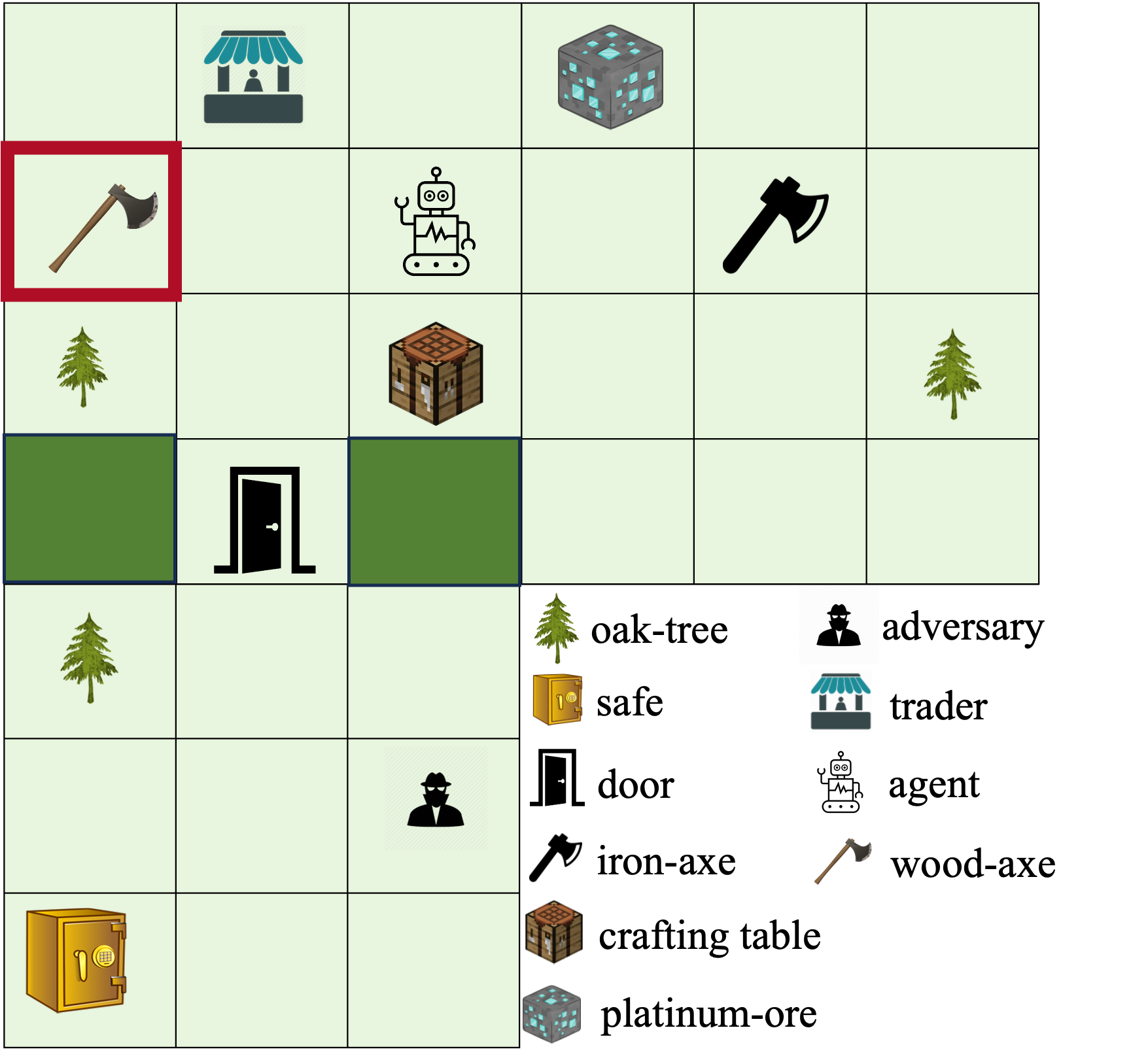
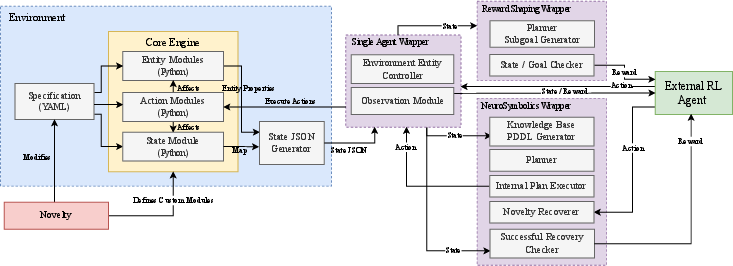
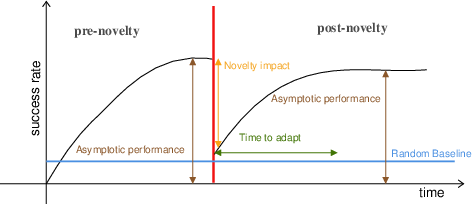
NovelGym: A Flexible Ecosystem for Hybrid Planning and Learning Agents Designed for Open Worlds
Abstract: As AI agents leave the lab and venture into the real world as autonomous vehicles, delivery robots, and cooking robots, it is increasingly necessary to design and comprehensively evaluate algorithms that tackle the ``open-world''. To this end, we introduce NovelGym, a flexible and adaptable ecosystem designed to simulate gridworld environments, serving as a robust platform for benchmarking reinforcement learning (RL) and hybrid planning and learning agents in open-world contexts. The modular architecture of NovelGym facilitates rapid creation and modification of task environments, including multi-agent scenarios, with multiple environment transformations, thus providing a dynamic testbed for researchers to develop open-world AI agents.
- Pddl— the planning domain definition language. Technical Report, Tech. Rep. (1998).
- Novgrid: A flexible grid world for evaluating agent response to novelty. arXiv preprint arXiv:2203.12117 (2022).
- Neuro-Symbolic World Models for Adapting to Open World Novelty. arXiv preprint arXiv:2301.06294 (2023).
- Weibull-Open-World (WOW) Multi-Type Novelty Detection in CartPole3D. Algorithms 15, 10 (2022), 381.
- Openai gym. arXiv preprint arXiv:1606.01540 (2016).
- Characterizing Novelty in the Military Domain. arXiv preprint arXiv:2302.12314 (2023).
- Robot task planning and situation handling in open worlds. arXiv preprint arXiv:2210.01287 (2022).
- RAPid-Learn: A Framework for Learning to Recover for Handling Novelties in Open-World Environments. In IEEE International Conference on Development and Learning, ICDL 2022, London, United Kingdom, September 12-15, 2022. IEEE, 15–22. https://doi.org/10.1109/ICDL53763.2022.9962230
- RAPid-Learn: A Framework for Learning to Recover for Handling Novelties in Open-World Environments.. In 2022 IEEE International Conference on Development and Learning (ICDL). IEEE, 15–22.
- Novelgridworlds: A benchmark environment for detecting and adapting to novelties in open worlds. In AAMAS Adaptive Learning Agents (ALA) Workshop.
- Jörg Hoffmann. 2003. The Metric-FF Planning System: Translating“Ignoring Delete Lists”to Numeric State Variables. Journal of artificial intelligence research 20 (2003), 291–341.
- Learning reward machines: A study in partially observable reinforcement learning. Artificial Intelligence 323 (2023), 103989.
- Towards continual reinforcement learning: A review and perspectives. Journal of Artificial Intelligence Research 75 (2022), 1401–1476.
- Model-Based Novelty Adaptation for Open-World AI. In International Workshop on Principles of Diagnosis (DX).
- Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. Advances in neural information processing systems 29 (2016).
- A novelty-centric agent architecture for changing worlds. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems. 925–933.
- Fabio Pardo. 2020. Tonic: A deep reinforcement learning library for fast prototyping and benchmarking. arXiv preprint arXiv:2011.07537 (2020).
- Curiosity-driven exploration by self-supervised prediction. In International conference on machine learning. PMLR, 2778–2787.
- Spotter: Extending symbolic planning operators through targeted reinforcement learning. arXiv preprint arXiv:2012.13037 (2020).
- Vasanth Sarathy and Matthias Scheutz. 2018. MacGyver Problems: AI Challenges for Testing Resourcefulness and Creativity. Advances in Cognitive Systems 6 (2018). https://hrilab.tufts.edu/publications/sarathy2018MacGyverACS.pdf
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017).
- Tom Silver and Rohan Chitnis. 2020. PDDLGym: Gym environments from PDDL problems. arXiv preprint arXiv:2002.06432 (2020).
- Model-Based Adaptation to Novelty for Open-World AI. In Proceedings of the ICAPS Workshop on Bridging the Gap Between AI Planning and Learning.
- Pettingzoo: Gym for multi-agent reinforcement learning. Advances in Neural Information Processing Systems 34 (2021), 15032–15043.
- Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv preprint arXiv:2302.01560 (2023).
- Tianshou: A Highly Modularized Deep Reinforcement Learning Library. Journal of Machine Learning Research 23, 267 (2022), 1–6. http://jmlr.org/papers/v23/21-1127.html
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

