML, 2021.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- On aliased resizing and surprising subtleties in gan evaluation. In CVPR, 2022.
- Sdxl: Improving latent diffusion models for high-resolution image synthesis. ArXiv, abs/2307.01952, 2023.
- Freenoise: Tuning-free longer video diffusion via noise rescheduling. ArXiv, abs/2310.15169, 2023.
- Learning transferable visual models from natural language supervision. In ICML, 2021.
- Hierarchical text-conditional image generation with clip latents. ArXiv, abs/2204.06125, 2022.
- High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- U-net: Convolutional networks for biomedical image segmentation. ArXiv, abs/1505.04597, 2015.
- Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022.
- Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. ArXiv, abs/2111.02114, 2021.
- Laion-5b: An open large-scale dataset for training next generation image-text models. In NeurIPS, 2022.
- Make-a-video: Text-to-video generation without text-video data. In ICLR, 2023.
- Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In CVPR, 2021.
- Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In CVPR, 2022.
- Score-based generative modeling through stochastic differential equations. In ICLR, 2021.
- Ucf101: A dataset of 101 human actions classes from videos in the wild. ArXiv, abs/1212.0402, 2012.
- Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. ArXiv, abs/2107.02137, 2021.
- InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM, 2023.
- Motion-based generator model: Unsupervised disentanglement of appearance, trackable and intrackable motions in dynamic patterns. In ICLR, 2019.
- A good image generator is what you need for high-resolution video synthesis. In ICLR, 2021.
- Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023.
- Towards accurate generative models of video: A new metric & challenges. In ICLR, 2019.
- Phenaki: Variable length video generation from open domain textual description. In ICLR, 2023.
- Mcvd: Masked conditional video diffusion for prediction, generation, and interpolation. In NeurIPS, 2022.
- Gen-l-video: Multi-text to long video generation via temporal co-denoising. ArXiv, abs/2305.18264, 2023a.
- Modelscope text-to-video technical report. ArXiv, abs/2308.06571, 2023b.
- Videofactory: Swap attention in spatiotemporal diffusions for text-to-video generation. ArXiv, abs/2305.10874, 2023c.
- G3an: Disentangling appearance and motion for video generation. In CVPR, 2020a.
- Imaginator: Conditional spatio-temporal gan for video generation. WACV, pages 1149–1158, 2020b.
- Inmodegan: Interpretable motion decomposition generative adversarial network for video generation. ArXiv, abs/2101.03049, 2021.
- Internvideo: General video foundation models via generative and discriminative learning. ArXiv, abs/2212.03191, 2022.
- Lavie: High-quality video generation with cascaded latent diffusion models. ArXiv, abs/2309.15103, 2023d.
- Godiva: Generating open-domain videos from natural descriptions. ArXiv, abs/2104.14806, 2021.
- Nüwa: Visual synthesis pre-training for neural visual world creation. In ECCV, 2022.
- Visual chatgpt: Talking, drawing and editing with visual foundation models. ArXiv, abs/2303.04671, 2023.
- Advancing high-resolution video-language representation with large-scale video transcriptions. In CVPR, 2021.
- Videogpt: Video generation using vq-vae and transformers. ArXiv, abs/2104.10157, 2021.
- Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. ArXiv, abs/2308.06721, 2023.
- Nuwa-xl: Diffusion over diffusion for extremely long video generation. In Annual Meeting of the Association for Computational Linguistics, 2023.
- Magvit: Masked generative video transformer. In CVPR, 2023.
- Generating videos with dynamics-aware implicit generative adversarial networks. In ICLR, 2022.
- Glm-130b: An open bilingual pre-trained model. ArXiv, abs/2210.02414, 2022.
- Show-1: Marrying pixel and latent diffusion models for text-to-video generation. ArXiv, abs/2309.15818, 2023a.
- Controllable text-to-image generation with gpt-4. ArXiv, abs/2305.18583, 2023b.
- Magicvideo: Efficient video generation with latent diffusion models. ArXiv, abs/2211.11018, 2022.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. ArXiv, abs/2304.10592, 2023a.
- Moviefactory: Automatic movie creation from text using large generative models for language and images. In ACM MM, 2023b.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.