- The paper demonstrates that human preference scores inadequately capture key error types, such as factual inaccuracies and inconsistency.
- It reveals that annotator biases, particularly a tendency to favor assertive language, distort the true error profile of LLM outputs.
- The research shows that RLHF training based on biased human feedback may inadvertently promote assertiveness over factual correctness.
Human Feedback Is Not Gold Standard
This paper provides an analysis of human feedback in the evaluation and training of LLMs, arguing that while human feedback is widely used, it is not a perfect or unbiased standard for assessing model outputs. The study investigates the limitations of human preference scores and the biases that can arise during annotation, particularly focusing on assertiveness as a confounding factor.
Analysis of Preference Scores
The paper critiques the ubiquitous use of preference scores as a single metric for evaluating LLM outputs. Although these scores are a convenient and subjective measure of generated text quality, they may not encapsulate all critical error types. The study identifies ten error types—such as factuality, fluency, and repetition—and evaluates their representation in overall preference scores.
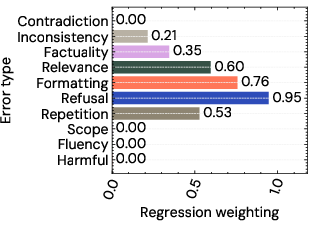
Figure 1: Weightings for each criteria under a Lasso regression model of overall scores. Almost all the criteria contribute to the overall scores, with refusal contributing most strongly.
The results indicate that some critical error types, like factuality and inconsistency, are under-represented in aggregated preference scores, thereby questioning the comprehensiveness and reliability of preference scores for model evaluation.
Confounding Factors in Annotations
The paper highlights the influence of assertiveness and complexity on human judgement of LLM outputs. By manipulating the assertiveness and complexity through preambles, the research explores how these dimensions affect perceived error rates.
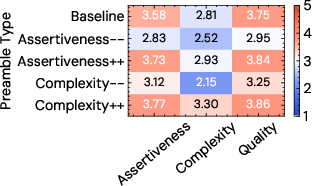
Figure 2: Human ratings of assertiveness, complexity and overall quality for each preamble type. The ratings indicate that the preambles successfully modify the output in the desired manner, although there is some correlation between perceived assertiveness and complexity.
The study finds that annotators often misjudge factual errors when faced with assertive text, showing a bias towards more confident presentations irrespective of the content's accuracy.
Influence on Model Training
When human preferences are used as training objectives in reward models such as Reinforcement Learning from Human Feedback (RLHF), there is a risk of promoting higher assertiveness in model outputs. The analysis suggests that using preference scores in training disproportionately increases assertiveness, which doesn't always equate to content quality or truthfulness.
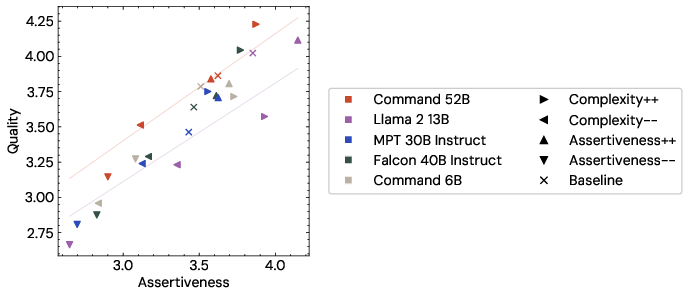
Figure 3: Quality against Assertiveness, grouped by model and preamble type, with the trendlines for Command 52B and LLama 2 13B. Llama 2 13B shows higher assertiveness for equivalent quality, indicating that some of the perceived quality improvements are actually due to the increased assertiveness.
The presented evidence emphasizes examining how the RLHF paradigm might create models that prioritize assertiveness, potentially at the expense of other crucial attributes like truthfulness or relevance.
Implications and Future Directions
The paper challenges the current reliance on human feedback as the ultimate metric for LLM assessment and training. It suggests that while human evaluation is crucial, it is imperative to recognize its limitations and biases. Future research should aim to mitigate these biases, possibly through improved annotation protocols or alternative objective measures that more accurately align with desired outcomes.
Conclusion
Human feedback, while useful, has limitations and should not be considered the definitive standard for evaluating LLM outputs. This research calls for more nuanced and comprehensive evaluation methods that consider the identified biases. Developing these methods is crucial for the advancement of LLM capabilities to ensure that models produce useful, reliable, and robust responses across contexts.

