Do Vision and Language Encoders Represent the World Similarly?
Abstract: Aligned text-image encoders such as CLIP have become the de facto model for vision-language tasks. Furthermore, modality-specific encoders achieve impressive performances in their respective domains. This raises a central question: does an alignment exist between uni-modal vision and language encoders since they fundamentally represent the same physical world? Analyzing the latent spaces structure of vision and LLMs on image-caption benchmarks using the Centered Kernel Alignment (CKA), we find that the representation spaces of unaligned and aligned encoders are semantically similar. In the absence of statistical similarity in aligned encoders like CLIP, we show that a possible matching of unaligned encoders exists without any training. We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs and propose two methods - a Fast Quadratic Assignment Problem optimization, and a novel localized CKA metric-based matching/retrieval. We demonstrate the effectiveness of this on several downstream tasks including cross-lingual, cross-domain caption matching and image classification. Code available at github.com/mayug/0-shot-LLM-vision.
- Towards zero-shot cross-lingual image retrieval. arXiv preprint arXiv:2012.05107, 2020.
- Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8948–8957, 2019.
- Low-dimensional structure in the space of language representations is reflected in brain responses. Advances in neural information processing systems, 2021.
- Revisiting model stitching to compare neural representations. Advances in neural information processing systems, 2021.
- Representation topology divergence: A method for comparing neural network representations. arXiv preprint arXiv:2201.00058, 2021.
- How do variational autoencoders learn? insights from representational similarity. arXiv preprint arXiv:2205.08399, 2022.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3558–3568, 2021.
- A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Word translation without parallel data. arXiv preprint arXiv:1710.04087, 2017.
- Algorithms for learning kernels based on centered alignment. The Journal of Machine Learning Research, 13(1):795–828, 2012.
- David F Crouse. On implementing 2d rectangular assignment algorithms. IEEE Transactions on Aerospace and Electronic Systems, 52(4):1679–1696, 2016.
- Similarity and matching of neural network representations. arXiv preprint arXiv:2110.14633, 2021.
- Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2009.
- An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Seeded graph matching. Pattern recognition, 87:203–215, 2019.
- Measuring statistical dependence with hilbert-schmidt norms. In International conference on algorithmic learning theory, pages 63–77. Springer, 2005.
- Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pages 297–304. JMLR Workshop and Conference Proceedings, 2010.
- Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021.
- Auto-encoding variational bayes. ICLR, 2014.
- Similarity of neural network representations revisited. In International conference on machine learning, pages 3519–3529. PMLR, 2019.
- Harold W Kuhn. The hungarian method for the assignment problem. Naval research logistics quarterly, 2(1-2):83–97, 1955.
- Understanding image representations by measuring their equivariance and equivalence. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 991–999, 2015.
- The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- Convergent learning: Do different neural networks learn the same representations? arXiv preprint arXiv:1511.07543, 2015.
- Microsoft coco: Common objects in context. In ECCV, 2014.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- A convnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022.
- The hsic bottleneck: Deep learning without back-propagation. In Proceedings of the AAAI conference on artificial intelligence, pages 5085–5092, 2020.
- Linearly mapping from image to text space. arXiv preprint arXiv:2209.15162, 2022.
- Exploiting similarities among languages for machine translation (2013). arXiv preprint arXiv:1309.4168, 2022.
- Insights on representational similarity in neural networks with canonical correlation. Advances in neural information processing systems, 31, 2018.
- Relative representations enable zero-shot latent space communication. In The Eleventh International Conference on Learning Representations, 2022.
- Asif: Coupled data turns unimodal models to multimodal without training. arXiv preprint arXiv:2210.01738, 2022.
- Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. Advances in neural information processing systems, 30, 2017.
- Do vision transformers see like convolutional neural networks? Advances in Neural Information Processing Systems, 34:12116–12128, 2021.
- Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2019.
- The shape of data: Intrinsic distance for data distributions. arXiv preprint arXiv:1905.11141, 2019.
- Fast approximate quadratic programming for graph matching. PLOS one, 10(4):e0121002, 2015.
- Are all good word vector spaces isomorphic? arXiv preprint arXiv:2004.04070, 2020.
- Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16133–16142, 2023.
- Similarity analysis of contextual word representation models. arXiv preprint arXiv:2005.01172, 2020.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of “Do Vision and Language Encoders Represent the World Similarly?”
Overview
This paper asks a big, simple question: do computer models that understand pictures and computer models that understand text see the world in the same way? Even if they were trained separately, the authors want to know whether these models organize information about the world in similar “shapes” inside their brains (their internal representation spaces).
Models like CLIP are trained to connect images and text directly, so they work great together. But many other powerful models are trained separately: some only on images, some only on text. This paper explores whether we can make those separate models “talk” to each other without training them together at all.
Goals and Questions
The authors set out to answer:
- Do image-only and text-only models represent similar meanings about the world?
- If they do, can we match images to the right captions without any extra training?
- Can this work across different datasets and even different languages?
How They Approached It (in Everyday Terms)
Think of two groups of friends who each drew their own map of the same city. Their maps look different, but the places (parks, schools, roads) are the same. The paper’s goal is to check if the two maps have similar patterns, and then use those patterns to find which caption belongs with which image.
Here are the key ideas they used:
- Centered Kernel Alignment (CKA): Imagine making a big table of how similar each item is to every other item (for images and for captions). CKA compares these two “similarity tables” to see if the patterns match. If the image table and the text table have similar structures, the models are likely seeing the world in similar ways.
- Matching by “rearranging” to maximize CKA (QAP): Suppose we shuffle which caption goes with which image. The right order should make the image and text similarity tables line up best. They turn this into a puzzle called the Quadratic Assignment Problem (QAP): find the best way to pair images and captions to make the tables look most alike. They use a “seeded” version (starting with a few known good pairs as anchors) to solve it faster.
- Local CKA for retrieval: If you have one query image and a bunch of possible captions, they add your query to a small set of known pairs and see how much it improves the matching pattern. The caption that increases the local CKA the most is likely the correct one. Think of it like checking which new friend fits best into an existing group based on everyone’s relationships.
- Stretching and clustering (to help the comparison): Stretching: they scale features so that no single dimension dominates (like adjusting the brightness so all colors are equally visible). Clustering: they pick diverse “base” examples by clustering (grouping) images, so the anchors cover many different concepts.
What They Found and Why It Matters
- Unaligned models still share meaning: Even when image and text encoders were trained separately (not like CLIP), their representations often showed strong semantic similarity. That means these models learn high-level concepts that line up surprisingly well.
- Zero-shot matching works: Using their CKA-based methods, they matched images to captions without training a bridge between the models. On popular datasets (like COCO and NoCaps), their methods performed well—often much better than other training-free baselines (like “relative representations” or simple linear regression).
- Cross-domain and cross-lingual success: Their approach worked across different datasets (COCO vs. NoCaps) and across languages. For languages where CLIP’s text side struggles (like non-Latin scripts), their method still worked by pairing CLIP’s vision encoder with a multilingual sentence transformer. In some non-English languages where CLIP’s retrieval dropped near zero, their local CKA method stayed strong (often above 50% in top-5 retrieval), showing a big advantage.
- Classification stays competitive: On ImageNet-100 classification, their training-free method got close to CLIP’s accuracy, especially with strong vision models like ConvNeXt.
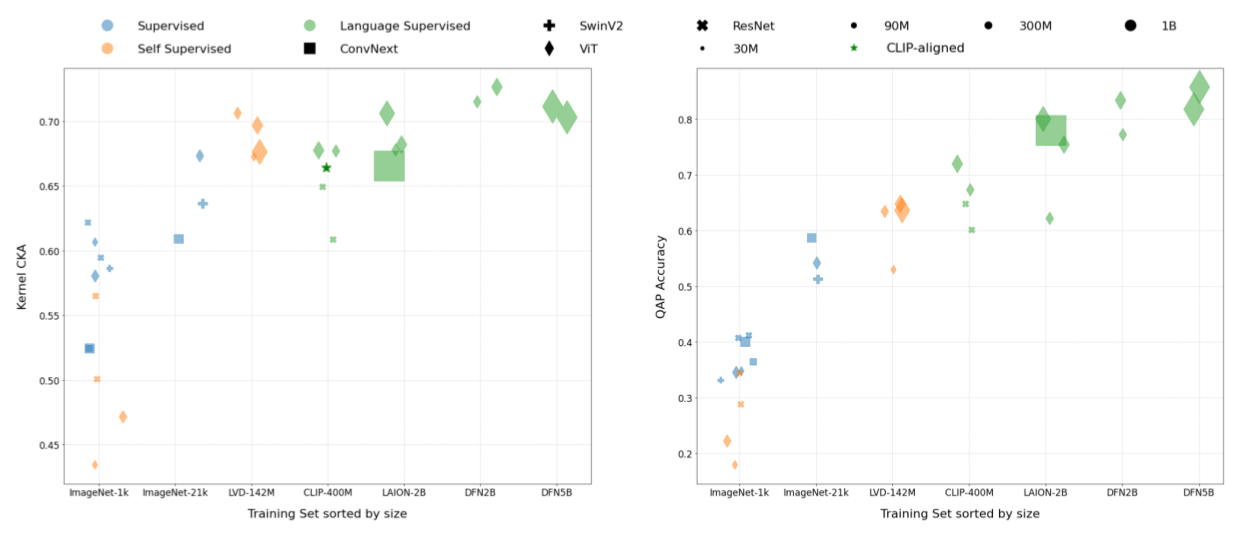
- Bigger and better data helps: The more and better data a vision model is trained on, the more its internal structure aligns with language encoders. Models trained with language supervision (like CLIP) tend to align even more strongly, but high-quality self-supervised models (like DINOv2) also showed solid alignment.
Implications and Impact
- Reuse powerful models without retraining: You can “plug together” a strong image encoder and a strong text encoder—even if they were trained separately—and still get useful image–text matching. That saves time and resources.
- Support many languages easily: By combining a good vision encoder (like CLIP’s image side) with a multilingual text encoder, you can do retrieval in languages CLIP wasn’t trained on. This helps low-resource languages and expands accessibility.
- Better understanding of representations: The results suggest that different models often learn similar world structures. Measuring similarity-of-similarities (with CKA) is a robust way to bridge them.
- Future steps: Faster implementations (especially for local CKA), smarter selection of anchor pairs, and broader testing could make these methods even more practical and widely used.
In short, this paper shows that vision and LLMs often think alike about the world—and with the right tools, we can connect them in a simple, training-free way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Theoretical recovery guarantees: No formal analysis establishes when maximizing CKA via seeded QAP or local CKA provably recovers the ground-truth permutation, under what noise models, and with what sample complexity.
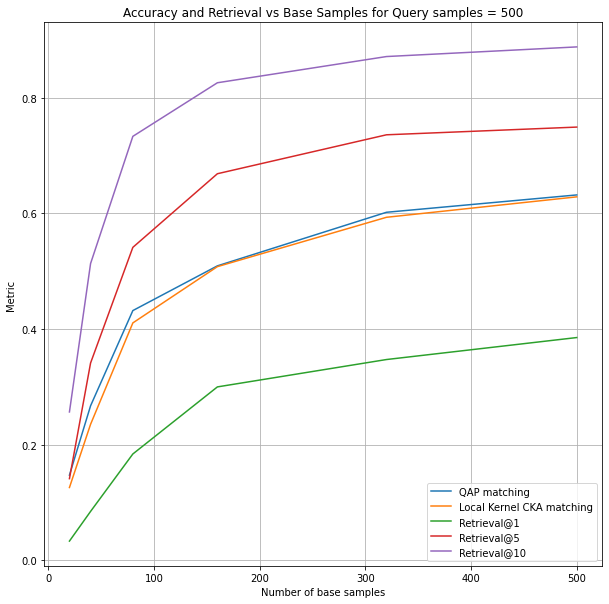
- Sensitivity to base set design: The methods depend on a set of aligned base pairs (seeds), but the paper lacks systematic curves and guidelines for base set size, selection strategies (e.g., k-means vs. other diversification heuristics), domain mismatch effects, and the minimal base size required to achieve target accuracies.
- Kernel choice and hyperparameters: The impact of kernel type (linear vs. RBF vs. other kernels), bandwidth selection, and centering choices on matching and retrieval is not ablated; it is unclear which configurations maximize robustness across domains and languages.
- Normalization strategies beyond “stretching”: The proposed variance-based feature scaling (“stretching”) is only compared to a correlation-based baseline; missing comparisons to whitening, PCA, ZCA, learned normalizations, and Procrustes scaling that could further stabilize cross-space matching.
- Alternative representation similarity measures: The paper does not benchmark CKA against SVCCA, PWCCA, Procrustes similarity, or distance correlation to determine which measure best supports zero-shot cross-modal matching and retrieval.
- Stronger baselines for zero-shot alignment: Beyond linear regression and relative representations, orthogonal Procrustes alignment (using base seeds), ridge/L2-regularized mappings, or manifold alignment techniques are not evaluated as training-free baselines.
- Robustness to noise and adversarial perturbations: No experiments assess how input noise, mislabeled captions, adversarial examples, or corrupted anchors affect CKA-based matching/retrieval and whether the methods degrade gracefully.
- Partial or non-paired datasets: The approach presumes correct base pairs and uses shuffled pairs for queries; performance on datasets with unknown pairing structure (e.g., many-to-many, multi-caption per image, or non-paired corpora) is untested.
- Scalability and memory constraints: Computing and storing N×N kernels limits scalability; there is no empirical assessment of runtime/memory on larger N, nor evaluation of kernel approximation (e.g., Nyström, random features) or streaming algorithms to scale beyond thousands of samples.
- GPU acceleration and algorithmic engineering: The QAP runs on CPU; practical GPU/CUDA implementations, batched local-CKA computation, and incremental graph updates are noted as possible but not realized or measured.
- Generalization across tasks: Evaluation is limited to caption matching/retrieval and ImageNet-100 classification; it remains unknown whether the approach benefits VQA, dense prediction (segmentation/detection), video-language tasks, or compositional reasoning.
- Multilingual coverage and fairness: Cross-lingual experiments use a single multilingual sentence transformer; the paper does not quantify performance across diverse language families, scripts, tokenization strategies, or low-resource languages, nor analyze fairness or bias.
- Decoder-only LLMs and embedding extraction: The approach excludes decoder-only models (e.g., GPT) due to “global embedding” challenges; it is an open question how to extract meaningful sentence-level embeddings (e.g., pooled hidden states) and whether CKA-based alignment works for LLMs.
- Model diversity and representational breadth: Most results hinge on a single language encoder (all-roberta-large-v1) and a few vision encoders; broader testing across encoders (e.g., E5, GTE, LaBSE; ResNet, Swin, SAM, SigLIP, EVA-CLIP) is missing to validate generality.
- Domain shift and out-of-distribution behavior: Aside from COCO→NoCaps, the method’s resilience to larger domain shifts (e.g., medical, satellite, sketch, or synthetic domains) and to out-of-distribution samples is not assessed.
- Failure mode analysis: The paper lacks qualitative/quantitative analyses of mismatches (e.g., object vs. attribute errors, relational semantics, long captions, negations), making it difficult to pinpoint where CKA-based matching fails and how to remedy it.
- Metrics and statistical rigor: Results are averaged over three seeds but without error bars, confidence intervals, or significance tests; standard retrieval metrics (Recall@k, MRR, MAP) and per-language variance are not consistently reported.
- Many-to-one and one-to-many scenarios: How the approach handles multiple captions per image (beyond selecting one) or multiple images per caption is not studied, including the effect of averaging text embeddings vs. structured aggregation.
- Influence of embedding dimension mismatch: Although CKA is kernel-based, the effect of d1≠d2 (dimension mismatch), layer choice within encoders (e.g., earlier vs. later layers), and CLS vs. mean pooling on alignment quality is not analyzed.
- Practical deployment considerations: Guidance on choosing base seeds, tuning hyperparameters, and handling multilingual edge cases (e.g., transliteration, mixed scripts, code-switching) to turn an English-only CLIP-V into multilingual CLIP-like systems is not provided.
- Relationship between high CKA and downstream utility: The paper assumes high CKA indicates usable semantic alignment, yet a deeper investigation into when high CKA translates (or fails to translate) into downstream performance gains is missing.
- Unified framework for matching and retrieval: It remains open how to unify global QAP matching and local CKA retrieval into a single coherent objective or pipeline with consistent performance guarantees and tunable trade-offs.
- Extending beyond text-image: The applicability of the approach to other modality pairs (e.g., audio-text, 3D-text, time-series-text) and to tri-modal setups (image–text–audio) is unexplored.
- Ethical and bias implications: Aligning uncurated language and vision representations could amplify biases; the paper does not examine bias transfer, mitigation strategies, or auditing procedures for multilingual deployment.
Glossary
- ALIGN: A large-scale vision-LLM trained with noisy text supervision to align images and text in a joint embedding space. "The recent success of deep learning on vision-language tasks mainly relies on jointly trained language and image encoders following the success of CLIP and ALIGN"
- Block-diagonal matrix: A square matrix composed of smaller square matrices along its diagonal, used to represent seeded structure in matching formulations. "stands for the block-diagonal matrix having diagonal blocks P_M and P_N"
- Canonical Correlation Analysis (CCA): A statistical method that measures linear relationships between two multivariate sets; often used to compare representations but is invariant to invertible linear transforms. "The CKA measure mitigates the limitation of canonical correlation analysis (CCA) being invariant to an invertible linear transformation"
- Centered Kernel Alignment (CKA): A similarity metric between representation spaces computed from centered kernels via HSIC, robust to isotropic scaling and orthogonal transforms. "Centered Kernel Alignment (CKA) has shown its relevance in understanding and comparing the information encoded by different layers of a neural network"
- Centring matrix: A matrix used to center data (remove mean) before kernel computations in CKA/HSIC. "with H = I − 1/N 11⊤ the centring matrix"
- CLIP: A contrastively trained text-image model that learns a joint embedding space enabling cross-modal retrieval via cosine similarity. "Aligned text-image encoders such as CLIP have become the de-facto model for vision-language tasks"
- Contrastive loss: A training objective that pulls matching pairs together and pushes non-matching pairs apart in embedding space. "aligning text and image representation using a contrastive loss that maximizes the similarity between image-text pairs while pushing negative captions away"
- ConvNeXt: A convolutional neural network architecture modernized for strong image representation performance. "The experimental setup covers vision encoders of different architectures, such as ViTs and ConvNeXt"
- Cross-domain: Tasks where training (or base) data and query data come from different distributions or datasets. "Caption matching and retrieval task performance comparison in cross-domain and in-domain settings"
- Cross-lingual: Tasks that involve matching or retrieval across different languages. "Finally, we show a practical application of our method on cross-lingual image retrieval"
- Cross-modal: Tasks or methods operating across different data modalities (e.g., image and text). "retrieving the closest cross-modal representations using cosine similarity"
- Decoder-only models: LLMs that generate outputs using only a decoder stack, typically lacking a straightforward global sentence embedding. "It's not straightforward to acquire a global sentence embedding from decoder-only models like GPT models"
- DINOv2: A self-supervised vision transformer framework yielding semantically rich visual embeddings without language supervision. "The DINOv2 model, trained solely through self-supervision, demonstrates the formation of semantic concepts"
- Graph matching: The problem of finding a correspondence between nodes of two graphs that optimizes a similarity objective. "In principle, maximizing the above objective is a relaxation of a graph-matching problem"
- Hilbert-Schmidt Independence Criterion (HSIC): A kernel-based dependence measure used to compute CKA between two sets of representations. "where hsic(·, ·) is the Hilbert-Schmidt Independence Criterion"
- Jonker-Volgenant algorithm: An efficient algorithm for solving the linear sum assignment problem. "we make use of SciPy's modified Jonker-Volgenant algorithm for linear sum assignment"
- Kernel CKA: The CKA computed from kernel matrices over embeddings, used to quantify representation similarity. "Kernel CKA and QAP Matching accuracy are correlated with the training set size and quality of the training set"
- Linear sum assignment: The optimization problem of assigning items to targets to minimize total cost; solvable by algorithms like Hungarian/Jonker-Volgenant. "allows for the use of linear sum assignment for matching tasks"
- Local CKA: A localized variant of CKA that evaluates how adding a candidate pair changes global alignment, enabling retrieval and matching. "We propose a local CKA metric and use it to perform retrieval between two unaligned embedding spaces"
- Masked language modeling: A pretraining objective where tokens are masked and predicted, used to learn sentence encoders. "each sentence transformer is first pre-trained on the masked language modeling task using a large text corpus"
- Model stitching: A technique that swaps and connects parts of different neural networks via trainable layers to test representation compatibility. "utilizing model stitching, which introduces trainable stitching layers to enable swapping parts of different networks"
- Permutation matrix: A square binary matrix that reorders indices; used to represent permutations in QAP-based matching. "P_N is the set of all permutation matrices of size N"
- Procrustes similarity: A measure derived from Procrustes analysis to compare shapes/embeddings after optimal linear alignment. "utilizes CKA along with Procrustes similarity for understanding the ability of variational autoencoders (VAEs) in learning disentangled representations"
- Quadratic Assignment Problem (QAP): A combinatorial optimization problem matching two graphs by maximizing a quadratic objective; NP-hard. "a Fast Quadratic Assignment Problem optimization"
- RBF kernel: A radial basis function kernel used in kernel methods to measure similarity in feature space. "e.g., linear or RBF kernels"
- Relative representations: Embeddings expressed as similarities to a shared anchor set, enabling communication across unaligned spaces. "Relative representations enable latent space communication between unaligned encoders by representing each query point relative to an aligned base set"
- Seeded graph-matching: Graph matching augmented with known correspondences (“seeds”) to guide and improve alignment. "We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs"
- Self-supervised learning (SSL): Learning signal derived from the data itself without explicit labels, e.g., via pretext tasks. "trained solely through self-supervision"
- Sentence transformer: A language encoder that produces fixed-length sentence embeddings, typically pretrained and then contrastively finetuned. "The Huggingface's sentence-transformers library is utilized"
- Soft prompts: Learnable vectors prepended to inputs to condition a LLM without full finetuning. "in the form of soft prompts"
- Stretching matrix: A diagonal rescaling matrix (by inverse standard deviation per feature) to normalize and spread embeddings before kernel computation. "we introduce a stretching matrix that normalizes the features of each dimension by the variance calculated from the query and base sets"
- Vision Transformer (ViT): A transformer-based image encoder that operates on patches, widely used for visual representation learning. "such as ViTs and ConvNeXt"
- VQA (Visual Question Answering): A task requiring models to answer questions about images using visual and linguistic understanding. "exhibit impressive performance on image captioning and VQA tasks"
- Wordnet synsets: Sets of cognitive synonyms in WordNet representing a concept, often used with lemmas, definitions, and hypernyms for class text. "Wordnet synsets' lemmas, definitions, and hypernyms"
- Zero-shot: Performing a task without task-specific training by leveraging generalizable representations or alignment. "is there a way to connect them in a zero-shot manner?"
Collections
Sign up for free to add this paper to one or more collections.

