- The paper presents a comprehensive synthesis of over 1000 NAS publications, classifying search spaces, strategies, and performance estimation methods.
- It evaluates key methods including evolutionary algorithms, reinforcement learning, and one-shot approaches, highlighting their trade-offs and limitations.
- The paper advocates for standardized benchmarks and reproducible best practices while outlining future directions for automated deep learning pipelines.
Neural Architecture Search: Insights from 1000 Papers
Introduction and Motivation
Neural Architecture Search (NAS) has become a central paradigm in automating the design of neural networks, with the goal of discovering high-performing architectures for a given task and resource budget. The surveyed paper provides a comprehensive synthesis of over 1000 NAS publications, organizing the field along the axes of search spaces, search strategies, and performance estimation techniques. The authors emphasize the rapid evolution of NAS, its impact across domains (vision, language, speech, RL, tabular data), and the necessity for systematic benchmarking and best practices.
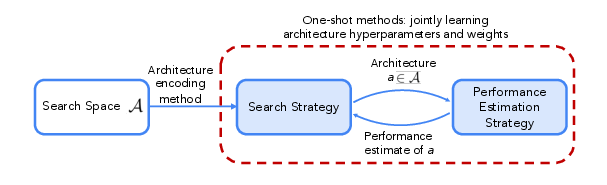
Figure 1: Overview of neural architecture search, illustrating the interaction between search strategy, search space, and performance estimation.
Taxonomy of NAS: Search Spaces
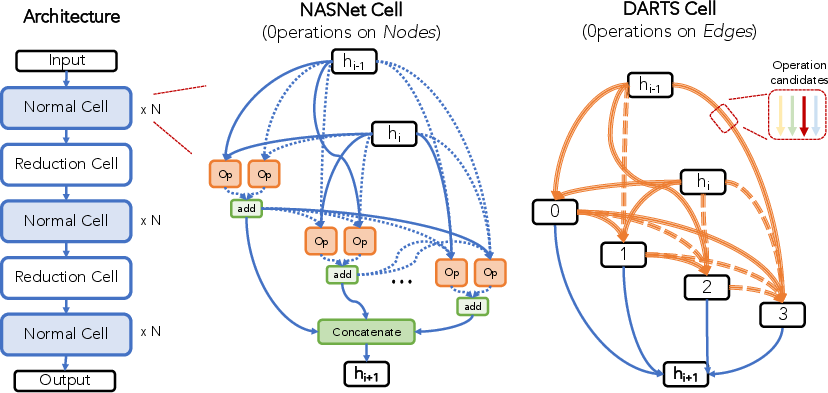
The search space is the foundational component of any NAS system, dictating the set of candidate architectures. The paper delineates several canonical search space types:
The paper also discusses architecture encoding schemes (adjacency matrices, path-based, learned representations), highlighting their impact on the efficiency and generalizability of NAS algorithms.
Search Strategies: Black-Box and One-Shot Methods
Black-Box Optimization
Traditional NAS methods treat architecture evaluation as a black-box function, employing:
- Random Search: Surprisingly competitive in highly engineered search spaces, but suboptimal in large, diverse spaces.
- Reinforcement Learning (RL): Early NAS successes (e.g., Zoph & Le) used RL controllers, but these approaches are now largely outperformed by evolutionary and BO methods.
- Evolutionary Algorithms: Population-based search with mutation and selection, offering robustness and flexibility. Regularized evolution has demonstrated strong empirical results.
- Bayesian Optimization (BO): Surrogate modeling of architecture performance, with acquisition functions guiding exploration/exploitation. BO is effective but challenged by high-dimensional, discrete, and graph-structured spaces.
- Monte Carlo Tree Search (MCTS): Tree-based exploration, particularly effective in modular or hierarchical search spaces.
One-Shot and Weight-Sharing Methods
To address the prohibitive cost of black-box NAS, one-shot methods train a supernet or hypernetwork encompassing all candidate architectures, enabling rapid evaluation via weight sharing.
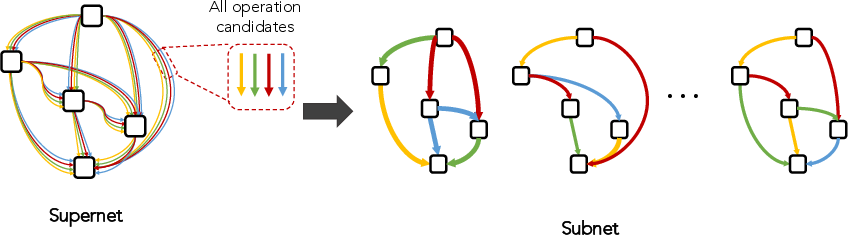
Figure 3: A supernet contains all possible architectures in the search space as subnetworks.
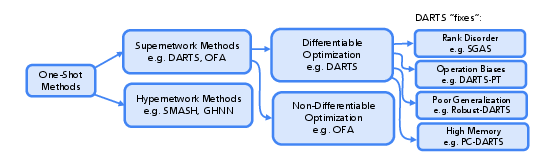
Figure 4: Taxonomy of one-shot NAS families, including supernet and hypernetwork approaches.
- Non-Differentiable Supernet Methods: Supernet is trained, then black-box search (random, evolutionary) is performed over subnetworks.
- Differentiable NAS (e.g., DARTS): The search space is relaxed to be continuous, allowing gradient-based optimization of architecture parameters alongside weights. After optimization, the architecture is discretized and retrained.
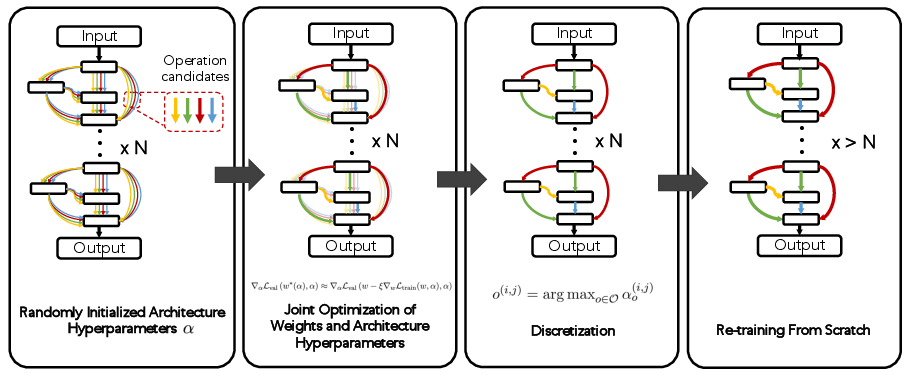
Figure 5: Differentiable one-shot NAS workflow: initialization, alternating optimization, discretization, and retraining.
- Hypernetworks: Networks that generate weights for candidate architectures, enabling rapid performance estimation.
The paper critically examines the assumptions and limitations of weight-sharing, including rank disorder, operation bias (e.g., over-selection of skip connections), poor test generalization, and high memory consumption. Numerous variants (e.g., Progressive-DARTS, ProxylessNAS, GDAS, PC-DARTS) address these issues via progressive pruning, stochastic masking, and memory-efficient channel sampling.
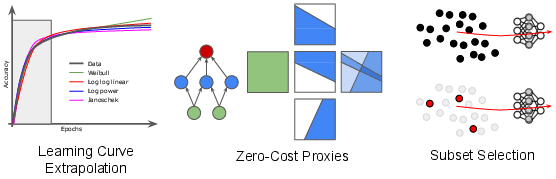
Given the high cost of full training, NAS research has developed a suite of performance prediction and speedup techniques:
Extensions: Joint NAS+HPO, Constraints, Ensembles
The paper highlights the importance of joint optimization of architectures and hyperparameters (NAS+HPO), noting that hyperparameter tuning can yield larger gains than architecture search alone in some search spaces. The complexity of the joint space necessitates specialized algorithms and representations.
Constrained and multi-objective NAS is addressed via penalty-based or Pareto-based optimization, targeting metrics such as latency, memory, and fairness. Hardware-aware NAS is a major subfield, with surrogate models for device-specific metrics.
Neural ensemble search extends NAS to discover diverse sets of architectures for improved accuracy, calibration, and robustness, but at increased computational cost.
Applications Across Domains
NAS has been successfully applied beyond image classification, including:
- Graph Neural Networks: Custom search spaces and strategies for GNNs.
- Generative Adversarial Networks: Joint or separate search for generator/discriminator architectures.
- Dense Prediction: Semantic segmentation, object detection, and related tasks, often requiring multi-stage or modular search spaces.
- Transformers: NAS for encoder, decoder, and hybrid transformer architectures in NLP and vision, with no consensus on optimal search space design.
Benchmarks, Best Practices, and Resources
The proliferation of queryable NAS benchmarks (e.g., NAS-Bench-101/201, NATS-Bench, NAS-Bench-301, TransNAS-Bench-101) has enabled reproducible, statistically significant comparisons and rapid prototyping. The paper advocates for rigorous best practices: releasing code, fixing random seeds, using standardized benchmarks, reporting ablations, and running multiple trials.
A variety of open-source libraries (NASLib, Archai, PyGlove, Auto-Keras, NNI) and survey resources are cataloged, supporting both research and practical deployment.
Future Directions
The authors identify several open challenges and promising directions:
- Robustness and Generalization of One-Shot Methods: Despite efficiency, one-shot NAS methods remain sensitive to search space design and training heuristics. Large-scale, fair comparisons and more robust algorithms are needed.
- Automated, Flexible Search Spaces: Moving beyond hand-crafted, rigid spaces to hierarchical or automatically pruned spaces could reduce human bias and enable discovery of novel architectures.
- Fully Automated Deep Learning Pipelines: Integrating NAS with HPO, data augmentation, and deployment (AutoDL) is a long-term goal, with the potential for substantial real-world impact.
Conclusion
This survey provides a comprehensive, systematic overview of the NAS literature, distilling key insights from over 1000 papers. The field has matured rapidly, with advances in search spaces, algorithms, performance estimation, and benchmarking. However, significant challenges remain in robustness, generalizability, and automation. The trajectory of NAS research suggests continued integration with broader AutoML and AutoDL efforts, with implications for both theoretical understanding and practical deployment of neural networks across diverse domains.