Autonomous Tree-search Ability of Large Language Models
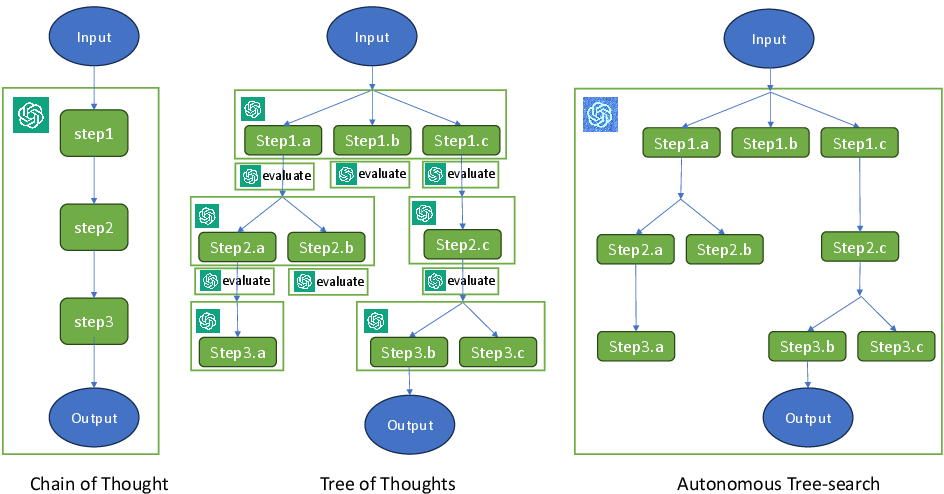
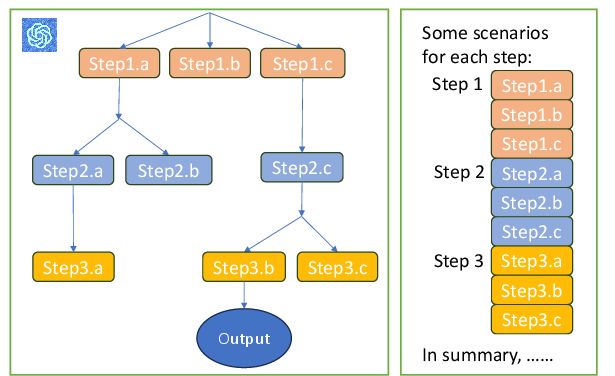
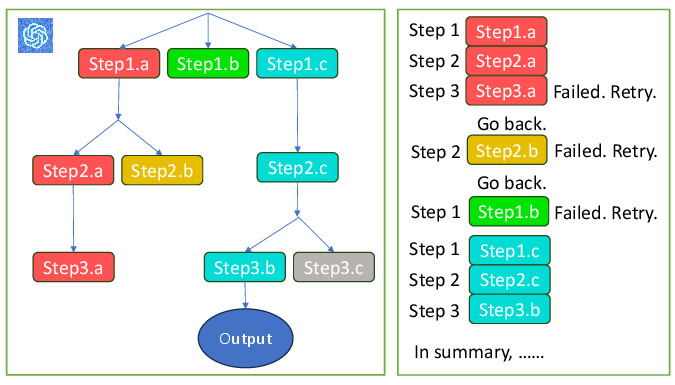
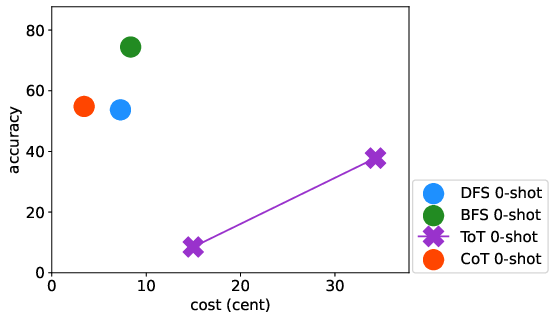
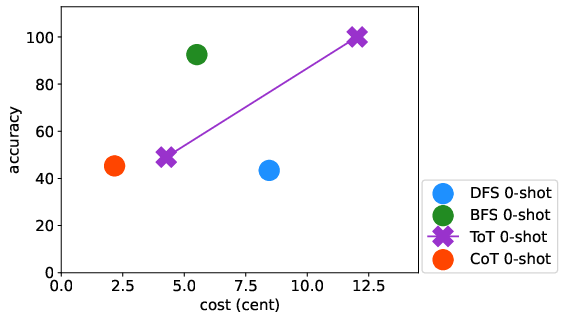
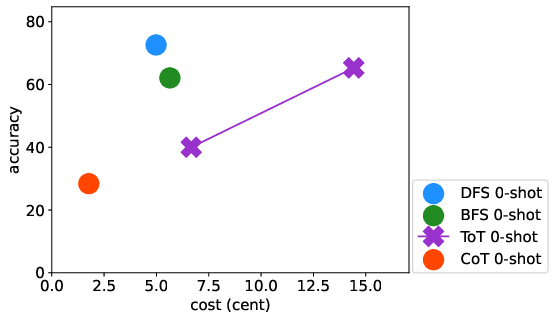
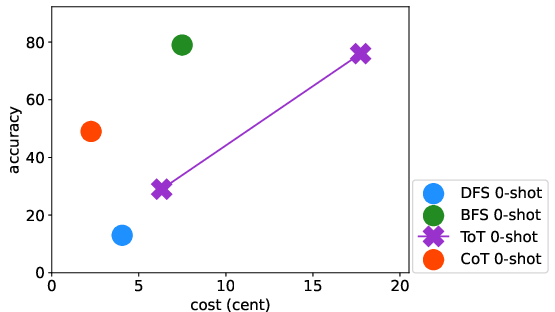
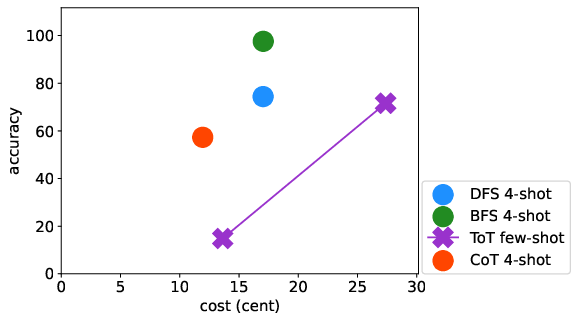
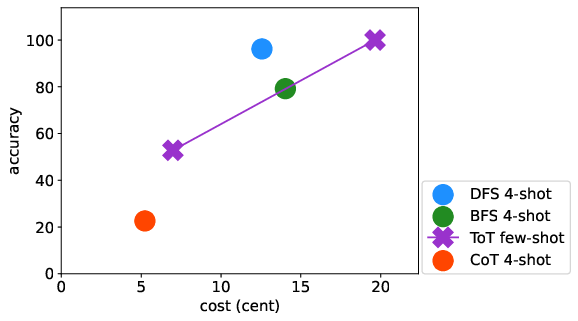
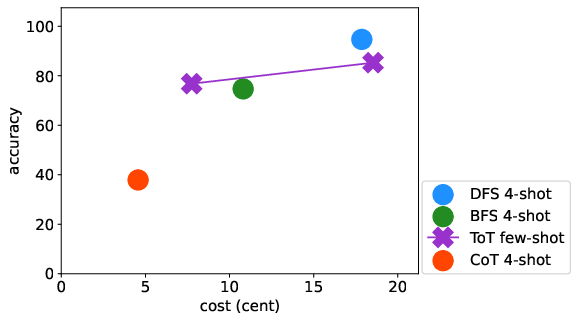
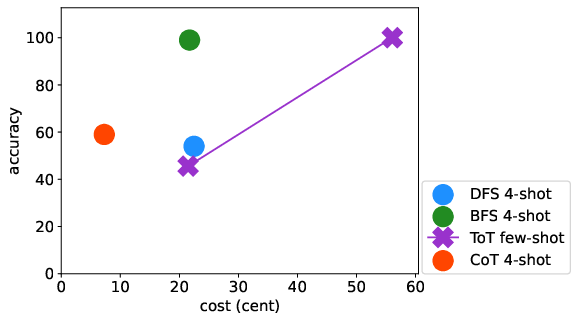
Abstract: LLMs have excelled in remarkable reasoning capabilities with advanced prompting techniques, but they fall short on tasks that require exploration, strategic foresight, and sequential decision-making. Recent works propose to utilize external programs to define search logic, such that LLMs can perform passive tree search to solve more challenging reasoning tasks. Though impressive results have been achieved, there are several fundamental limitations of these approaches. First, passive tree searches are not efficient as they usually require multiple rounds of LLM API calls to solve one single problem. Moreover, passive search methods are not flexible since they need task-specific program designs. Then a natural question arises: can we maintain the tree-search capability of LLMs without the aid of external programs, and can still generate responses that clearly demonstrate the process of a tree-structure search? To this end, we propose a new concept called autonomous tree-search ability of LLM, which can automatically generate a response containing search trajectories for the correct answer. Concretely, we perform search trajectories using capable LLM API via a fixed system prompt, allowing them to perform autonomous tree-search (ATS) right out of the box. Experiments on 4 puzzle games demonstrate our method can achieve huge improvements. The ATS-BFS method outperforms the Chain of Thought approach by achieving an average accuracy improvement of 33%. Compared to Tree of Thoughts, it requires 65.6% or 47.7% less GPT-api cost to attain a comparable level of accuracy. Moreover, we have collected data using the ATS prompt method and fine-tuned LLaMA. This approach yield a greater improvement compared to the ones fine-tuned on CoT data. Specifically, it outperforms CoT-tuned LLaMAs by an average of 40.6% and 38.5% for LLaMA2-7B and LLaMA2-13B, respectively.
- Graph of thoughts: Solving elaborate problems with large language models. arXiv preprint arXiv:2308.09687, 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Frugalgpt: How to use large language models while reducing cost and improving performance. arXiv preprint arXiv:2305.05176, 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Payal Dhar. The carbon impact of artificial intelligence. Nat. Mach. Intell., 2(8):423–425, 2020.
- A neural network solves, explains, and generates university math problems by program synthesis and few-shot learning at human level. Proceedings of the National Academy of Sciences, 119(32):e2123433119, 2022.
- Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Gpt is becoming a turing machine: Here are some ways to program it. arXiv preprint arXiv:2303.14310, 2023.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv preprint arXiv:2304.03439, 2023.
- Jieyi Long. Large language model guided tree-of-thought. arXiv preprint arXiv:2305.08291, 2023.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021.
- OpenAI. Gpt-4 technical report, 2023.
- Vicuna: A Timing-Predictable RISC-V Vector Coprocessor for Scalable Parallel Computation. In Björn B. Brandenburg (ed.), 33rd Euromicro Conference on Real-Time Systems (ECRTS 2021), volume 196 of Leibniz International Proceedings in Informatics (LIPIcs), pp. 1:1–1:18, Dagstuhl, Germany, 2021. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. ISBN 978-3-95977-192-4. doi: 10.4230/LIPIcs.ECRTS.2021.1. URL https://drops.dagstuhl.de/opus/volltexte/2021/13932.
- Explain yourself! leveraging language models for commonsense reasoning. arXiv preprint arXiv:1906.02361, 2019.
- Algorithm of thoughts: Enhancing exploration of ideas in large language models. arXiv preprint arXiv:2308.10379, 2023.
- Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937, 2018.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Sustainable ai: Environmental implications, challenges and opportunities. Proceedings of Machine Learning and Systems, 4:795–813, 2022.
- Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- Large language model as autonomous decision maker. arXiv preprint arXiv:2308.12519, 2023.
- Cumulative reasoning with large language models. arXiv preprint arXiv:2308.04371, 2023.
- Teaching algorithmic reasoning via in-context learning. arXiv preprint arXiv:2211.09066, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

