- The paper introduces a decoupled framework that separates video instance segmentation into independent tasks: segmentation, tracking using a referring cross-attention mechanism, and temporal refinement.
- It utilizes a lightweight referring tracker and temporal refiner to efficiently optimize object association and long-term context, yielding state-of-the-art performance on challenging benchmarks.
- DVIS demonstrates improved computational efficiency, enabling robust video analysis on hardware with limited resources while addressing complex, occluded, and dynamic scenes.
DVIS: Decoupled Video Instance Segmentation Framework
The paper "DVIS: Decoupled Video Instance Segmentation Framework" (2306.03413) presents a novel approach for addressing video instance segmentation (VIS), focusing on complex and extended video sequences often encountered in real-world scenarios. The authors propose a decoupling strategy that divides VIS into three independent sub-tasks: segmentation, tracking, and refinement, each of which is handled by separate components in the DVIS framework.
Introduction
VIS involves the simultaneous identification, segmentation, and tracking of instances in video sequences. Traditional VIS models face challenges such as occlusion, complex scene dynamics, and object deformation over time. Previous approaches mainly relied on tightly-coupled networks that often resulted in noisy long-term temporal alignment and inefficient use of temporal information. DVIS aims to overcome these issues by leveraging decoupled components with specialized tasks.
Methodology
Decoupled Framework
The DVIS framework divides the VIS task into segmentation, tracking, and refinement. Segmentation extracts object representations from individual frames, tracking links objects between adjacent frames, and refinement utilizes temporal information to optimize the segmentation and association results. This decoupling strategy allows each component to be optimized separately and efficiently.
Referring Tracker
The referring tracker in DVIS uses Referring Cross Attention (RCA) for robust frame-by-frame object association, addressing the first sub-task: tracking. RCA introduces identification to prevent the blending of adjacent frame representations while exploiting their similarity for improved association.
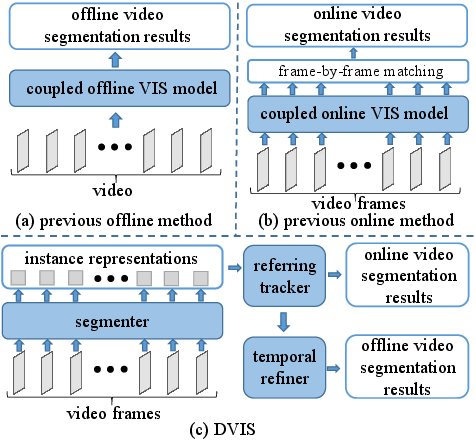
Figure 1: Pipelines of previous offline (a), online (b), and proposed DVIS (c) frameworks. Unlike previous methods that rely on tightly coupled networks, DVIS consists of independent components, including a segmenter, a referring tracker, and a temporal refiner.
Temporal Refiner
For the refinement sub-task, the temporal refiner aggregates information across the video using components like 1D convolution for motion extraction and self-attention for long-term context utilization.
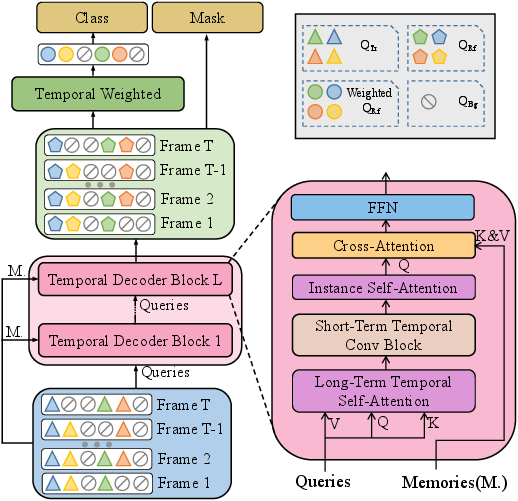
Figure 2: The framework of the temporal refiner. Instance representations for each frame (QRf) are denoted by pentagons, while the instance representations for the entire video (Q^Rf) are denoted by circles.
Experimental Results
DVIS demonstrates superior performance across challenging VIS benchmarks such as OVIS, YouTube-VIS 2019, 2021, and 2022. In both online and offline modes, DVIS achieves state-of-the-art (SOTA) performance, outperforming previous methods like IDOL, MinVIS, and MaskTrack R-CNN by significant margins. The framework shows notable gains, especially in scenarios with complex and occluded objects.


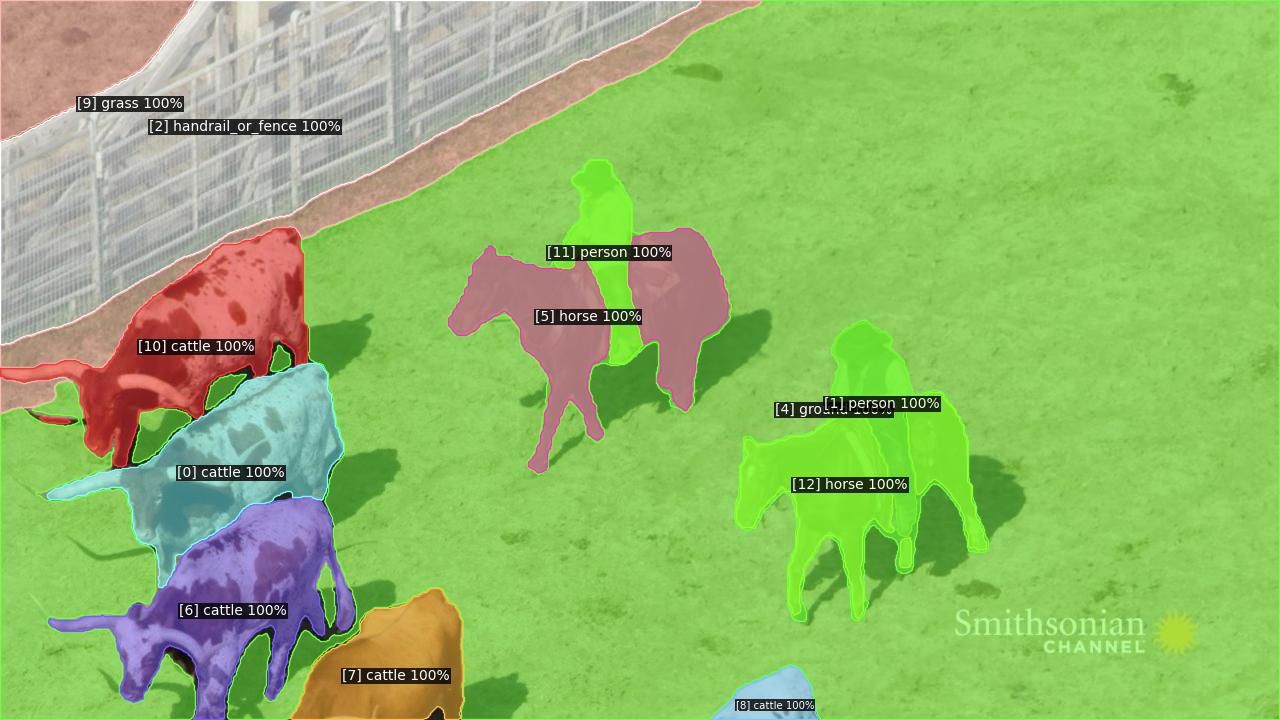

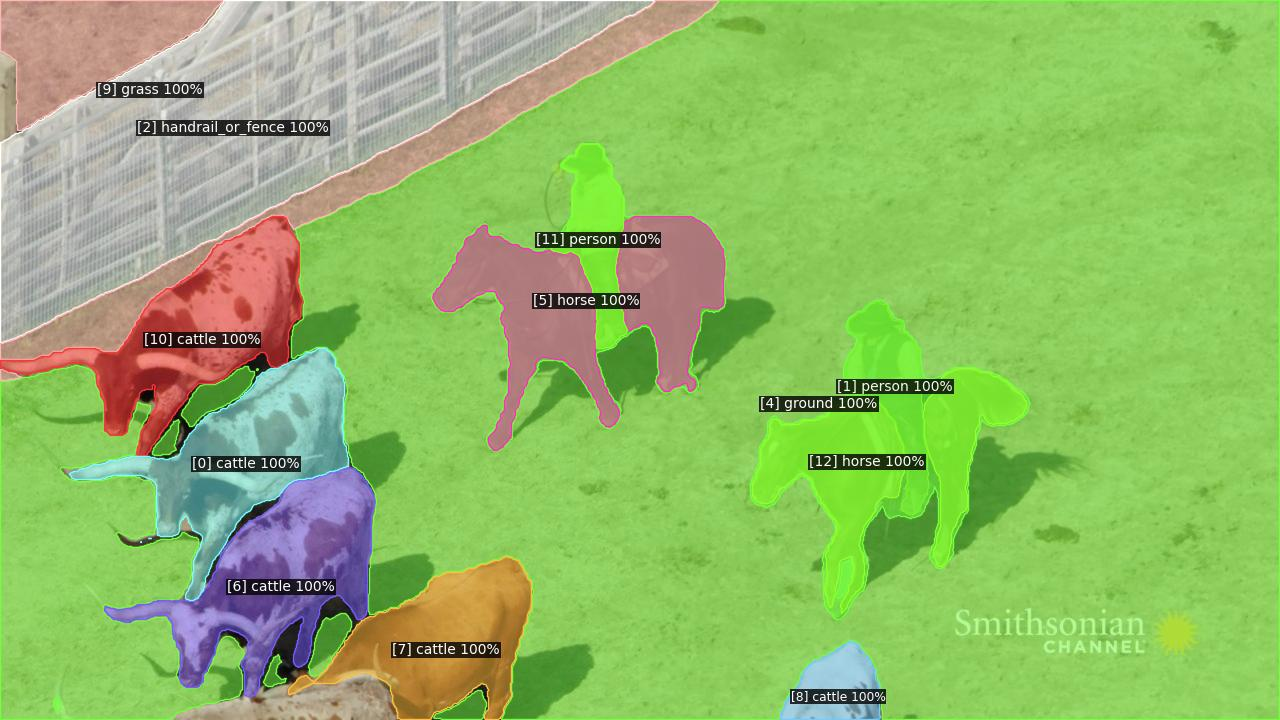


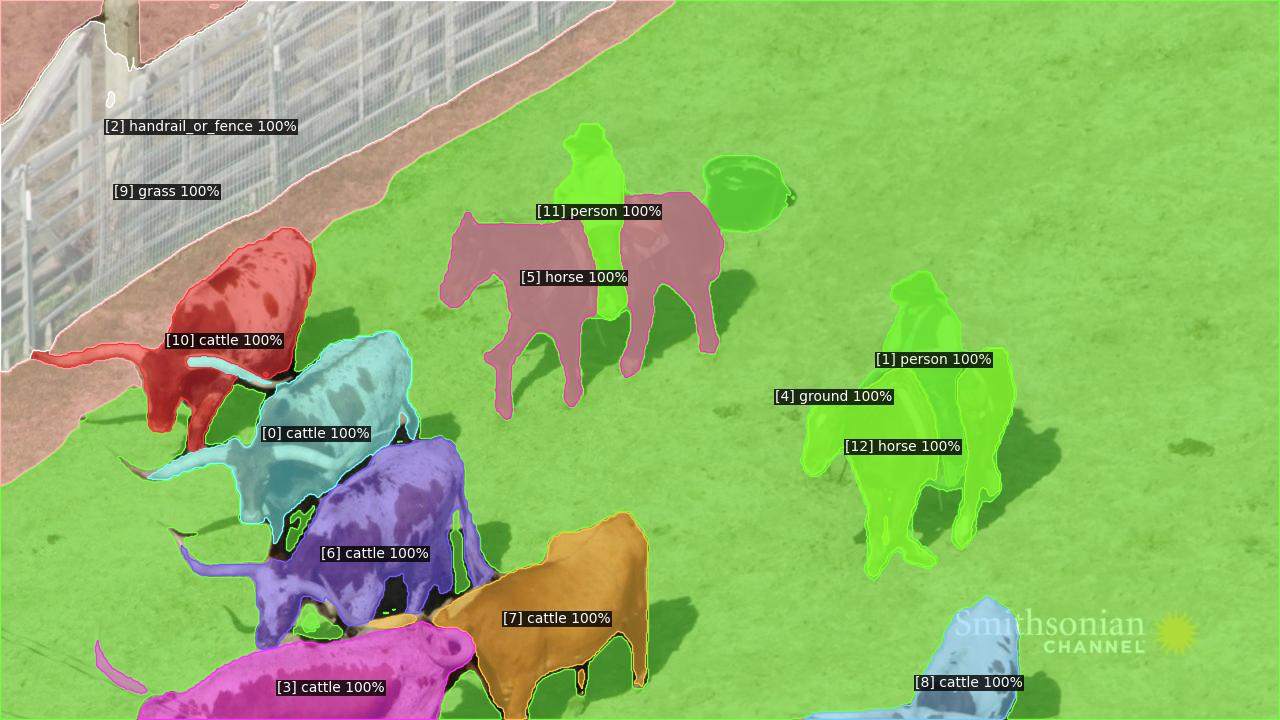




Figure 3: Visualization results obtained on the OVIS dataset.
Implementation Considerations
DVIS achieves its performance gains with minimal computational overhead. The referring tracker and temporal refiner use lightweight operations that account for only a fraction of the computational cost compared to the segmentation network. This allows training and inference to be efficiently performed on hardware with limited resources, such as a single GPU with 11G memory.
Conclusion
The DVIS framework offers a robust solution to the challenges of VIS in dynamic and complex video scenarios by decoupling essential tasks into specialized modules. The framework's modularity allows for flexible adaption to other tasks like video panoptic segmentation (VPS) without modification, suggesting a versatile applicability in different video analysis domains. The decoupling strategy and independent optimization of tasks could inspire further advancements in both online and offline video analysis methods. As future work, addressing real-world scenarios with potentially infinite video lengths and instances remains a promising direction.