- The paper presents RL4CO as a unified framework that benchmarks 27 combinatorial optimization environments with 23 state-of-the-art baselines.
- The methodology leverages advanced RL algorithms like PPO and REINFORCE combined with modular policy designs and efficient multi-device training.
- The benchmark demonstrates strong generalization and adaptability across diverse CO problems including TSP, CVRP, and PDP.
"RL4CO: An Extensive Reinforcement Learning for Combinatorial Optimization Benchmark"
Introduction
The paper "RL4CO: An Extensive Reinforcement Learning for Combinatorial Optimization Benchmark" addresses the challenges in combinatorial optimization (CO) using deep reinforcement learning (RL). The main obstacle in CO is the exponential complexity and NP-hard nature of these problems, which has traditionally been tackled through mathematical programming and heuristics. However, these methods often fall short in scalability and require significant domain-specific knowledge.
RL4CO introduces a comprehensive framework designed to unify and benchmark 27 CO environments with 23 state-of-the-art baselines, all leveraging the advantages of modular architectures and efficient training pipelines.
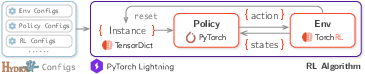
Figure 1: Overview of the RL4CO pipeline: from configurations to training a policy on an environment.
RL4CO Framework
Policy Modularization
Policies in RL4CO are divided into constructive and improvement types. Constructive policies are further categorized into autoregressive (AR) and non-autoregressive (NAR), which sequentially or globally build solutions from scratch. Improvement policies refine existing solutions either iteratively or through hybrid methods with constructive approaches.
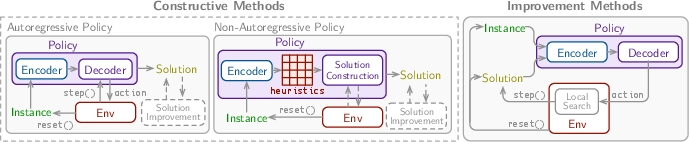
Figure 2: Overview of different types of policies and their modularization in RL4CO.
Training Algorithms
RL algorithms aim to maximize expected cumulative rewards for CO instances without labeled data requirements. Techniques such as PPO, A2C, and variations of REINFORCE provide a robust framework for optimizing neural combinatorial optimizers.
The training infrastructure uses advanced libraries, including TorchRL and PyTorch Lightning, to enable flexible multi-device training with high resource efficiency. This setup is critical to managing the computational load of training large-scale models over diversified environments.
Benchmark Studies
Evaluation Metrics
The effectiveness of RL4CO is measured using various benchmarks tasks like TSP, CVRP, PDP, and more, emphasizing metrics such as solution quality, convergence properties, and generalization to different environments.
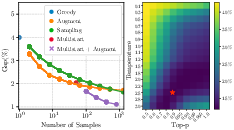
Figure 3: Study of decoding schemes using POMO on CVRP50. [Left]: Pareto front of decoding schemes by the number of samples; [Right]: sampling performance with different temperatures τ and p values for top-p sampling.
Generalization and Scalability
RL4CO demonstrates significant generalization capabilities by training models on various VRP attributes. Models like MTPOMO exhibit strong performance across different problem variants and distributions, highlighting the potential for cross-task learning and adaptability to unseen tasks.
Sampling and Decoding Techniques
The paper underscores the importance of diverse decoding schemes including sampling techniques with softmax temperature scaling and top-p sampling to enhance exploration and solution diversity. This flexibility promotes improved solution quality for complex instances.
Implementation and Community Impact
The RL4CO benchmark offers extensive documentation and tutorials to foster wider adoption and extension by the research community. It encourages contributions and is accessible for new implementations that can broaden its application scope.
Conclusion
RL4CO emerges as a vital tool for researchers and practitioners in the NCO domain, streamlining the research and benchmarking process with its modular, flexible, and extensible framework. By unifying various RL methodologies and combinatorial problem environments, RL4CO not only supports reproducibility but also accelerates innovation in developing efficient, scalable, and generalizable solution strategies for complex CO problems.

