ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
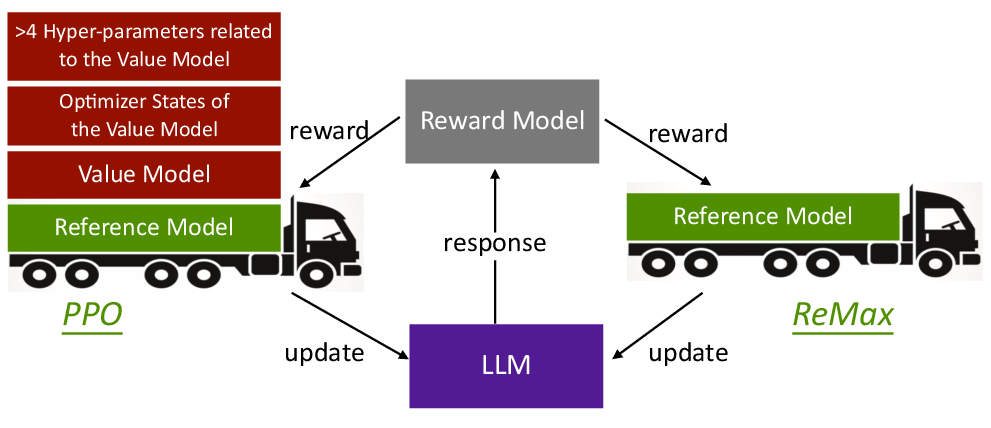
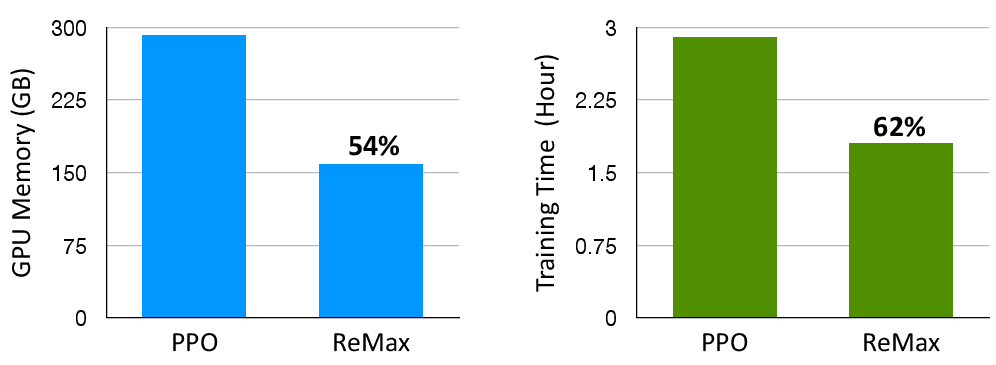
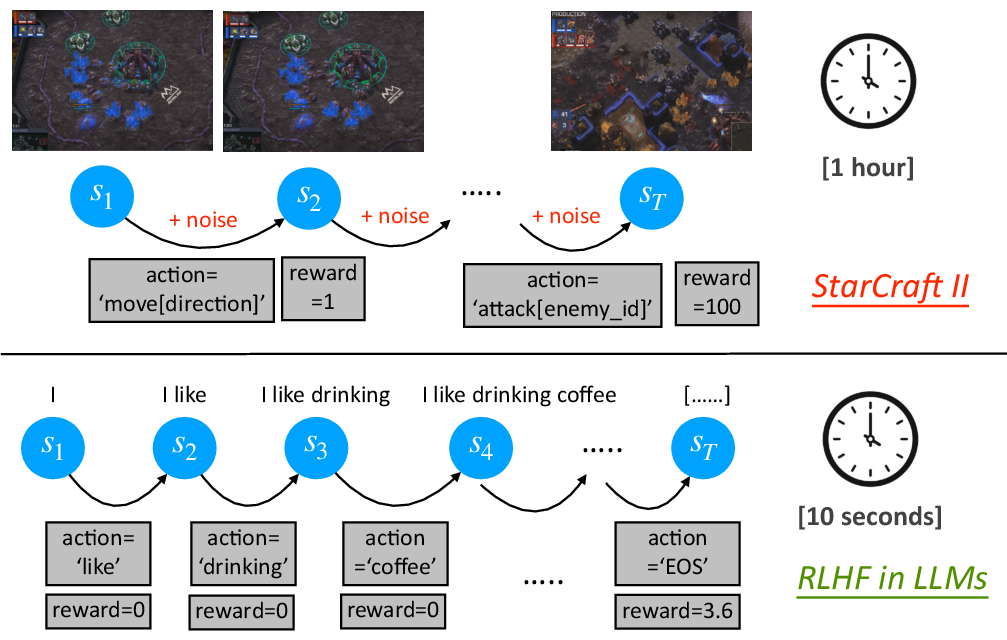
Abstract: Reinforcement Learning from Human Feedback (RLHF) is key to aligning LLMs, typically paired with the Proximal Policy Optimization (PPO) algorithm. While PPO is a powerful method designed for general reinforcement learning tasks, it is overly sophisticated for LLMs, leading to laborious hyper-parameter tuning and significant computation burdens. To make RLHF efficient, we present ReMax, which leverages 3 properties of RLHF: fast simulation, deterministic transitions, and trajectory-level rewards. These properties are not exploited in PPO, making it less suitable for RLHF. Building on the renowned REINFORCE algorithm, ReMax does not require training an additional value model as in PPO and is further enhanced with a new variance reduction technique. ReMax offers several benefits over PPO: it is simpler to implement, eliminates more than 4 hyper-parameters in PPO, reduces GPU memory usage, and shortens training time. ReMax can save about 46% GPU memory than PPO when training a 7B model and enables training on A800-80GB GPUs without the memory-saving offloading technique needed by PPO. Applying ReMax to a Mistral-7B model resulted in a 94.78% win rate on the AlpacaEval leaderboard and a 7.739 score on MT-bench, setting a new SOTA for open-source 7B models. These results show the effectiveness of ReMax while addressing the limitations of PPO in LLMs.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022a.
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022b.
- M. Bartlett. Approximate confidence intervals. Biometrika, 40(1/2):12–19, 1953.
- On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Language models are few-shot learners. Advances in Neural Information Processing Systems 33, pages 1877–1901, 2020.
- Provably efficient exploration in policy optimization. In Proceedings of the 37th International Conference on Machine Learning, pages 1283–1294, 2020.
- Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217, 2023.
- P. Dayan. Reinforcement comparison. In Connectionist Models, pages 45–51. Elsevier, 1991.
- Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767, 2023.
- Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
- Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv preprint arXiv:2005.12729, 2020.
- Scaling laws for reward model overoptimization. In Proceedings of the 40th International Conference on Machine Learning, pages 10835–10866, 2023.
- Variance reduction techniques for gradient estimates in reinforcement learning. Journal of Machine Learning Research, 5(9), 2004.
- Lora: Low-rank adaptation of large language models. In Proceedings of the 10th International Conference on Learning Representations, 2022.
- Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267, 2023.
- Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
- Monte carlo gradient estimation in machine learning. Journal of Machine Learning Research, 21(132):1–62, 2020.
- OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35, pages 27730–27744, 2022.
- Reward gaming in conditional text generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 4746–4763, 2023.
- M. L. Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, 2014.
- Language models are unsupervised multitask learners. OpenAI blog, 2019.
- Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16, 2020.
- Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. In Proceedings of 11th International Conference on Learning Representations, 2023.
- {{\{{ZeRO-Offload}}\}}: Democratizing {{\{{Billion-Scale}}\}} model training. In Proceedings of the 2021 USENIX Annual Technical Conference, pages 551–564, 2021.
- Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
- Efficient rlhf: Reducing the memory usage of ppo. arXiv preprint arXiv:2309.00754, 2023.
- High-dimensional continuous control using generalized advantage estimation. In Proceedings of the 4th International Conference on Learning Representations, 2016.
- Proximal policy optimization algorithms. arXiv, 1707.06347, 2017.
- Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016.
- A long way to go: Investigating length correlations in rlhf. arXiv preprint arXiv:2310.03716, 2023.
- Defining and characterizing reward gaming. In Advances in Neural Information Processing Systems 35, pages 9460–9471, 2022.
- Low-memory neural network training: A technical report. arXiv preprint arXiv:1904.10631, 2019.
- Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- R. Sutton. Learning to predict by the methods of temporal differences. Machine learning, 3:9–44, 1988.
- Reinforcement Learning: An Introduction. MIT press, 2018.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- L. Weaver and N. Tao. The optimal reward baseline for gradient-based reinforcement learning. In Proceedings of the 17th Conference in Uncertainty in Artificial Intelligence, pages 538–545, 2001.
- R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992.
- Deepspeed-chat: Easy, fast and affordable rlhf training of chatgpt-like models at all scales. arXiv preprint arXiv:2308.01320, 2023.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Secrets of rlhf in large language models part i: Ppo. arXiv preprint arXiv:2307.04964, 2023.
- Principled reinforcement learning with human feedback from pairwise or k-wise comparisons. In Proceedings of the 40th International Conference on Machine Learning, pages 43037–43067, 2023a.
- Fine-tuning language models with advantage-induced policy alignment. arXiv preprint arXiv:2306.02231, 2023b.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

