Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks
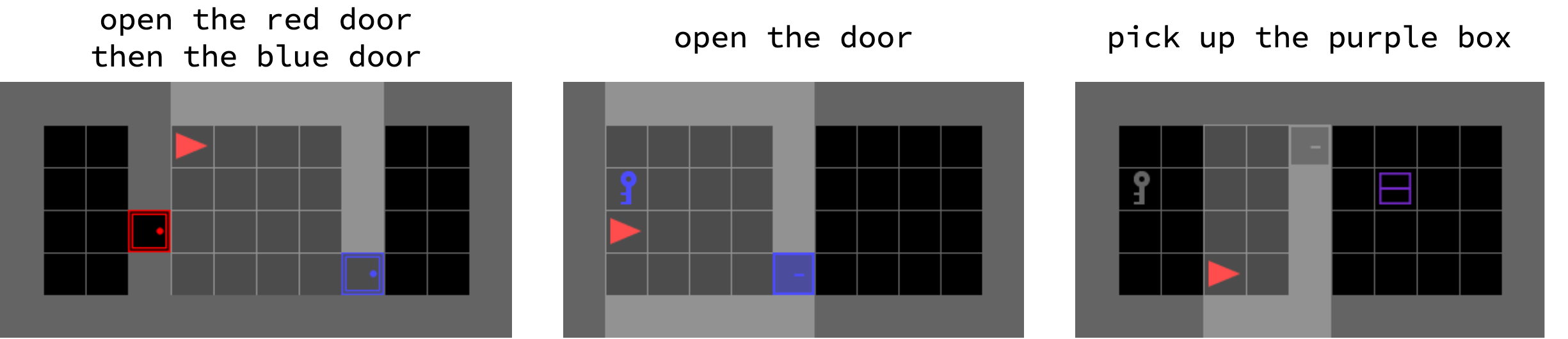
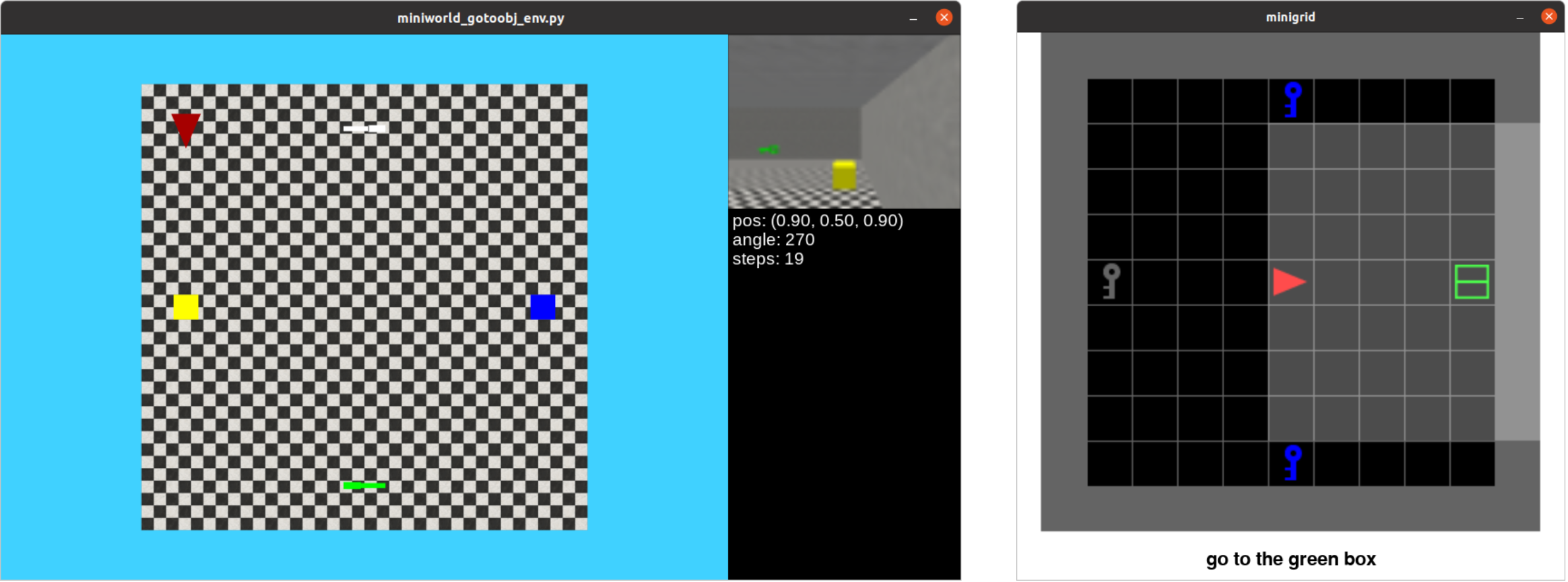
Abstract: We present the Minigrid and Miniworld libraries which provide a suite of goal-oriented 2D and 3D environments. The libraries were explicitly created with a minimalistic design paradigm to allow users to rapidly develop new environments for a wide range of research-specific needs. As a result, both have received widescale adoption by the RL community, facilitating research in a wide range of areas. In this paper, we outline the design philosophy, environment details, and their world generation API. We also showcase the additional capabilities brought by the unified API between Minigrid and Miniworld through case studies on transfer learning (for both RL agents and humans) between the different observation spaces. The source code of Minigrid and Miniworld can be found at https://github.com/Farama-Foundation/{Minigrid, Miniworld} along with their documentation at https://{minigrid, miniworld}.farama.org/.
- C. Bamford. Griddly: A platform for AI research in games. Software Impacts, 8:100066, 2021.
- DeepMind Lab. CoRR, abs/1612.03801, 2016.
- OpenAI Gym. CoRR, abs/1606.01540, 2016.
- BabyAI: A platform to study the sample efficiency of grounded language learning. In Proceedings of International Conference on Learning Representations, New Orleans, LA, May 2019.
- Emergent complexity and zero-shot transfer via unsupervised environment design. In Proceedings of Advances in Neural Information Processing Systems 33, Virtual, December 2020.
- Relay Policy Learning: Solving long-horizon tasks via imitation and reinforcement learning. In Proceedings of the Conference on Robot Learning, Virtual, pages 1025–1037, October 2020.
- R. L. Gutierrez and M. Leonetti. Information-theoretic task selection for meta-reinforcement learning. In Proceedings of Advances in Neural Information Processing Systems 33, Virtual, December 2020.
- Pre-trained word embeddings for goal-conditional transfer learning in reinforcement learning. CoRR, abs/2007.05196, 2020.
- Generalization in reinforcement learning with selective noise injection and information bottleneck. In Proceedings of Advances in Neural Information Processing Systems 32, Vancouver, Canada, pages 13956–13968, December 2019.
- Partially observable markov decision processes for artificial intelligence. In I. Wachsmuth, C.-R. Rollinger, and W. Brauer, editors, KI-95: Advances in Artificial Intelligence, pages 1–17, Berlin, Heidelberg, 1995. Springer Berlin Heidelberg. ISBN 978-3-540-44944-7.
- ViZDoom: A Doom-based AI research platform for visual reinforcement learning. In Proceedings of IEEE Conference on Computational Intelligence and Games, Santorini, Greece, pages 1–8. IEEE, September 2016.
- Decoupling exploration and exploitation for meta-reinforcement learning without sacrifices. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, volume 139, pages 6925–6935. PMLR, July 2021.
- Isaac Gym: High performance GPU based physics simulation for robot learning. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Virtual, December 2021.
- How to stay curious while avoiding noisy tvs using aleatoric uncertainty estimation. In Proceedings of International Conference on Machine Learning, Baltimore, MD, volume 162, pages 15220–15240. PMLR, July 2022.
- Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
- Evolving curricula with regret-based environment design. In Proceedings of International Conference on Machine Learning, Baltimore, MD, volume 162, pages 17473–17498. PMLR, July 2022.
- Pytorch: An imperative style, high-performance deep learning library. In Proceedings of Advances in Neural Information Processing Systems 32, Vancouver, Canada, pages 8024–8035, December 2019.
- Real-world robot learning with masked visual pre-training. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, pages 416–426, 2022.
- Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22:268:1–268:8, 2021.
- Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017.
- State entropy maximization with random encoders for efficient exploration. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, volume 139, pages 9443–9454. PMLR, July 2021.
- Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016.
- Mastering chess and shogi by self-play with a general reinforcement learning algorithm. CoRR, abs/1712.01815, 2017.
- Mazebase: A sandbox for learning from games. CoRR, abs/1511.07401, 2015.
- Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 1998.
- MuJoCo: A physics engine for model-based control. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, pages 5026–5033, October 2012.
- dm_control: Software and tasks for continuous control. Software Impacts, 6:100022, 2020.
- Safe policy optimization with local generalized linear function approximations. In Proceedings of Advances in Neural Information Processing Systems 34, Virtual, pages 20759–20771, December 2021.
- Noveld: A simple yet effective exploration criterion. In Proceedings of Advances in Neural Information Processing Systems 34, Virtual, pages 25217–25230, December 2021.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.