xCoT: Cross-lingual Instruction Tuning for Cross-lingual Chain-of-Thought Reasoning
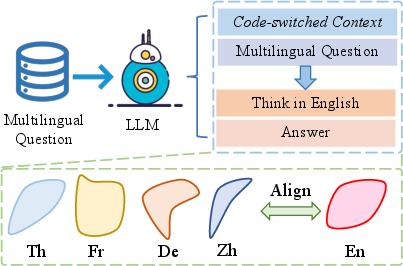
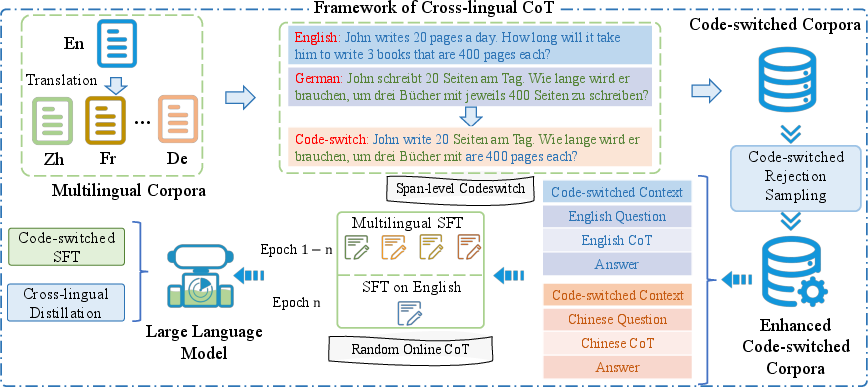
Abstract: Chain-of-thought (CoT) has emerged as a powerful technique to elicit reasoning in LLMs and improve a variety of downstream tasks. CoT mainly demonstrates excellent performance in English, but its usage in low-resource languages is constrained due to poor language generalization. To bridge the gap among different languages, we propose a cross-lingual instruction fine-tuning framework (xCOT) to transfer knowledge from high-resource languages to low-resource languages. Specifically, the multilingual instruction training data (xCOT-INSTRUCT) is created to encourage the semantic alignment of multiple languages. We introduce cross-lingual in-context few-shot learning (xICL)) to accelerate multilingual agreement in instruction tuning, where some fragments of source languages in examples are randomly substituted by their counterpart translations of target languages. During multilingual instruction tuning, we adopt the randomly online CoT strategy to enhance the multilingual reasoning ability of the LLM by first translating the query to another language and then answering in English. To further facilitate the language transfer, we leverage the high-resource CoT to supervise the training of low-resource languages with cross-lingual distillation. Experimental results on previous benchmarks demonstrate the superior performance of xCoT in reducing the gap among different languages, highlighting its potential to reduce the cross-lingual gap.
- Qwen technical report. CoRR, abs/2309.16609.
- Crosssum: Beyond english-centric cross-lingual summarization for 1, 500+ language pairs. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 2541–2564. Association for Computational Linguistics.
- Breaking language barriers in multilingual mathematical reasoning: Insights and observations. CoRR, abs/2310.20246.
- Breaking language barriers in multilingual mathematical reasoning: Insights and observations. arXiv preprint arXiv:2310.20246.
- Training verifiers to solve math word problems. CoRR, abs/2110.14168.
- Unsupervised cross-lingual representation learning at scale. In ACL 2020, pages 8440–8451.
- Alexis Conneau and Guillaume Lample. 2019. Cross-lingual language model pretraining. In NeurIPS 2019, pages 7057–7067.
- GLM: general language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 320–335. Association for Computational Linguistics.
- Multilingual clinical NER: translation or cross-lingual transfer? In Proceedings of the 5th Clinical Natural Language Processing Workshop, ClinicalNLP@ACL 2023, Toronto, Canada, July 14, 2023, pages 289–311. Association for Computational Linguistics.
- OWL: A large language model for IT operations. CoRR, abs/2309.09298.
- Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071.
- Large language models are zero-shot reasoners. In NeurIPS.
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583.
- XLM-T: scaling up multilingual machine translation with pretrained cross-lingual transformer encoders. CoRR, abs/2012.15547.
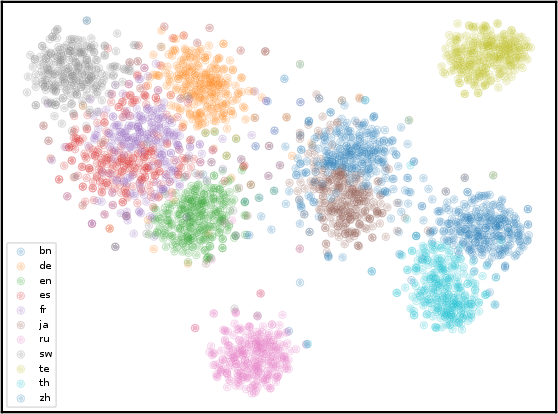
- Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. JMLR, 9(Nov):2579–2605.
- Crosslingual generalization through multitask finetuning. arXiv preprint arXiv:2211.01786.
- OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- Training language models to follow instructions with human feedback. In NeurIPS.
- Bidirectional language models are also few-shot learners. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pages 2080–2094. Association for Computational Linguistics.
- Cross-lingual prompting: Improving zero-shot chain-of-thought reasoning across languages. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 2695–2709. Association for Computational Linguistics.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
- Language models are multilingual chain-of-thought reasoners. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Multilingual neural machine translation with language clustering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pages 963–973. Association for Computational Linguistics.
- Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
- Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Understanding translationese in cross-lingual summarization. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 3837–3849. Association for Computational Linguistics.
- Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Emergent abilities of large language models. Transactions on Machine Learning Research. Survey Certification.
- Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Unitrans : Unifying model transfer and data transfer for cross-lingual named entity recognition with unlabeled data. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 3926–3932. ijcai.org.
- CROP: zero-shot cross-lingual named entity recognition with multilingual labeled sequence translation. In Findings of EMNLP 2022, pages 486–496.
- GanLM: Encoder-decoder pre-training with an auxiliary discriminator. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9394–9412, Toronto, Canada. Association for Computational Linguistics.
- Alternating language modeling for cross-lingual pre-training. In AAAI 2020, pages 9386–9393.
- High-resource language-specific training for multilingual neural machine translation. In IJCAI 2022, pages 4461–4467.
- UM4: unified multilingual multiple teacher-student model for zero-resource neural machine translation. In IJCAI 2022, pages 4454–4460.
- Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825.
- Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653.
- Multimodal chain-of-thought reasoning in language models. CoRR, abs/2302.00923.
- Conner: Consistency training for cross-lingual named entity recognition. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 8438–8449. Association for Computational Linguistics.
- Solving math word problems via cooperative reasoning induced language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4471–4485, Toronto, Canada. Association for Computational Linguistics.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.