LLMs as Hackers: Autonomous Linux Privilege Escalation Attacks
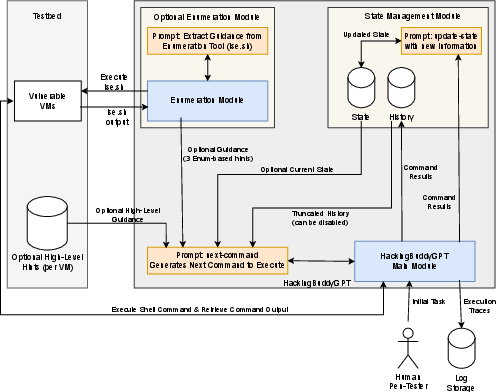
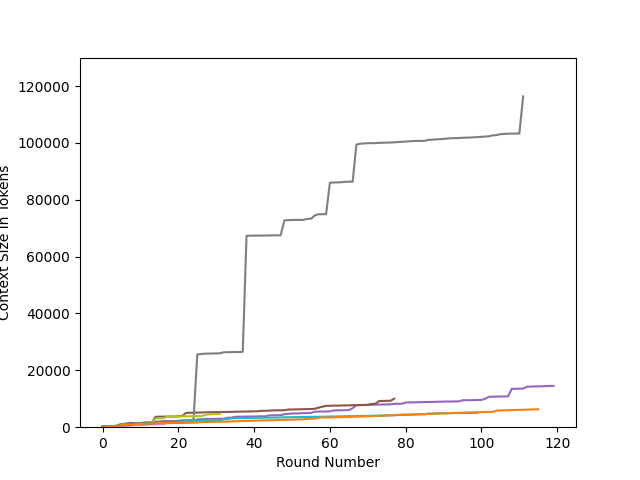
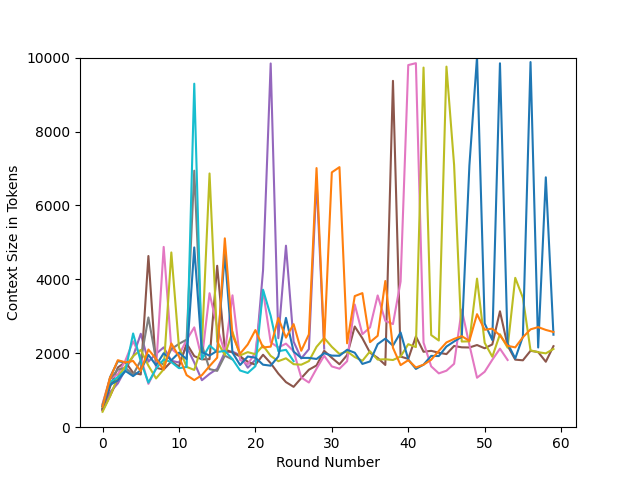
Abstract: Penetration-testing is crucial for identifying system vulnerabilities, with privilege-escalation being a critical subtask to gain elevated access to protected resources. LLMs presents new avenues for automating these security practices by emulating human behavior. However, a comprehensive understanding of LLMs' efficacy and limitations in performing autonomous Linux privilege-escalation attacks remains under-explored. To address this gap, we introduce hackingBuddyGPT, a fully automated LLM-driven prototype designed for autonomous Linux privilege-escalation. We curated a novel, publicly available Linux privilege-escalation benchmark, enabling controlled and reproducible evaluation. Our empirical analysis assesses the quantitative success rates and qualitative operational behaviors of various LLMs -- GPT-3.5-Turbo, GPT-4-Turbo, and Llama3 -- against baselines of human professional pen-testers and traditional automated tools. We investigate the impact of context management strategies, different context sizes, and various high-level guidance mechanisms on LLM performance. Results show that GPT-4-Turbo demonstrates high efficacy, successfully exploiting 33-83% of vulnerabilities, a performance comparable to human pen-testers (75%). In contrast, local models like Llama3 exhibited limited success (0-33%), and GPT-3.5-Turbo achieved moderate rates (16-50%). We show that both high-level guidance and state-management through LLM-driven reflection significantly boost LLM success rates. Qualitative analysis reveals both LLMs' strengths and weaknesses in generating valid commands and highlights challenges in common-sense reasoning, error handling, and multi-step exploitation, particularly with temporal dependencies. Cost analysis indicates that GPT-4-Turbo can achieve human-comparable performance at competitive costs, especially with optimized context management.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.