- The paper challenges the impossibility theorem by introducing an epsilon margin-of-error, broadening the set of fair models.
- It analytically characterizes fairness regions using relaxed constraints on FNR, FPR, and PPV, demonstrating the feasibility of multi-metric parity.
- Empirical results from diverse datasets show that modest relaxations enable equitable predictions with minimal impact on model performance.
Revisiting the Impossibility Theorem in Algorithmic Fairness
Introduction
The paper "The Possibility of Fairness: Revisiting the Impossibility Theorem in Practice" (2302.06347) reevaluates the theoretical concept of the "impossibility theorem" within the context of algorithmic fairness. The impossibility theorem traditionally asserts that a trade-off between fairness and model performance is inevitable, barring circumstances where outcome prevalence is equal across groups or when a perfectly accurate predictor is utilized. However, this paper challenges these theoretical constraints and posits that they may not directly apply to real-world applications.
The authors argue that by adopting a more pragmatic approach to fairness—allowing a small margin-of-error across different metrics—practitioners can identify a wider range of models that meet seemingly incompatible fairness constraints. This assertion is backed by analytical derivations and empirical experiments on various datasets, suggesting that achieving fairness across multiple metrics is more attainable than previously recognized.
Analytical Insights and Implications
Relaxing Fairness Constraints
The authors propose relaxing the impossibility theorem constraints by introducing a margin-of-error, denoted as ϵ, for each fairness metric. Specifically, practitioners are allowed to relax the constraints of False Negative Rate (FNR) Parity, False Positive Rate (FPR) Parity, and Positive Predictive Value (PPV) Parity by ϵ across groups. This relaxation results in a large set of feasible models that maintain parity across multiple fairness metrics, even when the prevalence differs moderately between groups.
Characterizing the Fairness Region
Theoretical analysis reveals that for given group prevalences, allowing an ϵ relaxations leads to a substantial fairness region where multiple models can satisfy the fairness constraints. This region can be analytically characterized using closed-form expressions, which are particularly feasible for combinations of metrics like FNR, FPR, and accuracy (ACC).
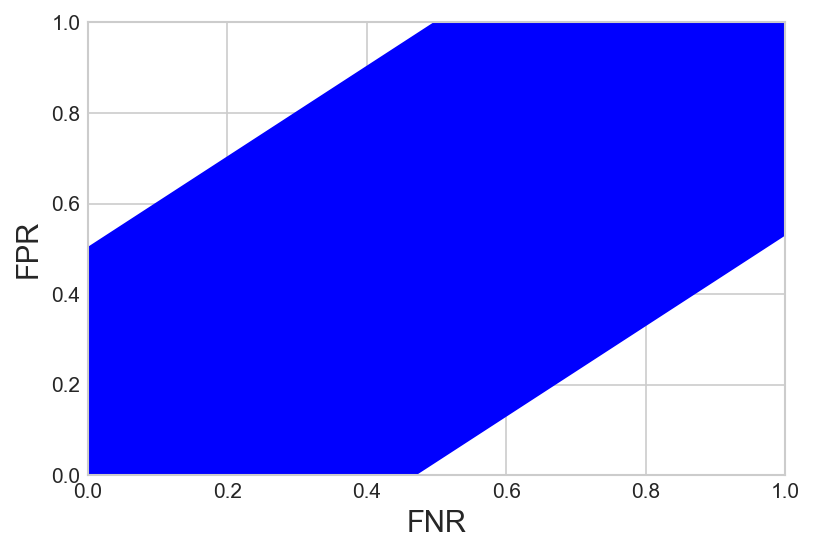
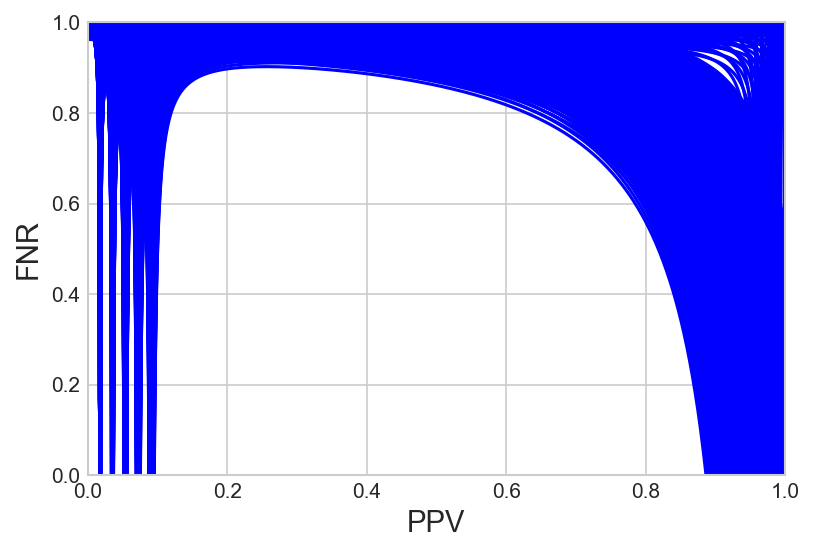
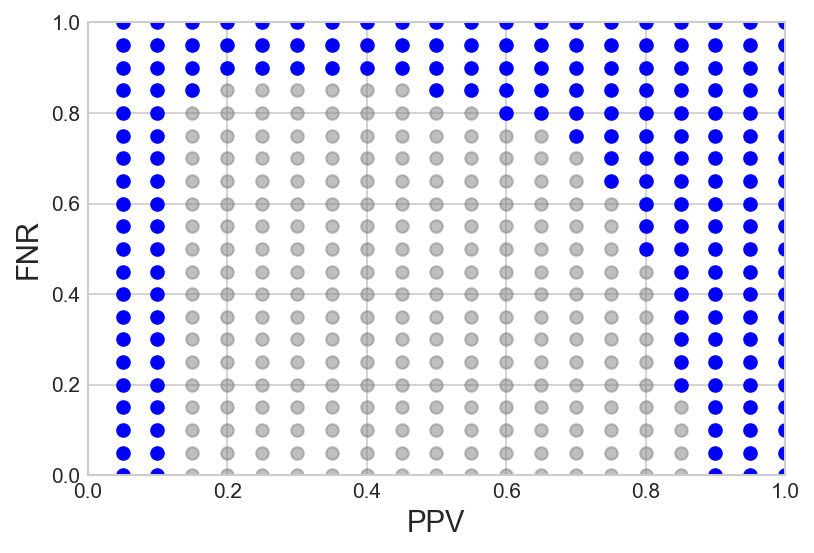
Figure 1: p_1 = 0.3, p_2 = 0.5; $\epsilon_\fpr$, $\epsilon_\fnr$, $\epsilon_\acc \in \lbrack -0.05,0.05 \rbrack$.
Practical Considerations
The implications extend beyond theoretical derivations. Specifically, the research emphasizes the role of prevalence proximity to 50%, classifier performance (\ppv), and resource constraints (\rc) in determining the possibility of fairness. Particularly, a higher \ppv or reduced \rc can increase the likelihood of discovering fair models, even when there is a prevalence difference of up to 10% or 20%.
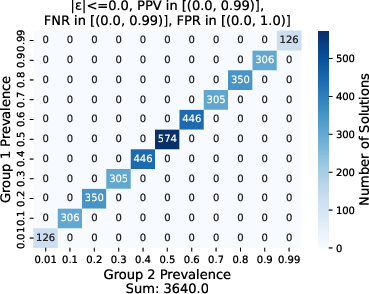
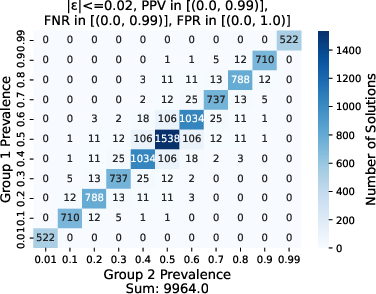
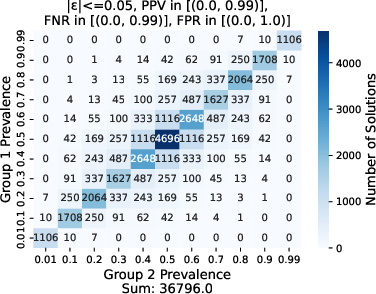

Figure 2: Effect of varying group prevalences prev_1, \prev_2 on the number of feasible models for different values of epsilon, where ppv, \fnr \in \lbrack 0, 0.99 \rbrack, \fpr \in \lbrack 0, 1.0 \rbrack, N=100.
Empirical Validation
Through extensive experiments on five real-world datasets—comprising outcomes from health, finance, and educational domains—the paper substantiates its theoretical propositions. The findings suggest that in most cases, there does exist a set of observations that satisfy the fairness constraints without sacrificing PPV. Such favorable results underline the practical feasibility of achieving fairness across multiple metrics, refuting the rigid barriers implied by the traditional impossibility theorem.
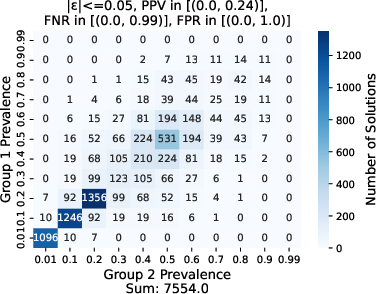
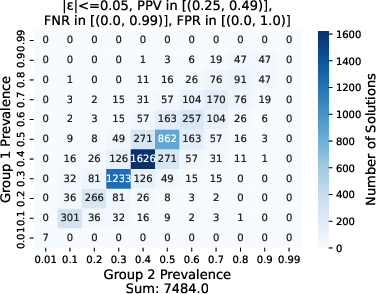
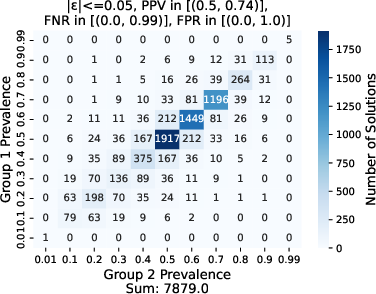
Figure 3: Effect of varying \ppv on the fairness region, where ∣ϵα∣, ∣ϵβ∣, ∣ϵv∣≤0.05, N=100.
Conclusion
The paper challenges existing boundaries posed by the impossibility theorem and presents compelling evidence that achieving fairness across multiple metrics is indeed feasible in practical settings. By slightly relaxing fairness constraints, larger sets of models become available, allowing practitioners to balance accuracy and fairness effectively.
The ongoing discourse on algorithmic fairness should, therefore, incorporate these findings, leveraging the nuanced understanding of fairness regions to push beyond theoretical limitations. Further research could explore practical methods for model selection within these fairness regions, and how intersectional group considerations may alter these dynamics.
Ultimately, the work reshapes the narrative around algorithmic fairness, suggesting that once perceived insurmountable constraints can often be navigated through informed relaxations. This aligns with the broader objective of fostering equitable AI systems that prioritize ethical and responsible use in varied societal contexts.