Metalearning Continual Learning Algorithms
Abstract: General-purpose learning systems should improve themselves in open-ended fashion in ever-changing environments. Conventional learning algorithms for neural networks, however, suffer from catastrophic forgetting (CF), i.e., previously acquired skills are forgotten when a new task is learned. Instead of hand-crafting new algorithms for avoiding CF, we propose Automated Continual Learning (ACL) to train self-referential neural networks to metalearn their own in-context continual (meta)learning algorithms. ACL encodes continual learning (CL) desiderata -- good performance on both old and new tasks -- into its metalearning objectives. Our experiments demonstrate that ACL effectively resolves "in-context catastrophic forgetting," a problem that naive in-context learning algorithms suffer from; ACL-learned algorithms outperform both hand-crafted learning algorithms and popular meta-continual learning methods on the Split-MNIST benchmark in the replay-free setting, and enables continual learning of diverse tasks consisting of multiple standard image classification datasets. We also discuss the current limitations of in-context CL by comparing ACL with state-of-the-art CL methods that leverage pre-trained models. Overall, we bring several novel perspectives into the long-standing problem of CL.
- Theoretical foundations of potential function method in pattern recognition. Automation and Remote Control, 25(6):917–936, 1964.
- What learning algorithm is in-context learning? investigations with linear models. In Int. Conf. on Learning Representations (ICLR), Kigali, Rwanda, May 2023.
- Memory aware synapses: Learning what (not) to forget. In Proc. European Conf. on Computer Vision (ECCV), pp. 144–161, Munich, Germany, September 2018.
- Generative vs. discriminative: Rethinking the meta-continual learning. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 21592–21604, Virtual only, December 2021.
- Learning to continually learn. In Proc. European Conf. on Artificial Intelligence (ECAI), pp. 992–1001, August 2020.
- Tom Bosc. Learning to learn neural networks. In NIPS Workshop on Reasoning, Attention, Memory, Montreal, Canada, December 2015.
- TaskNorm: Rethinking batch normalization for meta-learning. In Proc. Int. Conf. on Machine Learning (ICML), pp. 1153–1164, Virtual only, 2020.
- Tom B Brown et al. Language models are few-shot learners. In Proc. Advances in Neural Information Processing Systems (NeurIPS), Virtual only, December 2020.
- Online fast adaptation and knowledge accumulation (OSAKA): a new approach to continual learning. In Proc. Advances in Neural Information Processing Systems (NeurIPS), Virtual only, December 2020.
- Rich Caruana. Multitask learning. Machine learning, 28:41–75, 1997.
- Transformers generalize differently from information stored in context vs in weights. In NeurIPS Workshop on Memory in Artificial and Real Intelligence (MemARI), New Orleans, LA, USA, November 2022a.
- Data distributional properties drive emergent in-context learning in transformers. In Proc. Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, November 2022b.
- Rethinking attention with performers. In Int. Conf. on Learning Representations (ICLR), Virtual only, 2021.
- Meta-in-context learning in large language models. Preprint arXiv:2305.12907, 2023.
- Fixed-weight networks can learn. In Proc. Int. Joint Conf. on Neural Networks (IJCNN), pp. 553–559, San Diego, CA, USA, June 1990.
- Learning algorithms and fixed dynamics. In Proc. Int. Joint Conf. on Neural Networks (IJCNN), pp. 799–801, Seattle, WA, USA, July 1991.
- The devil is in the detail: Simple tricks improve systematic generalization of transformers. In Proc. Conf. on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, November 2021.
- Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers. In Proc. Findings Association for Computational Linguistics (ACL), pp. 4005–4019, Toronto, Canada, July 2023.
- Torchmeta: A meta-learning library for PyTorch. Preprint arXiv:1909.06576, 2019.
- RL22{}^{2}start_FLOATSUPERSCRIPT 2 end_FLOATSUPERSCRIPT: Fast reinforcement learning via slow reinforcement learning. Preprint arXiv:1611.02779, 2016.
- David Eagleman. Livewired: The inside story of the ever-changing brain. 2020.
- Meta-learning and universality: Deep representations and gradient descent can approximate any learning algorithm. In Int. Conf. on Learning Representations (ICLR), Vancouver, Canada, April 2018.
- Model-agnostic meta-learning for fast adaptation of deep networks. In Proc. Int. Conf. on Machine Learning (ICML), pp. 1126–1135, Sydney, Australia, August 2017.
- Connectionism and cognitive architecture: A critical analysis. Cognition, 28(1-2):3–71, 1988.
- Robert M French. Using semi-distributed representations to overcome catastrophic forgetting in connectionist networks. In Proc. Cognitive science society conference, volume 1, pp. 173–178, 1991.
- Robert M French. Catastrophic forgetting in connectionist networks. Trends in cognitive sciences, 3(4):128–135, 1999.
- Automated curriculum learning for neural networks. In Proc. Int. Conf. on Machine Learning (ICML), pp. 1311–1320, Sydney, Australia, August 2017.
- Stephen T Grossberg. Studies of mind and brain: Neural principles of learning, perception, development, cognition, and motor control. Springer, 1982.
- Task agnostic continual learning via meta learning. Preprint arXiv:1906.05201, 2019.
- Learning to learn using gradient descent. In Proc. Int. Conf. on Artificial Neural Networks (ICANN), volume 2130, pp. 87–94, Vienna, Austria, August 2001.
- Re-evaluating continual learning scenarios: A categorization and case for strong baselines. In NeurIPS Workshop on Continual Learning, Montréal, Canada, December 2018.
- Are LSTMs good few-shot learners? Machine Learning, pp. 1–28, 2023.
- Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proc. Int. Conf. on Machine Learning (ICML), pp. 448–456, Lille, France, July 2015.
- Accelerating neural self-improvement via bootstrapping. In ICLR Workshop on Mathematical and Empirical Understanding of Foundation Models, Kigali, Rwanda, May 2023a.
- Images as weight matrices: Sequential image generation through synaptic learning rules. In Int. Conf. on Learning Representations (ICLR), Kigali, Rwanda, May 2023b.
- Going beyond linear transformers with recurrent fast weight programmers. In Proc. Advances in Neural Information Processing Systems (NeurIPS), Virtual only, December 2021a.
- Improving baselines in the wild. In Workshop on Distribution Shifts, NeurIPS, Virtual only, 2021b.
- The dual form of neural networks revisited: Connecting test time predictions to training patterns via spotlights of attention. In Proc. Int. Conf. on Machine Learning (ICML), Baltimore, MD, USA, July 2022a.
- Neural differential equations for learning to program neural nets through continuous learning rules. In Proc. Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, December 2022b.
- A modern self-referential weight matrix that learns to modify itself. In Proc. Int. Conf. on Machine Learning (ICML), pp. 9660–9677, Baltimore, MA, USA, July 2022c.
- Practical computational power of linear transformers and their recurrent and self-referential extensions. In Proc. Conf. on Empirical Methods in Natural Language Processing (EMNLP), Sentosa, Singapore, 2023.
- Meta-learning representations for continual learning. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 1818–1828, Vancouver, BC, Canada, December 2019.
- Transformers are RNNs: Fast autoregressive transformers with linear attention. In Proc. Int. Conf. on Machine Learning (ICML), Virtual only, July 2020.
- Overcoming catastrophic forgetting in neural networks. Proc. National academy of sciences, 114(13):3521–3526, 2017.
- Meta learning backpropagation and improving it. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 14122–14134, Virtual only, December 2021.
- General-purpose in-context learning by meta-learning transformers. In NeurIPS Workshop on Memory in Artificial and Real Intelligence (MemARI), New Orleans, LA, USA, November 2022.
- Chris A Kortge. Episodic memory in connectionist networks. In 12th Annual Conference. CSS Pod, pp. 764–771, 1990.
- Alex Krizhevsky. Learning multiple layers of features from tiny images. Master’s thesis, Computer Science Department, University of Toronto, 2009.
- Human-level concept learning through probabilistic program induction. Science, 350(6266):1332–1338, 2015.
- The MNIST database of handwritten digits. URL http://yann. lecun. com/exdb/mnist, 1998.
- Learning without forgetting. In Proc. European Conf. on Computer Vision (ECCV), pp. 614–629, Amsterdam, Netherlands, October 2016.
- Gradient episodic memory for continual learning. In Proc. Advances in Neural Information Processing Systems (NIPS), pp. 6467–6476, Long Beach, CA, USA, December 2017.
- Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological review, 102(3):419, 1995.
- Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pp. 109–165. 1989.
- Differentiable plasticity: training plastic neural networks with backpropagation. In Proc. Int. Conf. on Machine Learning (ICML), pp. 3559–3568, Stockholm, Sweden, July 2018.
- Backpropamine: training self-modifying neural networks with differentiable neuromodulated plasticity. In Int. Conf. on Learning Representations (ICLR), New Orleans, LA, USA, May 2019.
- Rethinking the role of demonstrations: What makes in-context learning work? In Proc. Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 11048–11064, Abu Dhabi, UAE, December 2022.
- A simple neural attentive meta-learner. In Int. Conf. on Learning Representations (ICLR), Vancouver, Cananda, 2018.
- Metalearning with Hebbian fast weights. Preprint arXiv:1807.05076, 2018.
- Meta networks. In Proc. Int. Conf. on Machine Learning (ICML), pp. 2554–2563, Sydney, Australia, August 2017.
- Metalearned neural memory. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 13310–13321, Vancouver, Canada, December 2019.
- Meta-neural networks that learn by learning. In Proc. International Joint Conference on Neural Networks (IJCNN), volume 1, pp. 437–442, Baltimore, MD, USA, June 1992.
- TADAM: task dependent adaptive metric for improved few-shot learning. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 719–729, Montréal, Canada, December 2018.
- Random feature attention. In Int. Conf. on Learning Representations (ICLR), Virtual only, 2021.
- Language models are unsupervised multitask learners. [Online]. : https://blog.openai.com/better-language-models/, 2019.
- Roger Ratcliff. Connectionist models of recognition memory: constraints imposed by learning and forgetting functions. Psychological review, 97(2):285, 1990.
- Optimization as a model for few-shot learning. In Int. Conf. on Learning Representations (ICLR), Toulon, France, April 2017.
- Fast and flexible multi-task classification using conditional neural adaptive processes. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 7957–7968, Vancouver, Canada, December 2019.
- Learning to learn without forgetting by maximizing transfer and minimizing interference. In Int. Conf. on Learning Representations (ICLR), New Orleans, LA, USA, May 2019.
- Mark B. Ring. Continual Learning in Reinforcement Environments. PhD thesis, University of Texas at Austin, Austin, TX, USA, 1994.
- Anthony Robins. Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science, 7(2):123–146, 1995.
- Experience replay for continual learning. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 348–358, Vancouver, Canada, December 2019.
- Progressive neural networks. Preprint arXiv:1606.04671, 2016.
- Meta-learning bidirectional update rules. In Proc. Int. Conf. on Machine Learning (ICML), pp. 9288–9300, Virtual only, July 2021.
- Meta-learning with memory-augmented neural networks. In Proc. Int. Conf. on Machine Learning (ICML), pp. 1842–1850, New York City, NY, USA, June 2016.
- Linear Transformers are secretly fast weight programmers. In Proc. Int. Conf. on Machine Learning (ICML), Virtual only, July 2021.
- Jürgen Schmidhuber. Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-… hook. PhD thesis, Technische Universität München, 1987.
- Jürgen Schmidhuber. Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Institut für Informatik, Technische Universität München. Technical Report FKI-126, 90, 1990.
- Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Technical Report FKI-147-91, Institut für Informatik, Technische Universität München, March 1991.
- Jürgen Schmidhuber. Steps towards “self-referential” learning. Technical Report CU-CS-627-92, Dept. of Comp. Sci., University of Colorado at Boulder, November 1992a.
- Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4(1):131–139, 1992b.
- Jürgen Schmidhuber. A self-referential weight matrix. In Proc. Int. Conf. on Artificial Neural Networks (ICANN), pp. 446–451, Amsterdam, Netherlands, September 1993.
- Jürgen Schmidhuber. On learning how to learn learning strategies. Technical Report FKI-198-94, Institut für Informatik, Technische Universität München, November 1994.
- Jürgen Schmidhuber. Beyond “genetic programming”: Incremental self-improvement. In Proc. Workshop on Genetic Programming at ML95, pp. 42–49, 1995.
- Jürgen Schmidhuber. One big net for everything. Preprint arXiv:1802.08864, 2018.
- Shifting inductive bias with success-story algorithm, adaptive Levin search, and incremental self-improvement. Machine Learning, 28(1):105–130, 1997.
- Progress & compress: A scalable framework for continual learning. In Proc. Int. Conf. on Machine Learning (ICML), pp. 4535–4544, Stockholm, Sweden, July 2018.
- Continual learning with deep generative replay. In Proc. Advances in Neural Information Processing Systems (NIPS), pp. 2990–2999, Long Beach, CA, USA, December 2017.
- Compete to compute. In Proc. Advances in Neural Information Processing Systems (NIPS), pp. 2310–2318, Lake Tahoe, NV, USA, December 2013.
- Sebastian Thrun. Lifelong learning algorithms. In Learning to learn, pp. 181–209. 1998.
- MLP-Mixer: An all-MLP architecture for vision. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 24261–24272, Virtual only, December 2021.
- Meta-dataset: A dataset of datasets for learning to learn from few examples. In Int. Conf. on Learning Representations (ICLR), Addis Ababa, Ethiopia, April 2020.
- Instance normalization: The missing ingredient for fast stylization. Preprint arXiv:1607.08022, 2016.
- Gido M Van de Ven and Andreas S Tolias. Generative replay with feedback connections as a general strategy for continual learning. Preprint arXiv:1809.10635, 2018a.
- Gido M Van de Ven and Andreas S Tolias. Three scenarios for continual learning. In NeurIPS Workshop on Continual Learning, Montréal, Canada, December 2018b.
- Attention is all you need. In Proc. Advances in Neural Information Processing Systems (NIPS), pp. 5998–6008, Long Beach, CA, USA, December 2017.
- Efficient continual learning with modular networks and task-driven priors. In Int. Conf. on Learning Representations (ICLR), Virtual only, May 2021.
- Matching networks for one shot learning. In Proc. Advances in Neural Information Processing Systems (NIPS), pp. 3630–3638, Barcelona, Spain, December 2016.
- Transformers learn in-context by gradient descent. In Proc. Int. Conf. on Machine Learning (ICML), Honolulu, HI, USA, July 2023a.
- Uncovering mesa-optimization algorithms in Transformers. Preprint arXiv:2309.05858, 2023b.
- Learning to reinforcement learn. In Proc. Annual Meeting of the Cognitive Science Society (CogSci), London, UK, July 2017.
- Adaptive switching circuits. In Proc. IRE WESCON Convention Record, pp. 96–104, Los Angeles, CA, USA, August 1960.
- Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms. Preprint arXiv:1708.07747, 2017.
- An explanation of in-context learning as implicit bayesian inference. In Int. Conf. on Learning Representations (ICLR), Virtual only, April 2022.
- Addressing catastrophic forgetting in few-shot problems. In Proc. Int. Conf. on Machine Learning (ICML), pp. 11909–11919, Virtual only, July 2021.
- Ground-truth labels matter: A deeper look into input-label demonstrations. In Proc. Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 2422–2437, Abu Dhabi, UAE, December 2022.
- Fixed-weight on-line learning. IEEE Transactions on Neural Networks, 10(2):272–283, 1999.
- Continual learning through synaptic intelligence. In Proc. Int. Conf. on Machine Learning (ICML), pp. 3987–3995, Sydney, Australia, August 2017.
- A simple but strong baseline for online continual learning: Repeated augmented rehearsal. In Proc. Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, December 2022.
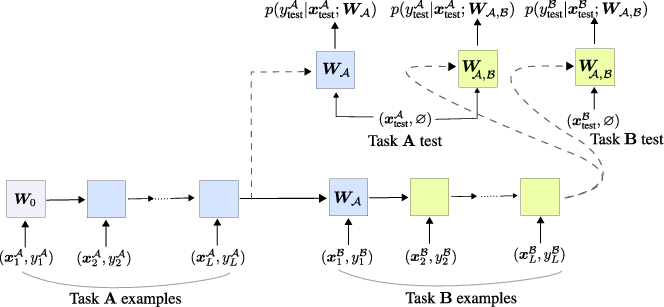
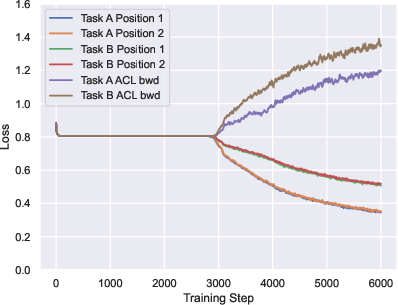
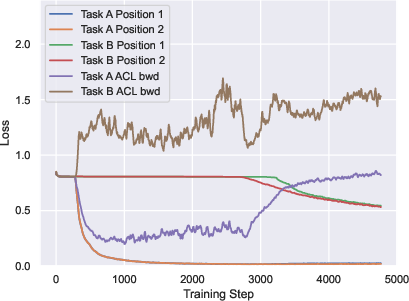

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.