CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
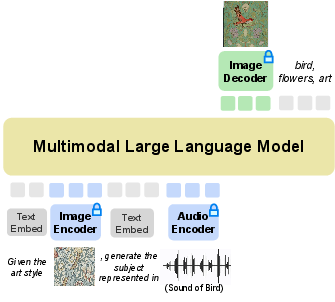
Abstract: We present CoDi-2, a versatile and interactive Multimodal LLM (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers LLMs to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
- Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1728–1738, 2021.
- Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023.
- Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491, 2022.
- Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021.
- Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- Audio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 776–780. IEEE, 2017.
- Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Reversion: Diffusion-based relation inversion from images. arXiv preprint arXiv:2303.13495, 2023.
- Generating images with multimodal language models. arXiv preprint arXiv:2305.17216, 2023.
- Multi-concept customization of text-to-image diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1931–1941, 2023.
- The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International Journal of Computer Vision, 128(7):1956–1981, 2020.
- Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a.
- Audioldm 2: Learning holistic audio generation with self-supervised pretraining. arXiv preprint arXiv:2308.05734, 2023b.
- Chameleon: Plug-and-play compositional reasoning with large language models. arXiv preprint arXiv:2304.09842, 2023.
- Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073, 2021.
- OpenAI. Gpt-4 technical report, 2023.
- Kosmos-g: Generating images in context with multimodal large language models. arXiv preprint arXiv:2310.02992, 2023a.
- Kosmos-g: Generating images in context with multimodal large language models, 2023b.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500–22510, 2023.
- Laion-400m: Open dataset of clip-filtered 400 million image-text pairs, 2021.
- Generative pretraining in multimodality. arXiv preprint arXiv:2307.05222, 2023.
- Any-to-any generation via composable diffusion. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Stanford alpaca: An instruction-following llama model, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Audit: Audio editing by following instructions with latent diffusion models. arXiv preprint arXiv:2304.00830, 2023a.
- In-context learning unlocked for diffusion models. arXiv preprint arXiv:2305.01115, 2023b.
- The generative ai paradox:” what it can create, it may not understand”. arXiv preprint arXiv:2311.00059, 2023.
- Next-gpt: Any-to-any multimodal llm. arXiv preprint arXiv:2309.05519, 2023.
- i-code: An integrative and composable multimodal learning framework. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 10880–10890, 2023.
- mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- Ferret: Refer and ground anything anywhere at any granularity, 2023.
- Merlot reserve: Neural script knowledge through vision and language and sound. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16375–16387, 2022.
- Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
- A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Minigpt-5: Interleaved vision-and-language generation via generative vokens. arXiv preprint arXiv:2310.02239, 2023.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

